4 trends in security data science for 2018
A glimpse into what lies ahead for response automation, model compliance, and repeatable experiments.
 Pendulum (source: Pixabay)
Pendulum (source: Pixabay)
This is the third consecutive year I’ve tried to read the tea leaves for security analytics. Last year’s trends post manifested well: from a rise in adversarial machine learning (ML) to the deep learning craze (such that entire conferences are now dedicated to this subject). This year, Hyrum Anderson, technical director of data science from Endgame, joins me in calling out the trends in security data science for 2018. We present a 360-degree view of the security data science landscape—from unicorn startups to established enterprises.
The format remains mostly remains the same: four trends to map to each quarter of the year. For each trend, we provide a rationale about why the time is right to capitalize on the trend, offer practical tips on what you can do now to join the conversation, and include links to papers, GitHub repositories, tools, and tutorials. We also added a new section “What won’t happen in 2018” to help readers look beyond the marketing material and stay clear of hype.

Learn faster. Dig deeper. See farther.
1. Machine learning for response (semi-)automation
In 2016, we predicted a shift from detection to intelligent investigation. In 2018, we’re predicting a shift from rich investigative information toward distilled recommended actions, backed by information-rich incident reports. Infosec analysts have long stopped clamoring for “more alerts!” from security providers. In the coming year, we’ll see increased customer appetite for products to recommend actions based on solid evidence. Machine learning has, in large part, proven itself a valuable tool for detecting evidence of threats used to compile an incident report. Security professionals subconsciously train themselves to respond to (or ignore) the evidence of an incident in a certain way. The linchpin to scale in information security rests still on the information security analyst, and many of the knee-jerk responses can be automated. In some cases, the response might be ML-automated, but in many others it will be at least ML-recommended.
Why now?
The information overload pain point is as old as IDS technology—not a new problem for machine learning to tackle—and some in the industry have invested in ML-based (semi-) automated remediation. However, there are a few pressures driving more widespread application of ML to simplify response through ML distillation rather than complicate with additional evidence: (1) market pressure to optimize workflows instead of alerts—to scale human response, (2) diminishing returns on reducing time-to-detect compared to time-to-remediate.
What can you do?
- Assess remediation workflows of security analysts in your organization: (1) What pieces of evidence related to the incident provide high enough confidence to respond? (2) What evidence determines how to respond? (3) For a typical incident, how many decisions must be made during remediation? (4) How long does remediation take for a typical incident? (5) What is currently being automated reliably? (6) What tasks could still be automated?
- Don’t force a solution on security analysts—chances are, they are creating custom remediation scripts in powershell or bash. You may already be using a mixed-bag of commercial and open source tools for remediation (e.g., Ansible to task commands to different groups, or open source @davehull’s Kansa).
- Assess how existing solutions can help simplify and automate remediation steps. Check out Demisto, or Endgame’s Artemis.
2. Machine learning for attack automation
“Invest in adversarial machine learning” was listed in our previous two yearly trends because of the tremendous uptick in research activity. In 2018, we’re predicting that one manifestation of this is now ripe for adoption in the mainstream: ML for attack automation. A caveat: although we believe that 2018 will be the year that ML begins to be adopted for automating—for example, social engineering phishing attacks or bypassing CAPTCHA—we don’t think it’s necessarily the year we’ll see evidence in the wild of sophisticated methods to subvert your machine learning malware detection, or to discover and exploit vulnerabilities in your network. That’s still research, and today, there are still easier methods for attackers.
Why now?
There’s been significant research activity to demonstrate how, at least theoretically, AI can scale digital attacks in an unprecedented way. Tool sets are making the barrier to entry quite low. And there are economic drivers to do things like bypass CAPTCHA. Incidentally, today’s security risks and exploits are often more embarrassing than sophisticated, so that even sophisticated adversaries may not require machine learning to be effective, instead relying on unpatched deficiencies in networks that the attacker understands and exploits. So, it’s important to not be an alarmist. Think of ML for attack automation as just an algorithmic wrinkle that adds dynamism and efficiency to automatically discovering or exploiting during an attack.
What can you do?
- Protect your users by more than simple image/audio CAPTCHA-like techniques that can be solved trivially by a human. Chances are that if it’s trivially solved by a human, then it’s a target for machine learning automation. There are no easy alternatives—but, moderate success has been obtained in image recognition showing fragments of a single image (say, a scene on the road), and asking to pick out those pieces that have a desired object (say, a red car).
- Calmly prepare for even the unlikely. Ask yourself: how would you discover whether an attack on your network was automated by machine learning or by old-fashioned enumeration in a script? (Might you see exploration-turn-to-exploitation in an ML attack? Would it matter?)
- Familiarize yourself with pen testing and red-teaming tools like Caldera, Innuendo, and Atomic Red Team, which can simulate advanced manual attacks, but would also give you a leg-up on automated attacks in years to come.
3. Model compliance
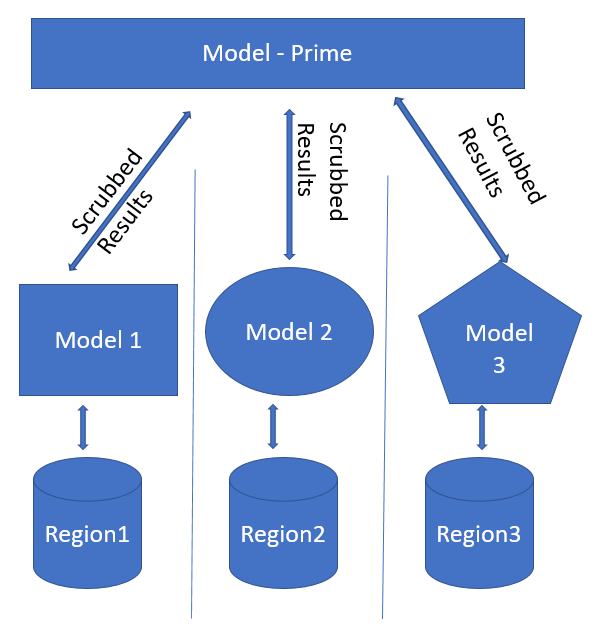
Global compliance laws affect the design, engineering, and operational costs of security data science solutions. The laws themselves provide strict guidelines around data handling, movement (platform constraints), as well as model-building constraints such as explainability and the “right to be forgotten.” Model compliance is not a one-time investment: privacy laws change with the political landscape. For instance, it is not clear how Britain leaving the European Union might affect the privacy laws in the UK. In some cases, privacy laws do not agree—for instance, Irish DPA considers IP addresses to be personally identifiable information, which is not the case across the world. More concretely, if you have an anomalous logins detection based on IP addresses, in some parts of the world the detection would not work because IP addresses would be scrubbed/removed. This means that the same machine learning model for detecting these anomalous logins would not work across different geographic regions.
Why now?
Building models that are respectful of compliance laws is important because failure to do so not only brings with it crippling monetary costs—for instance, failure to adhere to the new European General Data Protection Regulation (GDPR), set to take effect in May 2018, can result in a fine of up to 20 million Euros, or 4% of annual global turnover—but also the negative press associated for the business.
What can you do?
- As an end consumer, you would need to audit your data and tag it appropriately. Those who are on AWS are lucky, with Amazon’s Macie service. If your data set is small, it is best to bite the bullet and do it by hand.
- Many countries prevent cloud providers from merging locality-specific data outside regional boundaries. We recommend tiered modeling: each geographic region is modeled separately, and the results are scrubbed and sent to a global model. Differentially private ensembles are particularly relevant here.
4. Rigor and repeatable experiments
The biggest buzz of the NIPS 2017 conference was when Ali Rahimi claimed current ML methods are akin to alchemy (read commentary from @fhuszar on this subject). At the core of Rahimi’s talk was how the machine learning field is progressing on non-rigorous methods that are not widely understood and, in some cases, not repeatable. For instance, researchers showed how the same reinforcement algorithm from two different code bases on the same data set, had vastly different results. Jason Brownlee’s blog breaks down the different ways an ML experiment can produce random results: from randomization introduced by libraries to GPU quirks.
Why now?
We are at a time where there is a deluge of buzzwords in the security world—artificial intelligence, advanced persistent threats, and machine deception. As a field, we have matured to know there are limitations to every solution; there is no omnipotent solution—even if it were to use the latest methods. So, this one is less of a trend and more a call to action.
What can you do?
- Whenever you publish your work, at an academic conference or a security con, please release your code and the data set you used for training. The red team is very good at doing this; we defenders need to step up our game.
- Eschew publishing your detection results on the KDD 1999 data set—claiming state-of-the-art results on a data set that was popular during the times of Internet Explorer 5 and Napster is unhygienic. (“MNIST is the new unit test,” suggested Ian Goodfellow, but it doesn’t convey a successful result.) Consider using a more realistic data set like Splunk’s Boss of the SOC curated by Ryan Kovar.
- We understand that in some cases there are no publicly available benchmarks and there is a constraint to release the data set as is—in that case, consider generating evaluation data in a simulated environment using @subtee’s Red Canary framework.
- When you present a method at a conference, highlight the weakness and failures of the method—go beyond false positive and false negative rates, and highlight the tradeoffs. Let the audience know what kinds of attacks you will miss and how you compensate for them. If you need inspiration, I will be at the Strata Data Conference in San Jose this March talking about the different security experiments that spectacularly failed and how we fixed them.
Your efforts to bring rigor to the security analytics field are going to benefit us all—the rising tide does raise all boats.
What won’t happen in 2018
To temper some of the untempered excitement (and sometimes hype) about machine learning in information security, we conclude with a few suggestions for things that we aren’t likely to see in 2018.
Reinforcement learning (RL) for offense in the wild
RL has been used to train agents that demonstrate superhuman performance at very narrow tasks, like AlphaGo and Atari. In infosec, it has been demonstrated in research settings to, for example, discover weaknesses of next-gen AV at very modest rates. However, it’s not yet in the “it just works” category, and we forecast another one to two years before infosec realizes interesting offensive or defensive automation via RL.
Generative adversarial networks (GANs) in an infosec product
Generally speaking, GANs continue to see a ton of research activity with impressive results—the excitement is totally warranted. Unfortunately, there’s also been a lack of systematic and objective evaluation metrics in their development. This is a cool hammer that has yet to find its respective killer application in infosec.
Machine learning displacing security jobs
In fact, we think the assimilation causality may go in reverse: because of ever-improving accessibility of machine learning, many more infosec professionals will begin to adopt machine learning in traditional security tasks.
Hype around AI in infosec
It is a fact that, especially in infosec, those talking about “AI” usually mean “ML.” Despite our best efforts, in 2018, the loaded buzzwords about AI in security aren’t going away. We still need to educate customers about how to cut through the hype by asking the right questions. And frankly, a consumer shouldn’t care if it’s AI, ML, or hand-crafted rules. The real question should be, “does it protect me?”
Parting thoughts
The year 2018 is going to bring ML-for-response, as well as the milder forms of attack automation, into the mainstream. As an industry, compliance laws for machine learning will affect a more general shift toward data privacy. The ML community will self-correct toward rigor and repeatability. At the same time, this year we will not see security products infused with RL or GANs—despite popularity in ongoing research. Your infosec job is here to stay, despite more use of ML. Finally, we’ll see this year that ML is mature enough to stand on its own, with no need to be propped up with imaginative buzzwords or hype.
We would love to hear your thoughts—reach out to us (@ram_ssk and @drhyrum) and join the conversation!