
Web Client Programming with Perl
Automating Tasks on the Web
By Clinton Wong1st Edition March 1997
This book is out of print, but it has been made available online through the O'Reilly Open Books Project.
|
|
|
|
|
Web Client Programming with PerlAutomating Tasks on the WebBy Clinton Wong1st Edition March 1997 This book is out of print, but it has been made available online through the O'Reilly Open Books Project. |
Chapter 2.
Demystifying the Browser
In this chapter:
Behind the Scenes of a Simple Document
Retrieving a Document Manually
Behind the Scenes of an HTML Form
Behind the Scenes of Publishing a Document
Structure of HTTP Transactions
Before you start writing your own web programs, you have to become comfortable with the fact that your web browser is just another client. Lots of complex things are happening: user interface processing, network communication, operating system interaction, and HTML/graphics rendering. But all of that is gravy; without actually negotiating with web servers and retrieving documents via HTTP, the browser would be as useless as a TV without a tuner.
HTTP may sound intimidating, but it isn't as bad as you might think. Like most other Internet protocols, HTTP is text-based. If you were to look at the communication between your web browser and a web server, you would see text--and lots of it. After a few minutes of sifting through it all, you'd find out that HTTP isn't too hard to read. By the end of this chapter, you'll be able to read HTTP and have a fairly good idea of what's going on during typical everyday transactions over the Web.
The best way to understand how HTTP works is to see it in action. You actually see it in action every day, with every click of a hyperlink--it's just that the gory details are hidden from you. In this chapter, you'll see some common web transactions: retrieving a page, submitting a form, and publishing a web page. In each example, the HTTP for each transaction is printed as well. From there, you'll be able to analyze and understand how your actions with the browser are translated into HTTP. You'll learn a little bit about how HTTP is spoken between a web client and server.
After you've seen bits and pieces of HTTP in this chapter, Chapter 3, Learning HTTP, introduces HTTP in a more thorough manner. In Chapter 3, you'll see all the different ways that a client can request something, and all the ways a server can reply. In the end, you'll get a feel for what is possible under HTTP.
Behind the Scenes of a Simple Document
Let's begin by visiting a hypothetical web server at http://hypothetical.ora.com/. Its imaginary (and intentionally sparse) web page appears in Figure 2-1.
Figure 2-1. A hypothetical web page
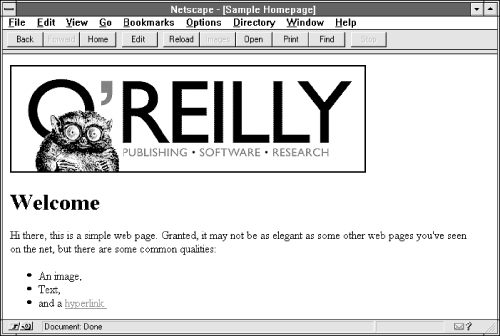
This is something you probably do every day--request a URL and then view it in your browser. But what actually happened in order for this document to appear in your browser?
The Browser's Request
Your browser first takes in a URL and parses it. In this example, the browser is given the following URL:
http://hypothetical.ora.com/The browser interprets the URL as follows:
- http://
- In the first part of the URL, you told the browser to use HTTP, the Hypertext Transfer Protocol.
- hypothetical.ora.com
- In the next part, you told the browser to contact a computer over the network with the hostname of hypothetical.ora.com.
- /
- Anything after the hostname is regarded as a document path. In this example, the document path is /.
So the browser connects to hypothetical.ora.com using the HTTP protocol. Since no port was specified, it assumes port 80, the default port for HTTP. The message that the browser sends to the server at port 80 is:
GET / HTTP/1.0Connection: Keep-AliveUser-Agent: Mozilla/3.0Gold (WinNT; I)Host: hypothetical.ora.comAccept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*Let's look at what these lines are saying:
- The first line of this request (GET / HTTP/1.0) requests a document at / from the server. HTTP/1.0 is given as the version of the HTTP protocol that the browser uses.
- The second line tells the server to keep the TCP connection open until explicitly told to disconnect. If this header is not provided, the server has no obligation to stick around under HTTP 1.0, and disconnects after responding to the client's request. The behavior of the client and server depend on what version of HTTP is spoken. (See the discussion of persistent connections in Chapter 3 for the full scoop.)
- In the third line, beginning with the string User-Agent, the client identifies itself as Mozilla (Netscape) version 3.0, running on Windows NT.
- The fourth line tells the server what the client thinks the server's hostname is. Since the server may have multiple hostnames, the client indicates which hostname was used. In this environment, a web server can have a different document tree for each hostname it owns. If the client hasn't specified the server's hostname, the server may be unable to determine which document tree to use.
- The fifth line tells the server what kind of documents are accepted by the browser. This is discussed more in the section "Media Types" in Chapter 3.
Together, these 5 lines constitute a request. Lines 2 through 5 are request headers.
The Server's Response
Given a request like the one previously shown, the server looks for the file associated with "/" and returns it to the browser, preceding it with some "header information":
HTTP/1.0 200 OKDate: Fri, 04 Oct 1996 14:31:51 GMTServer: Apache/1.1.1Content-type: text/htmlContent-length: 327Last-modified: Fri, 04 Oct 1996 14:06:11 GMT<title>Sample Homepage</title><img src="/images/oreilly_mast.gif"><h1>Welcome</h2>Hi there, this is a simple web page. Granted, it may not be as elegantas some other web pages you've seen on the net, but there aresome common qualities:<ul><li> An image,<li> Text,<li> and a <a href="/example2.html"> hyperlink </a></ul>If you look at this response, you'll see that it begins with a series of lines that specify information about the document and about the server itself. Then after a blank line, it returns the document. The series of lines before the first blank line is called the response header, and the part after the first blank line is called the body or entity, or entity-body. Let's look at the header information:
- The first line, HTTP/1.0 200 OK, tells the client what version of the HTTP protocol the server uses. But more importantly, it says that the document has been found and is going to be transmitted.
- The second line indicates the current date on the server. The time is expressed in Greenwich Mean Time (GMT).
- The third line tells the client what kind of software the server is running. In this case, the server is Apache version 1.1.1.
- The fourth line (Content-type) tells the browser the type of the document. In this case, it is HTML.
- The fifth line tells the client how many bytes are in the entity body that follows the headers. In this case, the entity body is 327 bytes long.
- The sixth line specifies the most recent modification time of the document requested by the client. This modification time is often used for caching purposes--so a browser may not need to request the entire HTML file again if its modification time doesn't change.
After all that, a blank line and the document text follow.
Figure 2-2 shows the transaction.
Figure 2-2. A simple transaction
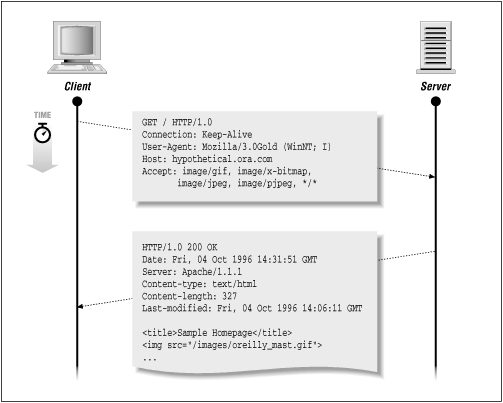
Parsing the HTML
The document is in HTML (as promised in the Content-type line). The browser retrieves the document and then formats it as needed--for example, each <li> item between the <ul> and </ul> is printed as a bullet and indented, the <img> tag displays a graphic on the screen, etc.
And while we're on the topic of the <img> tag, how did that graphic get on the screen? While parsing the HTML file, the browser sees:
<img src="/images/oreilly_mast.gif">and figures out that it needs the data for the image as well. Your browser then sends a second request, such as this one, through its connection to the web server:
GET /images/oreilly_mast.gif HTTP/1.0Connection: Keep-AliveUser-Agent: Mozilla/3.0Gold (WinNT; I)Host: hypothetical.ora.comAccept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*The server responds with:
HTTP/1.0 200 OKDate: Fri, 04 Oct 1996 14:32:01 GMTServer: Apache/1.1.1Content-type: image/gifContent-length: 9487Last-modified: Tue, 31 Oct 1995 00:03:15 GMT[data of GIF file]Figure 2-3 shows the complete transaction, with the image requested as well as the original document.
Figure 2-3. Simple transaction with embedded image
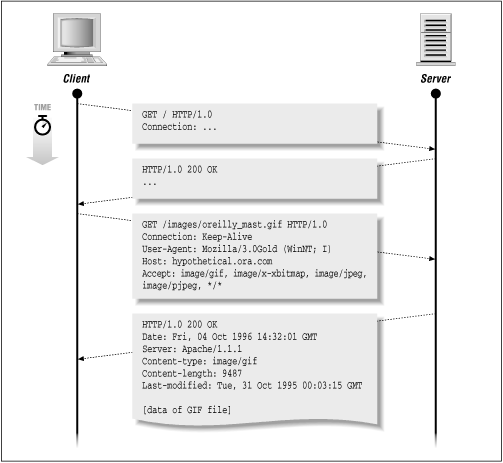
There are a few differences between this request/response pair and the previous one. Based on the <img> tag, the browser knows where the image is stored on the server. From <img src="/images/oreilly_mast.gif">, the browser requests a document at a different location than "/":
GET /images/oreilly_mast.gif HTTP/1.0The server's response is basically the same, except that the content type is different:
Content-type: image/gifFrom the declared content type, the browser knows what kind of image it will receive and can render it as required. The browser shouldn't guess the content type based on the document path; it is up to the server to tell the client.
The important thing to note here is that the HTML formatting and image rendering are done at the browser end. All the server does is return documents; the browser is responsible for how they look to the user.
Clicking on a Hyperlink
When you click on a hyperlink, the client and server go through something similar to what happened when we visited http://hypothetical.ora.com/. For example, when you click on the hyperlink from the previous example, the browser looks at its associated HTML:
<a href="/example2.html"> hyperlink </a>From there, it knows that the next location to retrieve is /example2.html. The browser then sends the following to hypothetical.ora.com:
GET /example2.html HTTP/1.0Connection: Keep-AliveUser-Agent: Mozilla/3.0Gold (WinNT; I)Host: hypothetical.ora.comAccept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*The server responds with:
HTTP/1.0 200 OKDate: Fri, 04 Oct 1996 14:32:14 GMTServer: Apache/1.1.1Content-type: text/htmlContent-length: 431Last-modified: Thu, 03 Oct 1996 08:39:45 GMT[HTML data]And the browser displays the new HTML page on the user's screen.
Retrieving a Document Manually
Now that you see what a browser does, it's time for the most empowering statement in this book: There's nothing in these transactions that you can't do yourself. And you don't need to write a program--you can just do it by hand, using the standard telnet client and a little knowledge of HTTP.
Telnet to www.ora.com at port 80. From a UNIX shell prompt:[1]
% telnet www.ora.com 80Trying 198.112.208.23 ...Connected to www.ora.com.Escape character is '^]'.(The second argument for telnet specifies the port number to use. By default, telnet uses port 23. Most web servers use port 80. If you are behind a firewall, you may have problems accessing www.ora.com directly from your machine. Replace www.ora.com with the hostname of a web server inside your firewall for the same effect.)
Now type in a GET command[2] for the document root:
GET / HTTP/1.0Press ENTER twice, and you receive what a browser would receive:
HTTP/1.0 200 OKServer: WN/1.15.1Date: Mon, 30 Sep 1996 14:14:20 GMTLast-modified: Fri, 20 Sep 1996 17:04:18 GMTContent-type: text/htmlTitle: O'Reilly & AssociatesLink: <mailto:webmaster@ora.com>; rev="Made"<HTML><HEAD><LINK REV=MADE HREF="mailto:webmaster@ora.com">...When the document is finished, your shell prompt should return. The server has closed the connection.
Congratulations! What you've just done is simulate the behavior of a web client.
Behind the Scenes of an HTML Form
You've probably seen fill-out forms on the Web, in which you enter information into your browser and submit the form. Common uses for forms are guestbooks, accessing databases, or specifying keywords for a search engine.
When you fill out a form, the browser needs to send that information to the server, along with the name of the program needed to process it. The program that processes the form information is called a CGI program. Let's look at how a browser makes a request from a form. Let's direct our browser to contact our hypothetical server and request the document /search.html:
GET /search.html HTTP/1.0Connection: Keep-AliveUser-Agent: Mozilla/3.0Gold (WinNT; I)Host: hypothetical.ora.comAccept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*The server responds with:
HTTP/1.0 200 OKDate: Fri, 04 Oct 1996 14:33:43 GMTServer: Apache/1.1.1Content-type: text/htmlContent-length: 547Last-modified: Tue, 01 Oct 1996 08:48:02 GMT<title>Library Search</title><FORM ACTION="http://hypothetical.ora.com/cgi-bin/query" METHOD=POST>Enter book title, author, or subject here:<p><INPUT TYPE="radio" NAME="querytype" VALUE="title" CHECKED> Title<p><INPUT TYPE="radio" NAME="querytype" VALUE="author"> Author<p><INPUT TYPE="radio" NAME="querytype" VALUE="subject"> Subject<p>Keywords:<input type="text" name="queryconst" value="" size="50,2" ><p><BR>Press DONE to start your search.<hr><input type="submit" value="Done"><input type="reset" value="Start over"></FORM>The formatted document is shown in Figure 2-4.
Figure 2-4. A HTML form rendered in the browser
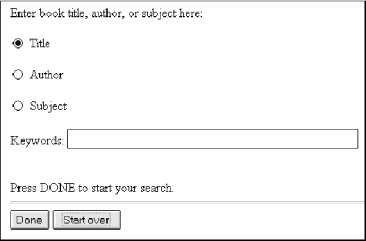
Let's fill out the form and submit it, as shown in Figure 2-5.
Figure 2-5. Filling out the form
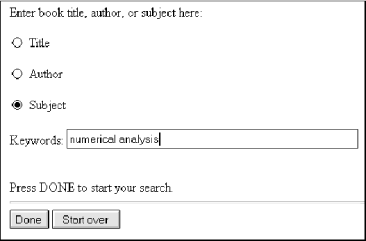
After hitting the Done button, the browser connects to hypothetical.ora.com at port 80, as specified with the <FORM> tag in the HTML:
<FORM ACTION="http://hypothetical.ora.com/cgi-bin/query" METHOD=POST>The browser then sends:
POST /cgi-bin/query HTTP/1.0Referer: http://hypothetical.ora.com/search.htmlConnection: Keep-AliveUser-Agent: Mozilla/3.0Gold (WinNT; I)Host: hypothetical.ora.comAccept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*Content-type: application/x-www-form-urlencodedContent-length: 47querytype=subject&queryconst=numerical+analysisIn the previous example retrieving the initial page at hypothetical.ora.com, we showed a series of lines that the browser output and called it a request header. Calling it a header might not have made any sense at the time, since there was no content being sent with it--if you're just requesting a document, you don't have to tell the server anything else. But since in this instance we have to tell the server what the user typed into the form, we have to use a "body" portion of the message to convey that information. So there are a few new things to note in this example:
- Instead of GET, the browser started the transaction with the string POST. GET and POST are two types of request methods recognized by HTTP. The most important thing that POST tells the server is that there is a body (or "entity") portion of the message to follow.
The browser used the POST method because it was specified in the <FORM> tag:
<FORM ACTION="http://hypothetical.ora.com/cgi-bin/query" METHOD=POST>- The browser included an extra line specifying a Content-type. This wasn't necessary in the previous example because no content was being sent with the request. The Content-type line tells the server what sort of data is coming so it can determine how best to handle it. In this case, it tells the server that the data to be sent is going to be encoded using the application/x-www-form-urlencoded format. This format specifies how to encode special characters, and how to send multiple variables and values in forms. See Chapter 3 and Appendix B, Reference Tables, for more information on URL encoding.
- The browser included another line specifying a Content-length. Similarly, this wasn't necessary earlier because there was no content to the entity body. But there is in this example; it tells the server how much data to retrieve. In this case, the Content-length is 47 bytes.
- After a blank line, the entity-body is issued, reading querytype=subject&queryconst=numerical+analysis. (Notice that this string is exactly 47 characters, as specified in the Content-length line.)
Where did this querytype=subject&queryconst=numerical+analysis line come from? In the HTML of the form, the input field was specified with the following lines:
<INPUT TYPE="radio" NAME="querytype" VALUE="subject"> Subject<p><input type="text" name="queryconst" value="" size="50,2" >The NAME="querytype" and VALUE="subject" part of the first <INPUT> tag was encoded as "querytype=subject". The NAME="queryconst" part of the second <INPUT> tag specifies a variable name to use for whatever text is supplied in that field. We filled in that field with the words "numerical analysis." Thus, for the form data entered by the user, the browser sends:
querytype=subject&queryconst=numerical+analysisto specify the variable and value pairs used in the form. Two or more variable/value pairs are separated with an ampersand (&). Notice that the space between "numerical" and "analysis" was replaced by a plus sign (+). Certain characters with special meaning are translated into a commonly understood format. The complete rundown of these transformations is covered in Appendix B.
At this point, the server processes the request by forwarding this information on to the CGI program. The CGI program then returns some data, and the server passes it back to the client as follows:
HTTP/1.0 200 OKDate: Tue, 01 Oct 1996 14:52:06 GMTServer: Apache/1.1.1Content-type: text/htmlContent-length: 760Last-modified: Tue, 01 Oct 1996 12:46:15 GMT<title>Search Results</title><h1>Search criteria too wide.</h2><h2>Refer to:</h2><hr><pre>1 ASYMPTOTIC EXPANSIONS2 BOUNDARY ELEMENT METHODS3 CAUCHY PROBLEM--NUMERICAL SOLUTIONS4 CONJUGATE DIRECTION METHODS5 COUPLED PROBLEMS COMPLEX SYSTEMS--NUMERICAL SOLUTIONS6 CURVE FITTING7 DEFECT CORRECTION METHODS NUMERICAL ANALYSIS8 DELAY DIFFERENTIAL EQUATIONS--NUMERICAL SOLUTIONS9 DIFFERENCE EQUATIONS--NUMERICAL SOLUTIONS10 DIFFERENTIAL ALGEBRAIC EQUATIONS--NUMERICAL SOLUTIONS11 DIFFERENTIAL EQUATIONS HYPERBOLIC--NUMERICAL SOLUTIONS12 DIFFERENTIAL EQUATIONS HYPOELLIPTIC--NUMERICAL SOLUTIONS13 DIFFERENTIAL EQUATIONS NONLINEAR--NUMERICAL SOLUTIONS</pre><hr>Figure 2-6 shows the results as rendered by the browser.
Figure 2-6. Form results
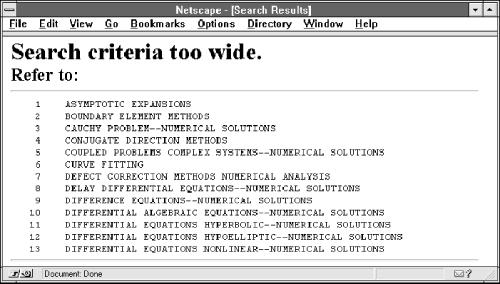
We'll have a more detailed discussion about posting form data and the application/x-www-form-urlencoded encoding method in Chapter 3, when we discuss the POST method in more detail.
Behind the Scenes of Publishing a Document
If you've ever used a WYSIWYG HTML editor, you might have seen the option to publish your documents on a web server. Typically, there's an FTP option to upload your document to the server. But on most modern publishers, there's also an HTTP upload option. How does this work?
Let's create a sample document in Navigator Gold, as in Figure 2-7.
Figure 2-7. Sample document for publishing
After saving this file to C:/temp/example.html, let's publish it to the fictional site http://publish.ora.com/, using the dialog box shown in Figure 2-8.
Figure 2-8. Dialog box for publishing
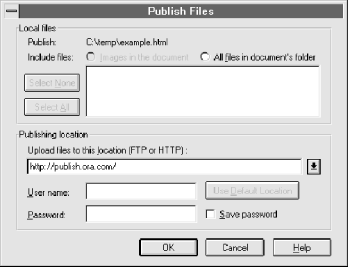
After clicking OK, the browser contacts publish.ora.com at port 80 and then sends:
PUT /example.html HTTP/1.0Connection: Keep-AliveUser-Agent: Mozilla/3.0Gold (WinNT; I)Pragma: no-cacheHost: publish.ora.comAccept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*Content-Length: 307<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2//EN"><HTML><HEAD><TITLE></TITLE><META NAME="Author" CONTENT=""><META NAME="GENERATOR" CONTENT="Mozilla/3.0Gold (WinNT; I) [Netscape]"></HEAD><BODY><H2>This is a header</H2><P>This is a simple html document.</P></BODY></HTML>The server then responds with:
HTTP/1.0 201 CreatedDate: Fri, 04 Oct 1996 14:31:51 GMTServer: HypotheticalPublish/1.0Content-type: text/htmlContent-length: 30<h1>The file was created.</h2>And now the contents of the file C:/temp/example.html has been transferred to the server.[3]
Structure of HTTP Transactions
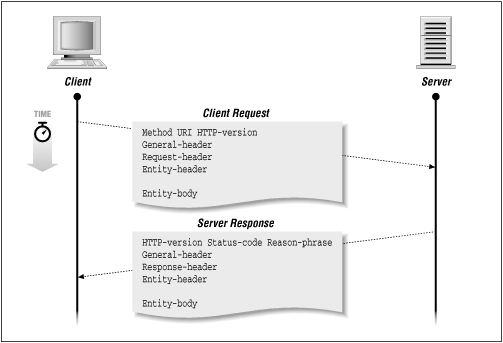
Now it's time to generalize. All client requests and server responses follow the same general structure, shown in Figure 2-9.
Figure 2-9. General structure of HTTP requests
Let's look at some queries that are modeled after examples from earlier in this chapter. Figure 2-10 shows the structure of a client request.
Figure 2-10. Structure of a client request
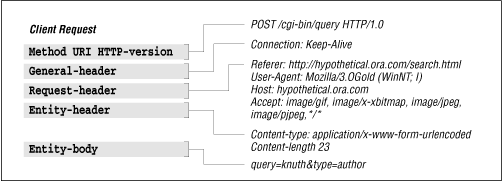
HTTP transactions do not need to use all the headers. In fact, it is possible to perform some HTTP requests without supplying any header information at all. A request of GET / HTTP/1.0 with an empty header is sufficient for most servers to understand the client.
HTTP requests have the following general components:
- The first line tells the client which method to use, which entity (document) to apply it to, and which version of HTTP the client is using. Possible methods in HTTP 1.0 are GET, POST, HEAD, PUT, LINK, UNLINK, and DELETE. HTTP 1.1 also supports the OPTIONS and TRACE methods. Not all methods need be supported by a server.
The URL specifies the location of a document to apply the method to. Each server may have its own way of translating the URL string into some form of usable resource. For example, the URL may represent a document to transmit to the client. Or the URL may actually be a program, the output of which is sent to the client.
Finally, the last entry on the first line specifies the version of HTTP the client is using. More about this in the next chapter.
- General message headers are optional headers used in both the client request and server response. They indicate general information such as the current time or the path through a network that the client and server are using.
- Request headers tell the server more information about the client. The client can identify itself and the user to the server, and specify preferred document formats that it would like to see from the server.
- Entity headers are used when an entity (a document) is about to be sent. They specify information about the entity, such as encoding schemes, length, type, and origin.
Now for server responses. Figure 2-11 maps out the structure of a server response.
Figure 2-11. Structure of a server response
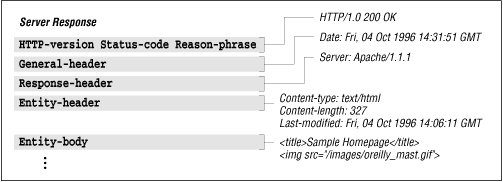
In the server response, the general header and entity headers are the same as those used in the client request. The entity-body is like the one used in the client request, except that it is used as a response.
The first part of the first line indicates the version of HTTP that the server is using. The server will make every attempt to conform to the most compatible version of HTTP that the client is using. The status code indicates the result of the request, and the reason phrase is a human-readable description of the status-code.
The response header tells the client about the configuration of the server. It can inform the client of what methods are supported, request authorization, or tell the client to try again later.
In the next chapter, we'll go over all the gory details of possible values and uses for HTTP entries.
1. You can use a telnet client on something other than UNIX, but it might look different. On some non-UNIX systems, your telnet client may not show you what you're typing if you connect directly to a web server at port 80.
2. Actually called a method, but command makes more sense for people who are going through this the first time around. More about this later.
3. You might have noticed that there wasn't a
Content-typeheader sent by the client. There should be one, but the software used to generate this example didn't include it. Other web publishing programs do, however. It's generally good practice for the originator of the data to specify what the data is.
Back to: Chapter Index
Back to: Web Client Programming with Perl
© 2001, O'Reilly & Associates, Inc.
webmaster@oreilly.com