

In this episode of the Data Show, I spoke with Jason Dai, CTO of Big Data Technologies at Intel, and one of my co-chairs for the AI Conference in Beijing. I wanted to check in on the status of BigDL, specifically how companies have been using this deep learning library on top of Apache Spark, and discuss some newly added features. It turns out there are quite a number of companies already using BigDL in production, and we talked about some of the popular uses cases he’s encountered. We recorded this podcast while we were at the AI Conference in Beijing, so I wanted to get Dai’s thoughts on the adoption of AI technologies among Chinese companies and local/state government agencies.
Here are some highlights from our conversation:
BigDL: One year later
Big DL was actually first open-sourced on December 30, 2016—so it has been about 1 year and 4 months. We have gotten a lot of positive feedback from the open source community. We also added a lot of new optimizations and functionalities to Big DL. I think it roughly can be categorized into four classes. We did large optimizations, especially for the big data environment, which is essentially very large-scale Intel server clusters. We use a lot of hardware accelerations and Math Kernel libraries to improve BigDL’s performance on a single-node. At the same time, we leverage the Spark architecture so that we can efficiently scale out and perform very large-scale distributed training or inference.
The second part of the year we provided very rich support for existing deep learning tools. We can actually directly load and save models to and from TensorFlow, Caffe, Keras, Torch, and other libraries. People can take the existing models and actually load into Big DL and run it on Spark.
End-to-end machine learning pipelines
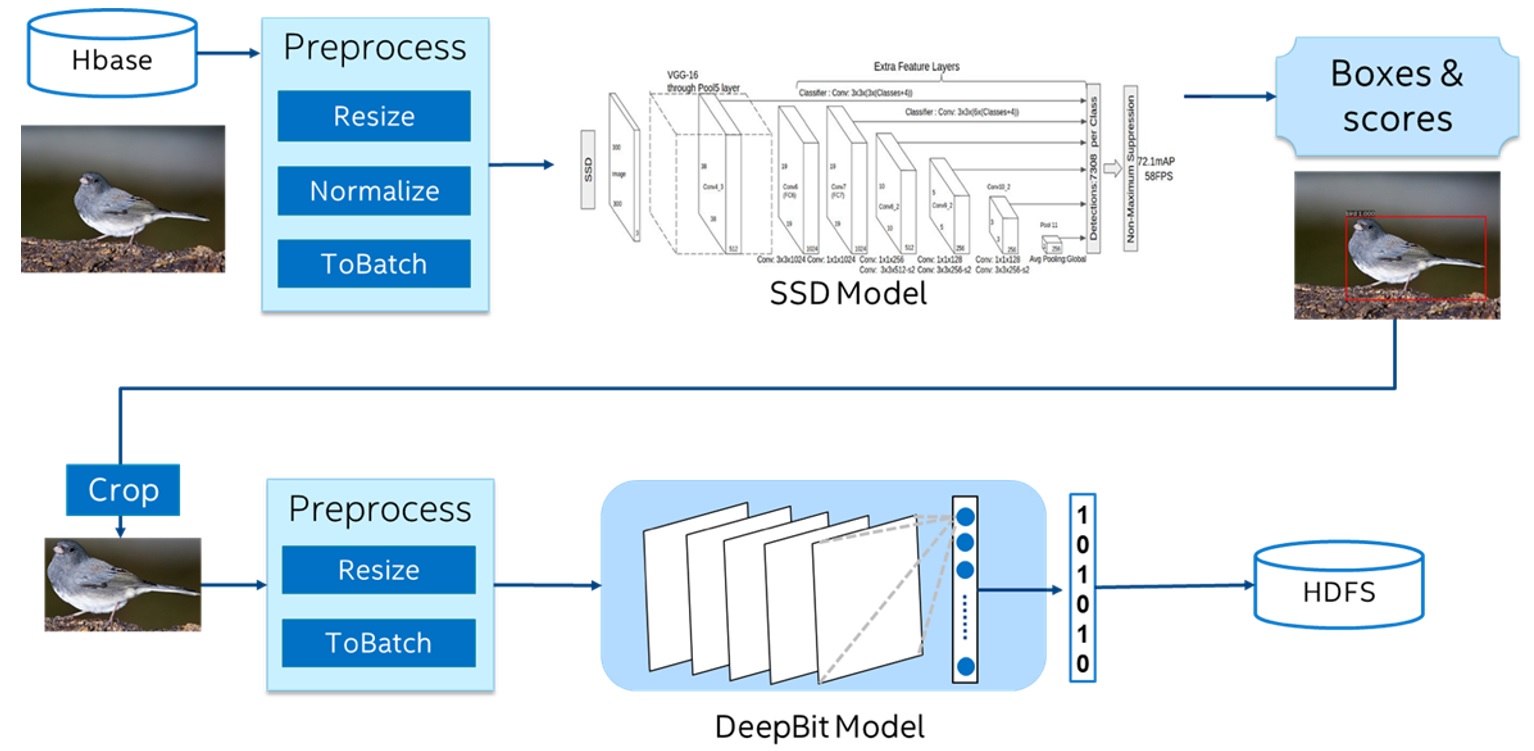
An industrial deep learning or machine learning application is actually a very complex end-to-end, big data analytics pipeline. You start with the data ingestion, data processing, ETL, and then after that, you will transform your data. For instance, you can do image augmentations, text tokenization, word embedding, and so on. After that, you will extract the features or perform various feature transformations and feature extractions. After that, when you have the feature extracted and transformed, then you will probably begin with your model training. But even the model training itself could be an iterative process, a pipeline, if you want to introduce various hyperparameter tunings.
…There’s actually a reason why we took an integrated approach when we built Big DL on top of Apache Spark: you know that you’re going back and forth between data ingestion, data processing, model training, and inference. Having integrated software and hardware infrastructure will benefit the user a lot.
AI in China
People and companies in China have a very high level of awareness and a high level of hope that AI can be used to solve real problems. In China, you have the advantage in that people move fast to apply these new AI technologies. Companies here have access to large amounts of data, and there are many use cases across industries and the public sector. There are a lot of ways you can actually apply new technology and AI to real-world applications and see their impact.
In general, people and companies in China move very fast, and they are very good at experimenting and trying new approaches. People here think they can always iterate and refine their approaches, and we see a lot of new technology getting put into practice very quickly.
Related resources:
- “What happens when AI experts from Silicon Valley and China meet”
- BigDL: Jason Dai on the launch of a new deep learning library for Apache Spark
- “Why AI and machine learning researchers are beginning to embrace PyTorch”: Soumith Chintala on building a worthy successor to Torch and on deep learning within Facebook.
- MXNet: Anima Anandkumar on deep learning that’s easy to implement and easy to scale
- “Introducing RLlib—A composable and scalable reinforcement learning library”: this new software makes the task of training RL models much more accessible
- “How machine learning will accelerate data management systems”: Tim Kraska on why ML will change how we build core algorithms and data