Chapter 5. Apache Beam Implementation
Beam is an open source, unified model for defining both batch and streaming processing pipelines. It is not a stream processing engine (SPE), but rather an SDK with which you can build a pipeline definition that can be executed by one of Beam’s supported distributed processing backends. Using Beam, you can do the following:
-
Use a single programming model for both batch and streaming use cases.
-
Through separation of building and execution, you can use the same Beam pipelines on multiple execution environments.
-
Write and share new SDKs, IO connectors, and transformation libraries, regardless of the specific runner.
Let’s take a look at how you can use Beam’s semantics to implement our solution.
Overall Architecture
Beam provides very rich execution semantics for stream merging including CoGroupByKey and Combine. It also supports side inputs for bringing calculations on one stream as an input for processing in another stream. Unfortunately, all of these APIs are designed for windowed streams and do not work for the global windows—this is the problem that I am trying to solve.
The only option that I have found is using Flatten, which allows you to merge multiple streams into one. Combining this with the state feature used to store a model provides a reasonable approach for overall implementation, as shown in Figure 5-1.
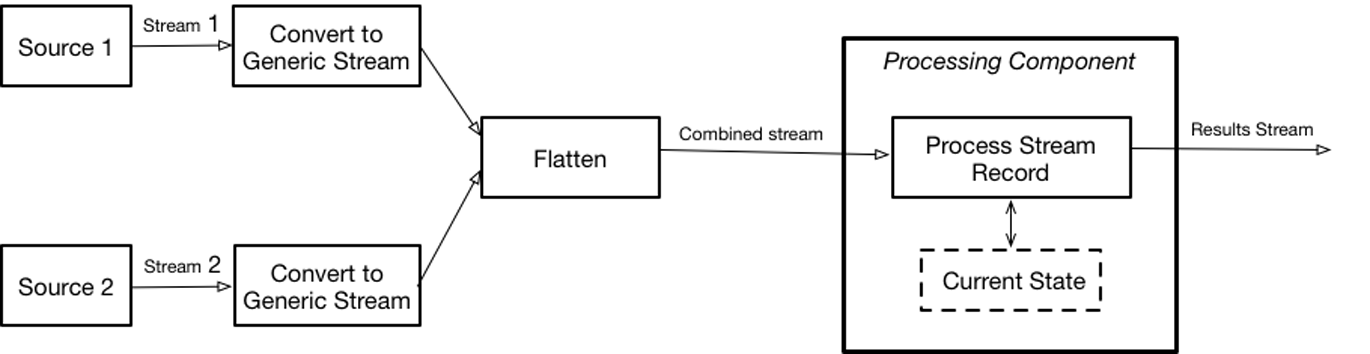
Figure 5-1.
Get Serving Machine Learning Models now with the O’Reilly learning platform.
O’Reilly members experience books, live events, courses curated by job role, and more from O’Reilly and nearly 200 top publishers.

