


O’Reilly online learning is a trove of information about the trends, topics, and issues tech leaders need to know about to do their jobs. We use it as a data source for our annual platform analysis, and we’re using it as the basis for this report, where we take a close look at the most-used and most-searched topics in machine learning (ML) and artificial intelligence (AI) on O’Reilly[1].
Our analysis of ML- and AI-related data from the O’Reilly online learning platform indicates:
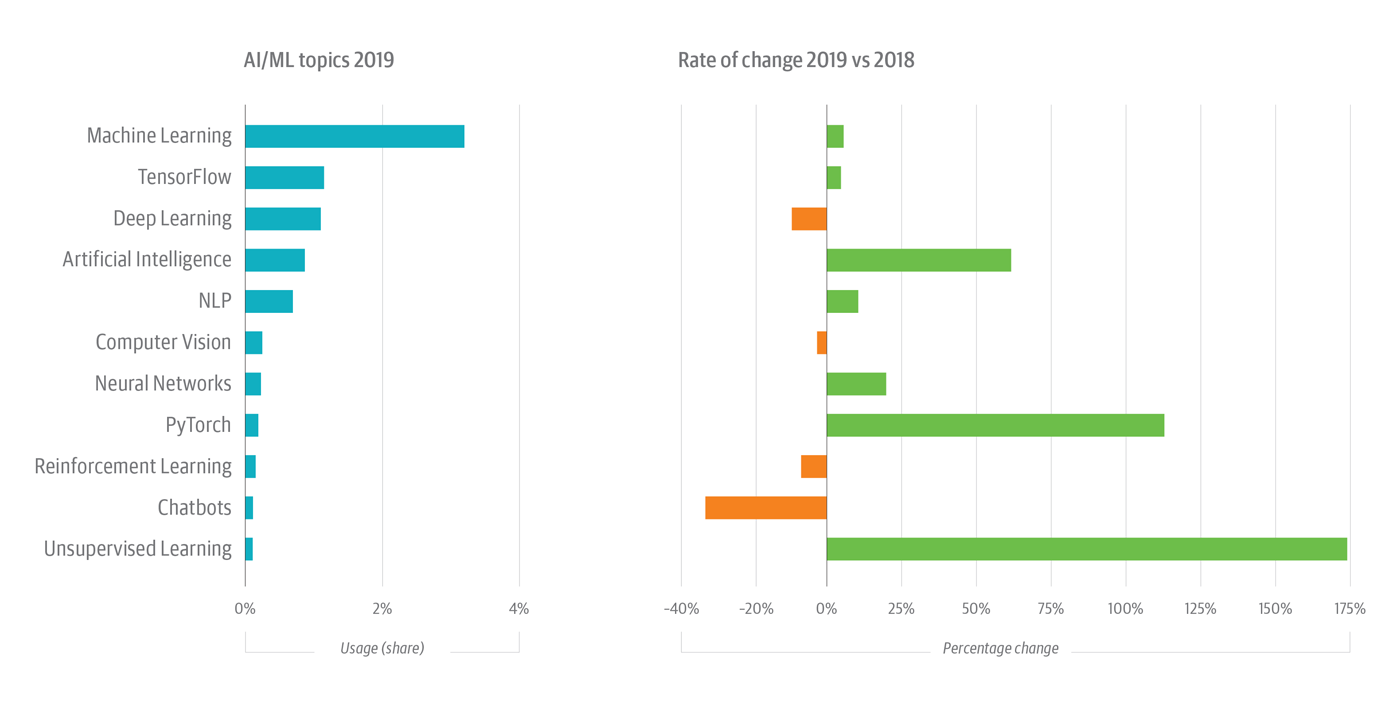
- Unsupervised learning surged in 2019, with usage up by 172%.
- Deep learning cooled slightly in 2019, slipping 10% relative to 2018, but deep learning still accounted for 22% of all AI/ML usage.
- Although TensorFlow grew by just 3%, it, too, garnered 22% share of AI/ML usage in 2019.
- PyTorch looks like a contender: it posted triple-digit growth in usage share rates in both 2018 and 2019.
- Reinforcement learning fell by 5% in 2019; it’s up hugely—1,500+%—since 2017, however.
- Sustained strength in unsupervised learning, neural networks, reinforcement learning, etc., demonstrates that organizations are experimenting with advanced ML tools and methods.
Growth in ML and AI is unabated
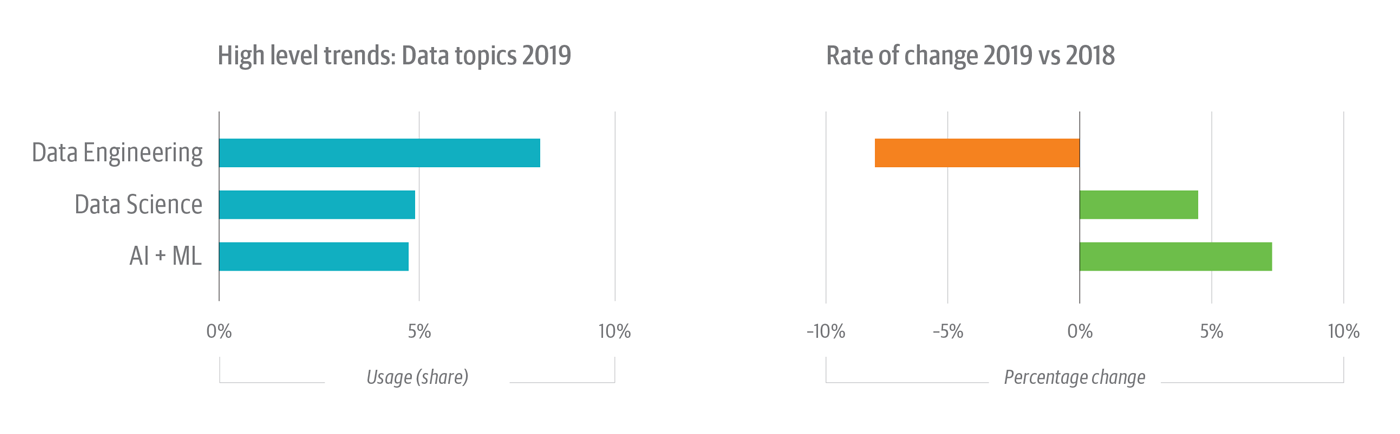
Engagement with the artificial intelligence topic continues to grow, up 88% in 2018 and 58% in 2019 (see Figure 1), outpacing share growth in the much larger machine learning topic (+14% in 2018, up 5% in 2019). Aggregating artificial intelligence and machine learning topics accounts for nearly 5% of all usage activity on the platform, a touch less than, and growing 50% faster than, the well-established “data science” topic (see Figure 2).
Data engineering remains the largest topic in the data category with just over 8% usage share on the platform (Figure 2). But the data engineering share is down about 8% in 2019, mostly from declines in engagement with data management topics.
Unsupervised learning is growing
Interest in the unsupervised learning topic increased significantly, with usage up by 53% in 2018 and by 172% in 2019[2] (see Figure 1). What’s driving this growth?
First, for most people and most use cases, supervised learning serves as the default, assumed strategy for machine learning. That makes unsupervised learning worth noting as a separate topic, given the growth in engagement driven by more sophisticated users, improved tools, and use cases not easily addressed with supervised methods. By analogy, users are more apt to engage with specific supervised learning methods—e.g., linear and logistic regressions, support vector machines—than with the canonical topic of supervised learning itself.
Unsupervised learning, by contrast, isn’t as well understood, even if the names of its methods—e.g., clustering and association—and its applications (neural networks) are familiar to many users.
In all likelihood, the surge in unsupervised learning activity on O’Reilly is being driven by a lack of familiarity with the term itself, as well as with its uses, benefits, requirements, etc. It’s likely, too, that the visible success of unsupervised learning in neural networks and deep learning[3] has helped spur interest, as has the diversity of open source tools, libraries, tutorials, etc., that support unsupervised learning. That some of these tools (scikit-learn, PyTorch, and TensorFlow) are also Python-based doesn’t hurt, either.
Usage in advanced techniques is up—mostly
It’s said that the success of neural networks and, especially, deep learning—neither of which is new—helped spur the resurrection of a number of other disused or neglected ideas.
One example is reinforcement learning, which experienced an exponential spike in usage on the O’Reilly platform in 2018—growing by 1,612%—before regressing slightly (-5%) in 2019 (see Figure 1).
Looking at AI/ML topic detail, we see usage in neural networks continuing its upward trend—up 52% in 2018; up 17% in 2019—but the related topic of deep learning dropped 10% in 2019. The drop in deep learning seems likely a function of inter-year noise and not evidence of an emerging trend, given the significant usage growth in 2018 (+52%). These closely related topics are popular: aggregating neural networks, deep learning, and TensorFlow usage nets nearly half (47%) of all AI/ML category usage, showing a slight decline (-3%) in 2019 after growing 24% in 2018.
In our “AI adoption in the enterprise 2020” survey, we found that deep learning was the most popular ML method among companies that are evaluating AI. Among companies using AI to support production use cases, deep learning was No. 2[4]. It might be that—at 1% of platform usage and 22% of all AI/ML usage—deep learning has approached its asymptote. Growth could be slow from here on out.
The rising AI/ML tide lifts (almost) all boats
Another topic showing consistent growth is natural language processing (NLP) (see Figure 1). Its growth rate isn’t spectacular—+15% in 2018, +9% in 2019—but NLP now accounts for about 12% of all AI/ML usage on O’Reilly. That’s about 6x the share of unsupervised learning and 5x the share of reinforcement learning usage.
Interest in some methods or applications of ML seems to be waning, however. For example, the chatbots topic continues to decline, first by 17% in 2018 and by 34% in 2019. This is probably a reflection of the comparative maturity of the space. The chatbot was one of the first applications of AI in experimental and production usage. This likely doesn’t portend the end of interactions with occasionally helpful—and still sometimes horrifying—customer service chatbots.
Computer vision usage shows a slow decline, falling by 3% in 2018 and 2% in 2019. Probably more noise than trend, moreover, computer vision accounts for about twice as much usage activity as the fast growing unsupervised learning topic.
Python-based tools are ascendant in AI/ML
Reports of Torch’s death are somewhat misleading. In fact, PyTorch—a wrapper that permits users to call Torch’s ML libraries from Python—posted triple-digit growth in usage in just the last few years, surging by almost 400% in 2018 and by 111% in 2019 (see Figure 1). PyTorch’s popularity is probably a function of the success of Python itself, particularly for ML and AI: vanilla Torch uses Lua as a wrapper to expose its core C libraries; PyTorch eschews Lua (in favor of Python) for the same purpose.
Once you factor in the preeminence of Python, the rising popularity of PyTorch makes a lot of sense.
This may have something to do with TensorFlow’s outsized presence in ML, too. In 2019, it accounted for 1% of all usage, about a third as much usage as machine learning and 22% of all AI/ML usage. TensorFlow isn’t a Python-exclusive technology—it exposes stable C and Python APIs[5]—but its users tend to be Python-savvy and its related projects, patterns, tutorials, etc., disproportionately involve Python.
The results of our recent AI adoption survey underscore this trend. TensorFlow was also the No. 1 ML technology in the survey, while PyTorch came in at No. 4. Two additional Python-based tools (scikit-learn and Keras) also cracked the top five[6]. We know from our annual analysis of usage and search on the O’Reilly online learning platform that one of Python’s fastest areas of growth is in ML- and AI-related development. The prominence of these and other Python-related tools attests to this fact.
What’s in a name? The shift to “artificial intelligence”
Does the growing engagement in neural networks, reinforcement learning, unsupervised learning, and the increased focus on putting models into production augur a shift in how practitioners in the space frame what they do? We think yes, with practitioners increasingly calling their work “artificial intelligence”—a notion supported by the growth in AI usage on O’Reilly, the increasing embrace of sophisticated tools, and the empirical trend of putting those tools into production, which we see in our AI surveys.
AI has always been the general term for building intelligent systems, with machine learning covering the more specific case of building software that learns and modifies its outputs without the need for additional coding. Here are some examples of what, when viewed in aggregate, helps explain why those in the space think machine learning doesn’t quite cover all they do:
- Machine learning produces models that are widely used in the automation of tasks such as credit scoring, fraud detection, recommendation engines, etc., but ML models are increasingly deployed in libraries or services and exposed via APIs—such that a model or ensemble of models can be invoked by any valid user, program, or service.
- To some extent, models can be built with an aim toward reuse, such that, for example, a data profiling model can be invoked and used to support different business use cases.
- Tools and techniques like reinforcement learning and unsupervised learning open up new use cases, including decision support, interactive games, real-time retail recommendation engines, and data discovery.
- The focus of usage—and, with it, design and development—is shifting from the specific to the generalized. ML libraries and services have the potential to transform the software products we deliver, the processes that consume them, and—concomitant with this—the experiences of users, customers, partners, etc., alike.
- This isn’t just ML; it’s a kind of AI: a new way of thinking about and applying machine intelligence. It has implications for software architecture, infrastructure, and operations—for virtually all domains.
So, this isn’t artificial general intelligence, but AI as the application of machine learning to solve problems, increase productivity, accelerate processes, and in many cases deliver wholly new products and services.
Concluding thoughts
As organizations adopt analytic technologies, they’re discovering more about themselves and their worlds. Adoption of ML, especially, prompts people at all levels of an organization to start asking questions that challenge in different ways what the organization thinks it knows about itself.
An organization’s use of ML tools and techniques, and the contexts in which it uses them, will tend to change, too. For example, the techniques of supervised learning are useful for classifying known-knowns and for elucidating certain kinds of known-unknowns; they’re unsuitable for surfacing unknown-unknowns, however. Unsupervised techniques are better for this. Not for classifying, synthesizing, or understanding unknown-unknowns—that’s the responsibility of human intelligence—but for surfacing them in the first place. The upshot is that adopters are integrating both kinds of learning into their ML practices. They’re also apt to experiment with advanced ML methods—such as deep learning—that have applications for both supervised and unsupervised learning. In fact, we found in our AI adoption survey that those new to ML are almost as likely to experiment with deep learning as mature adopters.
Right now, companies are successfully using ML to ferret out known-unknowns and unknown-unknowns in their business worlds. They’re instantiating what they discover, analyze, and understand about their worlds in models. Some are also starting to incorporate these models into automated, quasi-intelligent products, services, and software. All of this partakes of the propulsive logic of self-discovery. It’s at the root of a question Plato first formulated almost 2,500 years ago: “But how will you look for something when you don’t in the least know what it is?” he has Meno ask Socrates. “How on earth are you going to set up something you don’t know as the object of your search?”
Philosophical tradition treats this question as a paradox. It’s also possible to see it as an inquiry into how an object of knowledge augments and transforms itself. With ML and AI, we’re training machines to surface new objects of knowledge that help us as we learn to ask new, different, and sometimes difficult questions about ourselves. By all indications, we seem to be having some success with this.