In the English language, the character a appears much more often in words and sentences than the character x. Similarly, we can also observe that the word is occurs more frequently than the word specimen. It is possible to learn the probability distributions of characters and words by examining large volumes of text. The following screenshot is a chart showing the probability distribution of letters given a corpus (text dataset):
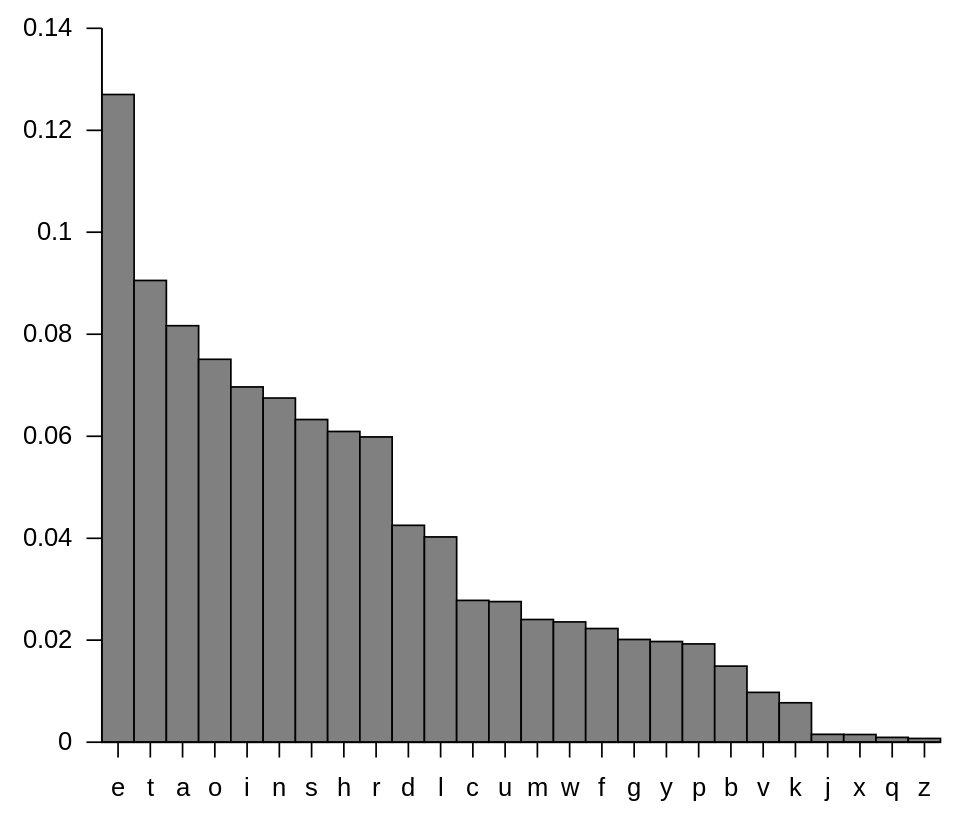
Probability distribution of letters in a corpus
We can observe that the probability distributions of characters are non-uniform. This essentially means that we can recover the characters ...

