

In a world focused on buzzword-driven models and algorithms, you’d be forgiven for forgetting about the unreasonable importance of data preparation and quality: your models are only as good as the data you feed them. This is the garbage in, garbage out principle: flawed data going in leads to flawed results, algorithms, and business decisions. If a self-driving car’s decision-making algorithm is trained on data of traffic collected during the day, you wouldn’t put it on the roads at night. To take it a step further, if such an algorithm is trained in an environment with cars driven by humans, how can you expect it to perform well on roads with other self-driving cars? Beyond the autonomous driving example described, the “garbage in” side of the equation can take many forms—for example, incorrectly entered data, poorly packaged data, and data collected incorrectly, more of which we’ll address below.
When executives ask me how to approach an AI transformation, I show them Monica Rogati’s AI Hierarchy of Needs, which has AI at the top, and everything is built upon the foundation of data (Rogati is a data science and AI advisor, former VP of data at Jawbone, and former LinkedIn data scientist):
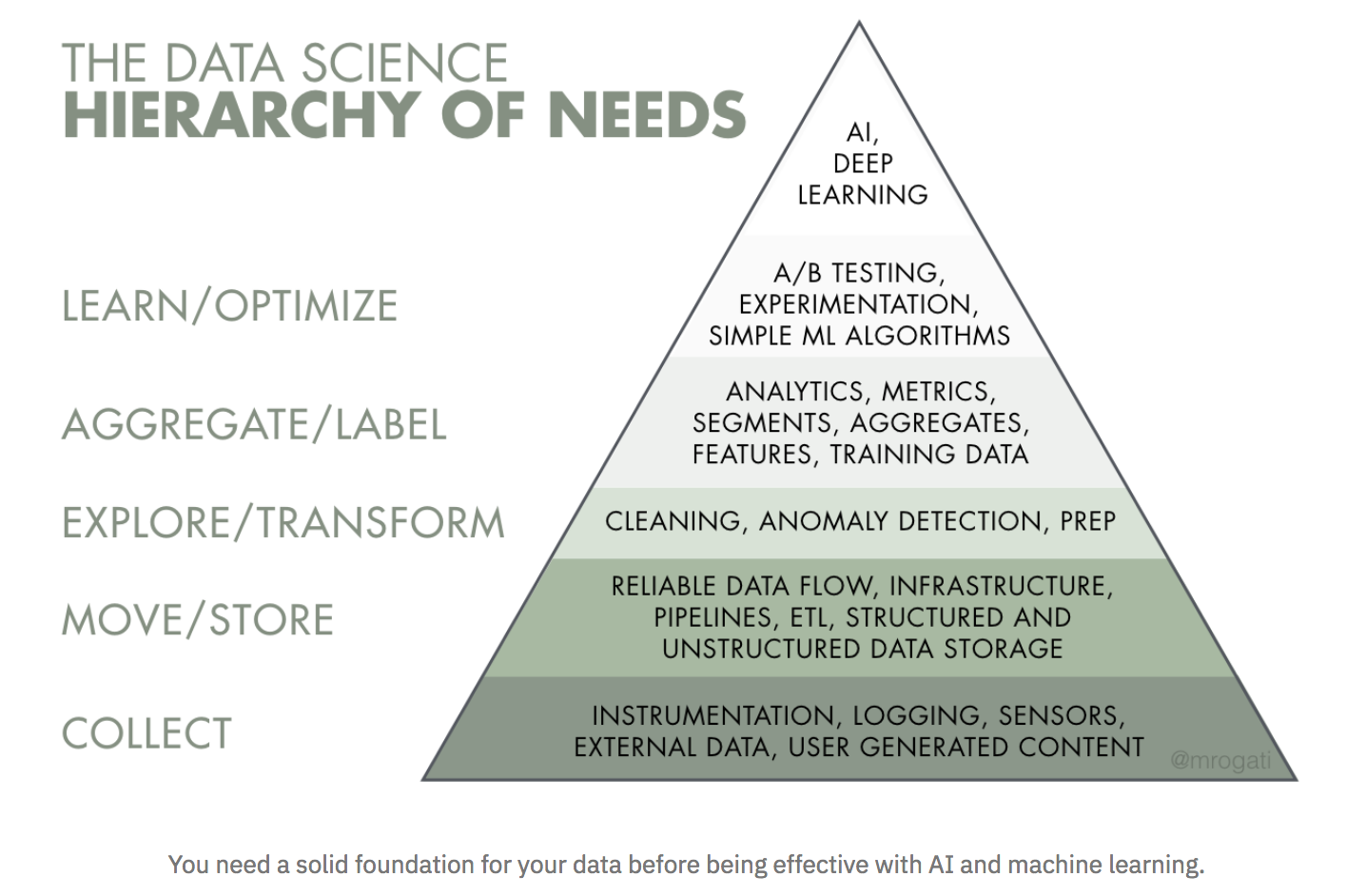
Why is high-quality and accessible data foundational? If you’re basing business decisions on dashboards or the results of online experiments, you need to have the right data. On the machine learning side, we are entering what Andrei Karpathy, director of AI at Tesla, dubs the Software 2.0 era, a new paradigm for software where machine learning and AI require less focus on writing code and more on configuring, selecting inputs, and iterating through data to create higher level models that learn from the data we give them. In this new world, data has become a first-class citizen, where computation becomes increasingly probabilistic and programs no longer do the same thing each time they run. The model and the data specification become more important than the code.
Collecting the right data requires a principled approach that is a function of your business question. Data collected for one purpose can have limited use for other questions. The assumed value of data is a myth leading to inflated valuations of start-ups capturing said data. John Myles White, data scientist and engineering manager at Facebook, wrote: “The biggest risk I see with data science projects is that analyzing data per se is generally a bad thing. Generating data with a pre-specified analysis plan and running that analysis is good. Re-analyzing existing data is often very bad.” John is drawing attention to thinking carefully about what you hope to get out of the data, what question you hope to answer, what biases may exist, and what you need to correct before jumping in with an analysis[1]. With the right mindset, you can get a lot out of analyzing existing data—for example, descriptive data is often quite useful for early-stage companies[2].
Not too long ago, “save everything” was a common maxim in tech; you never knew if you might need the data. However, attempting to repurpose pre-existing data can muddy the water by shifting the semantics from why the data was collected to the question you hope to answer. In particular, determining causation from correlation can be difficult. For example, a pre-existing correlation pulled from an organization’s database should be tested in a new experiment and not assumed to imply causation[3], instead of this commonly encountered pattern in tech:
- A large fraction of users that do X do Z
- Z is good
- Let’s get everybody to do X
Correlation in existing data is evidence for causation that then needs to be verified by collecting more data.
The same challenge plagues scientific research. Take the case of Brian Wansink, former head of the Food and Brand Lab at Cornell University, who stepped down after a Cornell faculty review reported he “committed academic misconduct in his research and scholarship, including misreporting of research data, problematic statistical techniques [and] failure to properly document and preserve research results.” One of his more egregious errors was to continually test already collected data for new hypotheses until one stuck, after his initial hypothesis failed[4]. NPR put it well: “the gold standard of scientific studies is to make a single hypothesis, gather data to test it, and analyze the results to see if it holds up. By Wansink’s own admission in the blog post, that’s not what happened in his lab.” He continually tried to fit new hypotheses unrelated to why he collected the data until he got a null hypothesis with an acceptable p-value—a perversion of the scientific method.
Data professionals spend an inordinate amount on time cleaning, repairing, and preparing data
Before you even think about sophisticated modeling, state-of-the-art machine learning, and AI, you need to make sure your data is ready for analysis—this is the realm of data preparation. You may picture data scientists building machine learning models all day, but the common trope that they spend 80% of their time on data preparation is closer to the truth.

This is old news in many ways, but it’s old news that still plagues us: a recent O’Reilly survey found that lack of data or data quality issues was one of the main bottlenecks for further AI adoption for companies at the AI evaluation stage and was the main bottleneck for companies with mature AI practices.
Good quality datasets are all alike, but every low-quality dataset is low-quality in its own way[5]. Data can be low-quality if:
- It doesn’t fit your question or its collection wasn’t carefully considered;
- It’s erroneous (it may say “cicago” for a location), inconsistent (it may say “cicago” in one place and “Chicago” in another), or missing;
- It’s good data but packaged in an atrocious way—e.g., it’s stored across a range of siloed databases in an organization;
- It requires human labeling to be useful (such as manually labeling emails as “spam” or “not” for a spam detection algorithm).
This definition of low-quality data defines quality as a function of how much work is required to get the data into an analysis-ready form. Look at the responses to my tweet for data quality nightmares that modern data professionals grapple with.
The importance of automating data preparation
Most of the conversation around AI automation involves automating machine learning models, a field known as AutoML. This is important: consider how many modern models need to operate at scale and in real time (such as Google’s search engine and the relevant tweets that Twitter surfaces in your feed). We also need to be talking about automation of all steps in the data science workflow/pipeline, including those at the start. Why is it important to automate data preparation?
- It occupies an inordinate amount of time for data professionals. Data drudgery automation in the era of data smog will free data scientists up for doing more interesting, creative work (such as modeling or interfacing with business questions and insights). “76% of data scientists view data preparation as the least enjoyable part of their work,” according to a CrowdFlower survey.
- A series of subjective data preparation micro-decisions can bias your analysis. For example, one analyst may throw out data with missing values, another may infer the missing values. For more on how micro-decisions in analysis can impact results, I recommend Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results[6] (note that the analytical micro-decisions in this study are not only data preparation decisions). Automating data preparation won’t necessarily remove such bias, but it will make it systematic, discoverable, auditable, unit-testable, and correctable. Model results will then be less reliant on individuals making hundreds of micro-decisions. An added benefit is that the work will be reproducible and robust, in the sense that somebody else (say, in another department) can reproduce the analysis and get the same results[7];
- For the increasing number of real-time algorithms in production, humans need to be taken out of the loop at runtime as much as possible (and perhaps be kept in the loop more as algorithmic managers): when you use Siri to make a reservation on OpenTable by asking for a table for four at a nearby Italian restaurant tonight, there’s a speech-to-text model, a geographic search model, and a restaurant-matching model, all working together in real time. No data analysts/scientists work on this data pipeline as everything must happen in real time, requiring an automated data preparation and data quality workflow (e.g., to resolve if I say “eye-talian” instead of “it-atian”).
The third point above speaks more generally to the need for automation around all parts of the data science workflow. This need will grow as smart devices, IoT, voice assistants, drones, and augmented and virtual reality become more prevalent.
Automation represents a specific case of democratization, making data skills easily accessible for the broader population. Democratization involves both education (which I focus on in my work at DataCamp) and developing tools that many people can use.
Understanding the importance of general automation and democratization of all parts of the DS/ML/AI workflow, it’s important to recognize that we’ve done pretty well at democratizing data collection and gathering, modeling[8], and data reporting[9], but what remains stubbornly difficult is the whole process of preparing the data.
Modern tools for automating data cleaning and data preparation
We’re seeing the emergence of modern tools for automated data cleaning and preparation, such as HoloClean and Snorkel coming from Christopher Ré’s group at Stanford. HoloClean decouples the task of data cleaning into error detection (such as recognizing that the location “cicago” is erroneous) and repairing erroneous data (such as changing “cicago” to “Chicago”), and formalizes the fact that “data cleaning is a statistical learning and inference problem.” All data analysis and data science work is a combination of data, assumptions, and prior knowledge. So when you’re missing data or have “low-quality data,” you use assumptions, statistics, and inference to repair your data. HoloClean performs this automatically in a principled, statistical manner. All the user needs to do is “to specify high-level assertions that capture their domain expertise with respect to invariants that the input data needs to satisfy. No other supervision is required!”
The HoloClean team also has a system for automating the “building and managing [of] training datasets without manual labeling” called Snorkel. Having correctly labeled data is a key part of preparing data to build machine learning models[10]. As more and more data is generated, manually labeling it is unfeasible. Snorkel provides a way to automate labeling, using a modern paradigm called data programming, in which users are able to “inject domain information [or heuristics] into machine learning models in higher level, higher bandwidth ways than manually labeling thousands or millions of individual data points.” Researchers at Google AI have adapted Snorkel to label data at industrial/web scale and demonstrated its utility in three scenarios: topic classification, product classification, and real-time event classification.
Snorkel doesn’t stop at data labeling. It also allows you to automate two other key aspects of data preparation:
- Data augmentation—that is, creating more labeled data. Consider an image recognition problem in which you are trying to detect cars in photos for your self-driving car algorithm. Classically, you’ll need at least several thousand labeled photos for your training dataset. If you don’t have enough training data and it’s too expensive to manually collect and label more data, you can create more by rotating and reflecting your images.
- Discovery of critical data subsets—for example, figuring out which subsets of your data really help to distinguish spam from non-spam.
These are two of many current examples of the augmented data preparation revolution, which includes products from IBM and DataRobot.
The future of data tooling and data preparation as a cultural challenge
So what does the future hold? In a world with an increasing number of models and algorithms in production, learning from large amounts of real-time streaming data, we need both education and tooling/products for domain experts to build, interact with, and audit the relevant data pipelines.
We’ve seen a lot of headway made in democratizing and automating data collection and building models. Just look at the emergence of drag-and-drop tools for machine learning workflows coming out of Google and Microsoft. As we saw from the recent O’Reilly survey, data preparation and cleaning still take up a lot of time that data professionals don’t enjoy. For this reason, it’s exciting that we’re now starting to see headway in automated tooling for data cleaning and preparation. It will be interesting to see how this space grows and how the tools are adopted.
A bright future would see data preparation and data quality as first-class citizens in the data workflow, alongside machine learning, deep learning, and AI. Dealing with incorrect or missing data is unglamorous but necessary work. It’s easy to justify working with data that’s obviously wrong; the only real surprise is the amount of time it takes. Understanding how to manage more subtle problems with data, such as data that reflects and perpetuates historical biases (for example, real estate redlining) is a more difficult organizational challenge. This will require honest, open conversations in any organization around what data workflows actually look like.
The fact that business leaders are focused on predictive models and deep learning while data workers spend most of their time on data preparation is a cultural challenge, not a technical one. If this part of the data flow pipeline is going to be solved in the future, everybody needs to acknowledge and understand the challenge.
Many thanks to Angela Bassa, Angela Bowne, Vicki Boykis, Joyce Chung, Mike Loukides, Mikhail Popov, and Emily Robinson for their valuable and critical feedback on drafts of this essay along the way.