
 Sharpest tool in the shed. (source: Lachlan Donald on Flickr)
Sharpest tool in the shed. (source: Lachlan Donald on Flickr) I’m always on the lookout for ideas that can improve how I tackle data analysis projects. I particularly favor approaches that translate to tools I can use repeatedly. Most of the time, I find these tools on my own—by trial and error—or by consulting other practitioners. I also have an affinity for academics and academic research, and I often tweet about research papers that I come across and am intrigued by. Often, academic research results don’t immediately translate to what I do, but I recently came across ideas from several research projects that are worth sharing with a wider audience.
The collection of ideas I’ve presented in this post address problems that come up frequently. In my mind, these ideas also reinforce the notion of data science as comprising data pipelines, not just machine learning algorithms. These ideas also have implications for engineers trying to build artificial intelligence (AI) applications.
Use a reusable holdout method to avoid overfitting during interactive data analysis
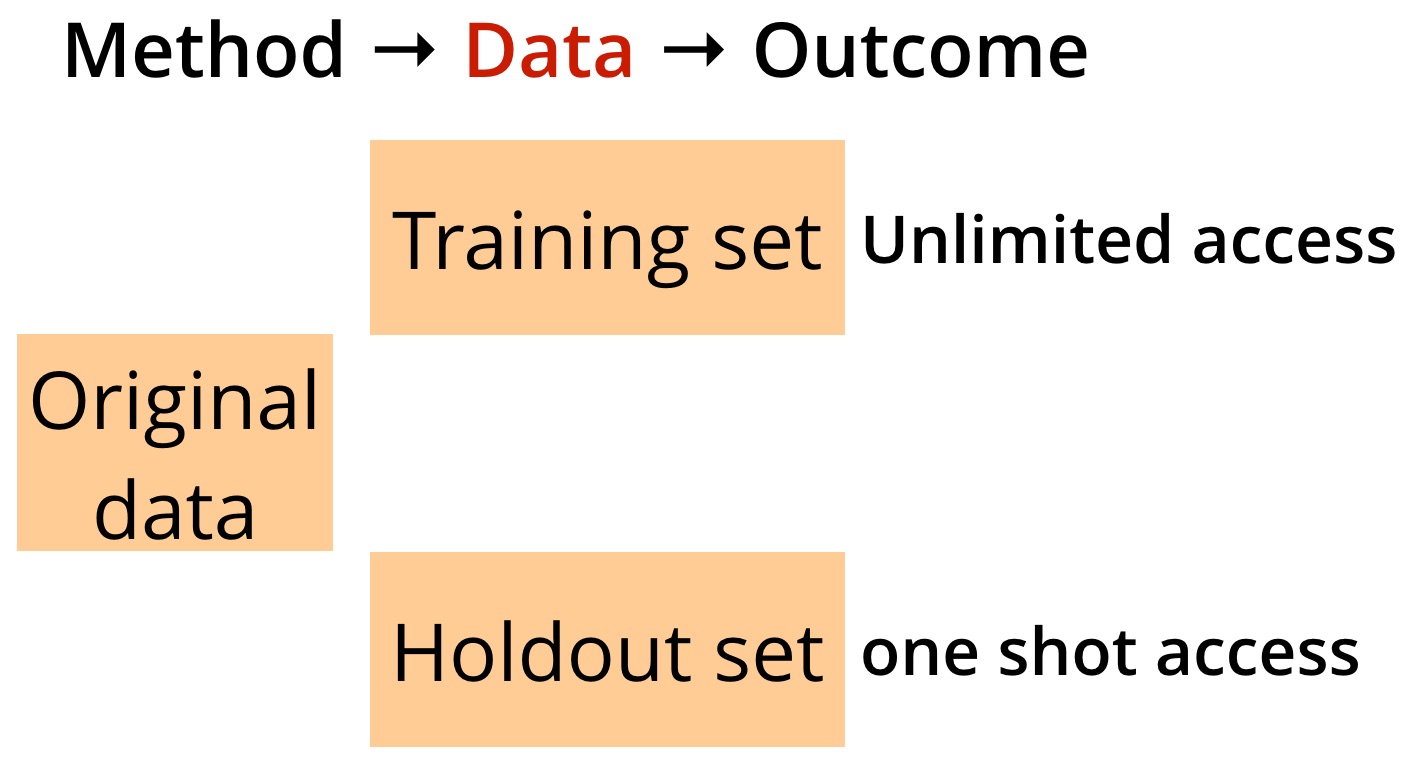
Overfitting is a well-known problem in statistics and machine learning. Techniques like the holdout method, bootstrap and cross-validation are used to avoid overfitting in the context of static data analysis. The widely used holdout method involves splitting an underlying data set into two separate sets. But practitioners (and I’m including myself here) often forget something important when applying the classic holdout method: in theory the corresponding holdout set is accessible only once (as illustrated in Figure 1).
In reality, most data science projects are interactive in nature. Data scientists iterate many times and revise their methods or algorithms based on previous results. This frequently leads to overfitting because in many situations, the same holdout set is used multiple times (as illustrated in Figure 2):
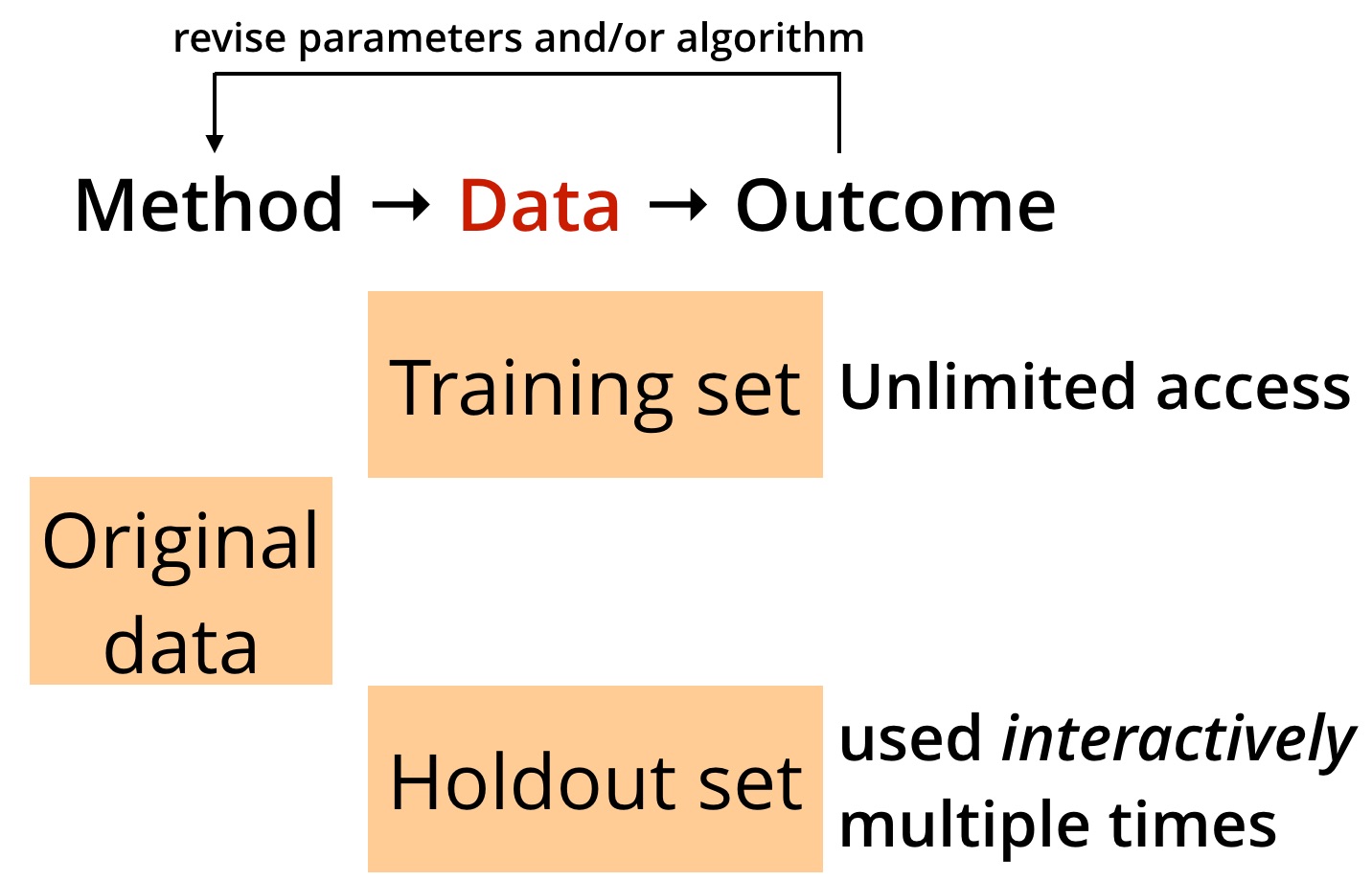
To address this problem, a team of researchers devised reusable holdout methods by drawing from ideas in differential privacy. By addressing overfitting, their methods can increase the reliability of data products, particularly as more intelligent applications get deployed in critical situations. The good news is that the solutions they came up with are accessible to data scientists and do not require an understanding of differential privacy. In a presentation at Hardcore Data Science in San Jose, Moritz Hardt of Google (one of the researchers) described their proposed Thresholdout method using the following Python code:
from numpy import * def Thresholdout(sample, holdout, q): # function q is what you’re “testing” - e.g., model loss sample_mean = mean([q(x) for x in sample]) holdout_mean = mean([q(x) for x in holdout]) sigma = 1.0 / sqrt(len(sample)) threshold = 3.0*sigma if (abs(sample_mean - holdout_mean) < random.normal(threshold, sigma) ): # q does not overfit: your “training estimate” is good return sample_mean else: # q overfits (you may have overfit using your training data) return holdout_mean + random.normal(0, sigma)
Details of their Thresholdout and other methods can be found in this paper and Hardt’s blog posts here and here. I also recommend a recent paper on blind analysis—a related data-perturbation method used in physics that may soon find its way into other disciplines.
Use random search for black-box parameter tuning
Most data science projects involve pipelines that involve “knobs” (or hyperparameters) that need to be tuned appropriately, usually on a trial-and-error basis. These hyperparameters typically come with a particular machine learning method (network depth and architecture, window size, etc.), but they can also involve aspects that affect data preparation and other steps in a data pipeline.
With the growing number of applications of machine learning pipelines, hyperparameter tuning has become a subject of many research papers (and even commercial products). Many of the results are based on Bayesian optimization and related techniques.
Practicing data scientists need not rush to learn Bayesian optimization. Recent blog posts (here and here) by Ben Recht of UC Berkeley highlighted research that indicates when it comes to black-box parameter tuning, simple random search is actually quite competitive with more advanced methods. And efforts are underway to accelerate random search for particular workloads.
Explain your black-box models using local approximations
In certain domains (including health, consumer finance, and security), model interpretability is often a requirement. This comes at a time when black-box models—including deep learning and other algorithms, and even ensembles of models—are all the rage. With the current interest in AI, it is important to point out that black-box techniques will only be deployed in certain application domains if tools to make them more interpretable are developed.
A recent paper by Marco Tulio Ribeiro and colleagues hints at a method that can make such models easier to explain. The idea proposed in this paper is to use a series of interpretable, locally faithful approximations: These are interpretable, local models that approximate how the original model behaves in the vicinity of the instance being predicted. The researchers observed that although a model may be too complex to explain globally, providing an explanation that is locally faithful is often sufficient.
A recent presentation illustrated the utility of the researchers’ approach. One of the co-authors of the paper, Carlos Guestrin, demonstrated an implementation of a related method that helped debug a deep neural network used in a computer vision application.
Carlos Guestrin will give a presentation titled, “Why should I trust you? Explaining the predictions of machine-learning models,” at Strata + Hadoop World in New York City, September 26-29, 2016.
Related resources:
- Introduction to Local Interpretable Model-Agnostic Explanations (LIME)
- Six reasons why I like KeystoneML—a conversation with Ben Recht
- The evolution of GraphLab—a conversation with Carlos Guestrin
- Deep Learning—a collection of talks at Strata + Hadoop World