Why you should care about debugging machine learning models
Understanding and fixing problems in ML models is critical for widespread adoption.

For all the excitement about machine learning (ML), there are serious impediments to its widespread adoption. Not least is the broadening realization that ML models can fail. And that’s why model debugging, the art and science of understanding and fixing problems in ML models, is so critical to the future of ML. Without being able to troubleshoot models when they underperform or misbehave, organizations simply won’t be able to adopt and deploy ML at scale.
Because all ML models make mistakes, everyone who cares about ML should also care about model debugging.[1] This includes C-suite executives, front-line data scientists, and risk, legal, and compliance personnel. This article is meant to be a short, relatively technical primer on what model debugging is, what you should know about it, and the basics of how to debug models in practice. These recommendations are based on our experience, both as a data scientist and as a lawyer, focused on managing the risks of deploying ML.

Learn faster. Dig deeper. See farther.
What is model debugging?
Sometimes ML models are just plain wrong, but sometimes they’re wrong and socially discriminatory, or hacked, or simply unethical.[2],[3],[4] Current model assessment techniques, like cross-validation or receiver operator characteristic (ROC) and lift curves, simply don’t tell us about all the nasty things that can happen when ML models are deployed as part of large, complex, public-facing IT systems.[5]
That’s where model debugging comes in. Model debugging is an emergent discipline focused on finding and fixing problems in ML systems. In addition to newer innovations, the practice borrows from model risk management, traditional model diagnostics, and software testing. Model debugging attempts to test ML models like code (because they are usually code) and to probe sophisticated ML response functions and decision boundaries to detect and correct accuracy, fairness, security, and other problems in ML systems.[6] Debugging may focus on a variety of failure modes (i.e., a lot can go wrong with ML models), including:
- Opaqueness: for many failure modes, you need to understand what the model is doing in order to understand what went wrong and how to fix it. Crucially, transparency doesn’t guarantee trustworthy models. But transparency is typically a prerequisite for debugging writ large.
- Social discrimination: by now, there are many widely publicized incidences of social discrimination in ML. These can cause harm to the subjects of the discriminatory model’s decisions and substantial reputational or regulatory harms to the model’s owners.[7]
- Security vulnerabilities: adversarial actors can compromise the confidentiality, integrity, or availability of an ML model or the data associated with the model, creating a host of undesirable outcomes. The study of security in ML is a growing field—and a growing problem, as we documented in a recent Future of Privacy Forum report.[8]
- Privacy harms: models can compromise individual privacy in a long (and growing) list of ways.[8] Data about individuals can be decoded from ML models long after they’ve trained on that data (through what’s known as inversion or extraction attacks, for example). Models may also violate the privacy of individuals by inferring sensitive attributes from non-sensitive data, among other harms.
- Model decay: ML models and data pipelines are notoriously “brittle.”[5] This means unexpected input data or small changes over time in the input data or data pipeline can wreak havoc on a model’s performance.
The best way to prevent and prepare for these kinds of problems is model debugging. We’ll review methods for debugging below.
How is debugging conducted today?
There are at least four major ways for data scientists to find bugs in ML models: sensitivity analysis, residual analysis, benchmark models, and ML security audits.
While our analysis of each method may appear technical, we believe that understanding the tools available, and how to use them, is critical for all risk management teams. Anyone, of any technical ability, should be able to at least think about using model debugging techniques.
Sensitivity analysis
Sensitivity analysis, sometimes called what-if? analysis, is a mainstay of model debugging. It’s a very simple and powerful idea: simulate data that you find interesting and see what a model predicts for that data. Because ML models can react in very surprising ways to data they’ve never seen before, it’s safest to test all of your ML models with sensitivity analysis.[9] While it is relatively straightforward to conduct sensitivity analysis without a formal framework, the What-If Tool is a great way to start playing with certain kinds of models in the TensorFlow family. More structured approaches to sensitivity analysis include:
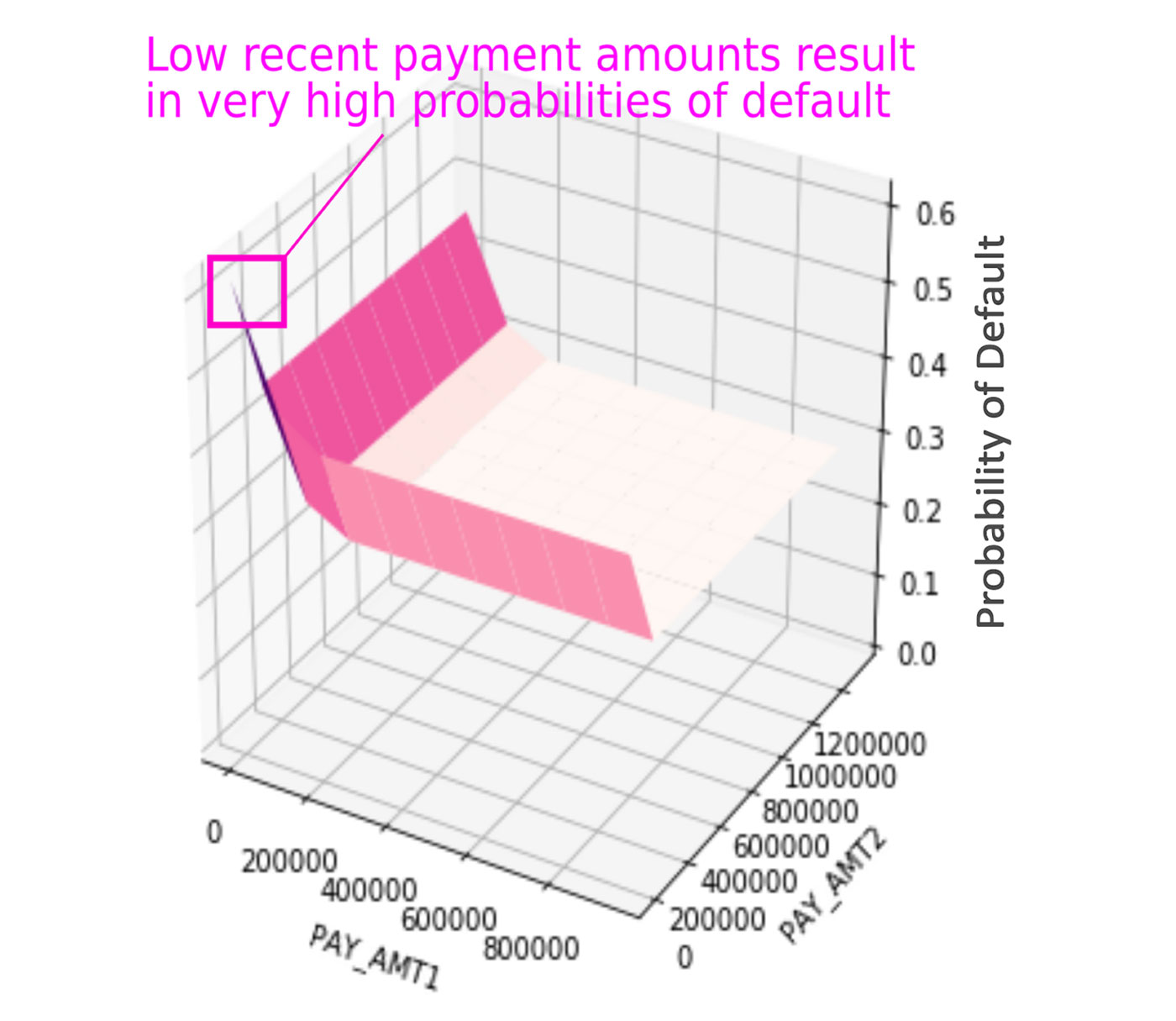
- Adversarial example searches: this entails systematically searching for rows of data that evoke strange or striking responses from an ML model. Figure 1 illustrates an example adversarial search for an example credit default ML model. If you’re using Python and deep learning libraries, the CleverHans and Foolbox packages can also help you debug models and find adversarial examples.
- Partial dependence, accumulated local effect (ALE), and individual conditional expectation (ICE) plots: this involves systematically visualizing the effects of changing one or more variables in your model. There are a ton of packages for these techniques: ALEPlot, DALEX, ICEbox, iml, and pdp in R; and PDPbox and PyCEbox in Python.
- Random attacks: exposing models to high volumes of random input data and seeing how they react. Random attacks can reveal all kinds of unexpected software and math bugs. If you don’t know where to begin debugging an ML system, random attack is a great place to get started.
Residual analysis
Residual analysis is another well-known family of model debugging techniques. Residuals are a numeric measurement of model errors, essentially the difference between the model’s prediction and the known true outcome. Small residuals usually mean a model is right, and large residuals usually mean a model is wrong. Residual plots place input data and predictions into a two-dimensional visualization where influential outliers, data-quality problems, and other types of bugs often become plainly visible. The main drawback of residual analysis is that to calculate residuals, true outcomes are needed. That means it can be hard to work with residuals in some real-time model monitoring settings, but residual analysis should always be doable at model training time.
Like in Figure 2, many discrimination detection techniques consider model errors as well, especially across different demographic groups. This basic bias detection exercise is sometimes called disparate impact analysis.[10] The Gender Shades line of research is a great example of how analyzing errors across demographic groups is necessary for models that affect people.[3] There are a myriad of other tools available for discrimination detection. To learn more about testing ML models for discrimination, check out packages like aequitas, AIF360, Themis, and, more generally, the content created by the Fairness, Accountability, and Transparency in ML (FATML) community.[11]

Benchmark models
Benchmark models are trusted, simple, or interpretable models to which ML models can be compared. It’s always a good idea to check that a new complex ML model does actually outperform a simpler benchmark model. Once an ML model passes this benchmark test, the benchmark model can serve as a solid debugging tool. Benchmark models can be used to ask questions like: “what predictions did my ML model get wrong that my benchmark model got right, and why?” Comparing benchmark model and ML model predictions in real time can also help to catch accuracy, fairness, or security anomalies as they occur.
ML security audits
There are several known attacks against machine learning models that can lead to altered, harmful model outcomes or to exposure of sensitive training data.[8],[12] Again, traditional model assessment measures don’t tell us much about whether a model is secure. In addition to other debugging steps, it may be prudent to add some or all of the known ML attacks into any white-hat hacking exercises or red-team audits an organization is already conducting.
We found something wrong; what do we do?
So you’ve implemented some of the systematic ways to find accuracy, fairness, and security problems in ML-based systems that we’ve discussed. You’ve even discovered a few problems with your ML model. What can you do? That’s where remediation strategies come in. We discuss seven remediation strategies below.
Data augmentation
ML models learn from data to become accurate, and ML models require data that’s truly representative of the entire problem space being modeled. If a model is failing, adding representative data into its training set can work wonders. Data augmentation can be a remediation strategy for discrimination in ML models, too. One major source of discrimination in ML is demographically unbalanced training data. If a model is going to be used on all kinds of people, it’s best to ensure the training data has a representative distribution of all kinds of people as well.
Interpretable ML models and explainable ML
The debugging techniques we propose should work on almost any kind of ML-based predictive model. But they will be easier to execute on interpretable models or with explainable ML. For this reason, and others, we recommend interpretable and explainable ML for high-stakes use cases. Luckily, technological progress has been made toward this end in recent years. There are a lot of options for interpretable and accurate ML models and a lot of ways to explain and describe them.[13]
Model editing
Some ML models are designed to be interpretable so it is possible to understand how they work. Some of these models, like variants of decision trees or GA2M (i.e., explainable boosting machines) can be directly editable by human users. If there’s something objectionable in the inner workings of a GA2M model, it’s not very hard to find it and change the final model equation to get rid of it. Other models might not be as easy to edit as GA2M or decision trees, but if they generate human-readable computer code, they can be edited.
Model assertions
Model assertions can improve or override model predictions in real time.[14] Model assertions are business rules that act on model predictions themselves. Examples could include checking the age of a customer to whom a model recommends advertising alcoholic beverages, or checking for large prepayments for a prediction that says a high net worth individual is about to default.
Discrimination remediation
There are a lot of ways to fix discrimination in ML models. Many non-technological solutions involve promoting a diversity of expertise and experience on data science teams, and ensuring diverse intellects are involved in all stages of model building.[15] Organizations should, if possible, require that all important data science projects include personnel with expertise in ethics, privacy, social sciences, or other related disciplines.
From a technical perspective, discrimination remediation methods fall into three major buckets: data pre-processing, model training and selection, and prediction post-processing. For pre-processing, careful feature selection, and sampling and reweighing rows to minimize discrimination in training data can be helpful.
For model training and selection, we recommend considering fairness metrics when selecting hyperparameters and decision cutoff thresholds. This may also involve training fair models directly by learning fair representations (LFR) and adversarial debiasing in AIF360, or using dual objective functions that consider both accuracy and fairness metrics. Last, for prediction post-processing, changing model predictions after training, like reject-option classification in AIF360 or Themis ML, can also help to reduce unwanted bias.
Model monitoring
Model debugging is not a one-and-done task. The accuracy, fairness, or security characteristics of ML models are not static. They can change significantly over time based on the model’s operating environment. We recommend monitoring ML models for accuracy, fairness, and security problems at regular time intervals once they are deployed.
Anomaly detection
Strange, anomalous input and prediction values are always worrisome in ML, and can be indicative of an adversarial attack on an ML model. Luckily, anomalous inputs and predictions can be caught and corrected in real time using a variety of tools and techniques: data integrity constraints on input data streams, statistical process control methodologies on inputs and predictions, anomaly detection through autoencoders and isolation forests, and also by comparing ML predictions to benchmark model predictions.
Conclusion and further reading
Everyone wants trustworthy ML models. And that means that as ML is more widely adopted, the importance of model debugging will only increase over time. That holds true for everyone from Kagglers to front-line data scientists to legal and risk management personnel and for ML consumers and decision subjects. Those interested in more details can dig deeper into the code on GitHub used to create the examples in this post.[16] Or, you can learn more about model debugging in the ML research community by checking out the 2019 International Conference on Learning Representations (ICLR) Debugging Machine Learning Models workshop proceedings.[17] Hopefully some of these techniques will work for you and your team. If so, have fun debugging!