 Human mechanics. (source: PublicDomainPicture.net)
Human mechanics. (source: PublicDomainPicture.net) Machine learning (ML) systems have become increasingly accessible in commodity software systems through cloud-based Application Programming Interfaces (APIs) or software libraries. However, even though ML systems may resemble traditional data pipelines, they are distinct in that they provide software systems a way to learn from experience. We will show how this difference presents novel challenges, as ML systems depend on models that are often opaque to the Site Reliability Engineers (SREs) responsible for the production environment. These systems need proper controls in place to meet these challenges, and the SRE role can address this with best practices that anticipate and minimize risk. Without these practices, ML might endanger system health, affect operational or business outcomes, or inappropriately influence user decisions.
In this article, we discuss principles and best practices for SRE practitioners who are deploying and operating ML systems. This article draws on our experiences running production services for the past 15 years as well as from discussions with Google engineers working on diverse ML systems. We will use specific incidents to illustrate where ML-based systems did not behave as expected for developers of traditional systems, and examine the outcomes in light of the recommended practices. Along the way, we discuss postmortem1 scenarios such as the skew between training and serving data, when these best practices were not followed. Our goal is to present good methodologies drawn on insights from outages and production problems so that introducing ML into your systems becomes easy and reliable.
Challenges of Operating an ML-Based System
Building a reliable, end-to-end ML environment can be extremely challenging, yet most of the things that go wrong in large ML systems are basic, not subtle. ln order to understand some of these challenges, let’s establish some background about machine learning. With the advent of increasingly powerful hardware and abundant data center capacity, ML has become a commonplace, often-invisible component of services and products. Machine learning uses algorithmic approaches to analyze vast amounts of data in order to provide inferences that shape the interaction between user and product. For example, ML in photo-sharing services such as Google Photos identifies people and milestones in individuals’ lives and bundles them into relevant albums.2 These photos also include aesthetic effects that are automatically added by the software, relying on neural networks to choose the best exposure and frame from a series of similar photographs.
For application developers, ML provides more highly personalized services. In cloud, ML has become a differentiator: ML-based services and APIs are touted as an advantage over other cloud providers. The flexibility, power, and speed of cloud computing allow ML to be more widely available, and more easily integrated into third-party applications.
ML pipelines differ from other data pipelines: although all data processing and serving systems are changed by the data they process, the data input into an ML system can fundamentally shape the current system as well as subsequent generations.3 Although all data-processing pipelines reflect the data that they process, ML pipelines are by their nature exquisitely sensitive to the distribution and volume of data. For example, a search engine using a static model returns the same top ten results to every user who makes a query of “jaguar”; the same engine using an ML model might return very different results to different users depending on the context of their query. ML provides the mechanism for differentiating the interactions between a system and its users depending on new data, so that the system learns from changes in the input data.
Most ML systems present a statistical summary of the data they process, governed by the algorithms that make up the system. In order to produce results, ML systems depend on the generations of data that feed their corpus in order to build and improve models—small changes in the type, organization, or distribution of input data can have profound (and subtle), impact on the models produced.4 Researchers at Jigsaw, authors of the Conversation AI for understanding how machine learning methods help online conversations, found that “non-toxic statements containing certain identity terms, such as ‘I am a gay man’, were given unreasonably high toxicity scores. We call this false positive bias.” This bias adversely affects the user interaction with the system, and forms one of the key concerns for engineers operating the system in a production environment. As user happiness is “ultimately what matters,”5 a mature SRE organization will focus on building and operating systems that deliver user happiness.
Best Practices for Machine Learning in Production
Now that we have established some of the challenges inherent in ML-based systems, we can discuss the best practices that will help you develop more reliable systems. Production best practices are guidelines, establishing common ground for engineers in production to improve the health of systems and to avoid the risk of undesired behaviors.6 Computer systems, pipelines, data schemes, and code all change continuously. Best practices guard these changes against pushing a system off the rails. These practices result from common experiences across many teams and different organizations across Alphabet (Google’s parent company). These recommendations apply to the pipelines most commonly used today: a supervised learning model with periodic or occasional training and offline serving. Although following them does not ensure that your system will be perfect, these practices are basic requirements when building large deployments that involve ML.
Our proposal for best practices focuses on:
- Defining a training pipeline
- Model management, including validation, qualification, and deployment
- Developing specific monitoring
Let’s dive in.
Define your training pipeline
As the system’s architects—software engineers and product managers alike—define the requirements of the ML model, data scientists work on building a new prototype with the test data. The data flows through the pipeline, where different stages slice, filter, and clean the data; the training step uses the aggregate data to build a model. Then, data scientists demand more production data to run verifications on the model and make sure the model has a good prediction accuracy. By now, you may think the model is complete and ready to be used in production. However, this is just the start of productionizing the pipeline.
Provide clean input data (notes)
SREs have the responsibility of maintaining the overall health and relevance of a training pipeline, and each of the following steps suggests methods to prevent breakdowns at different stages of the pipeline.
Data quality is one of the most important factors in building a pipeline that reliably builds successful models. Because we can represent ML systems with a pipeline model, such as the system shown in Figure 1, consider our overall goal as SREs to be identification of problems with the pipeline that might lead to poor-quality aggregate data, inefficient resource usage, or bad models. For example, a primary, critical goal for a training pipeline such as that for YouTube is to remove videos that are less likely to be relevant for people watching children’s shows from the Recommendations section. For instance, the system can remove videos with violent content, or videos masking explicit songs with cartoon visuals. The pipeline is also responsible for having a representative number of videos from different geographic regions—e.g., American football videos on Super Bowl Sunday should not dominate over other relevant topics for viewers outside of North America. Figure 1 illustrates the phases that filter and impute the data for a general pipeline, and shows how data quality is guaranteed through data filtering, imputation, and aggregation from different sources.
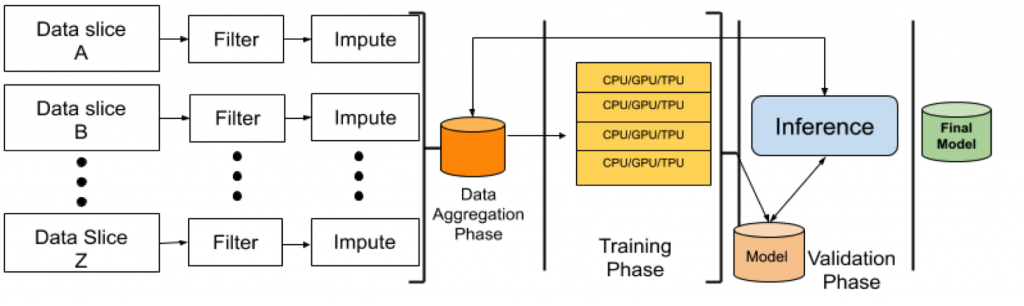
Figure 1: A reference ML pipeline model, showing data filtering and imputation; training; model validation; and inference
More data is worse, unless it’s the right data, so let’s look at how SREs can prevent low-quality data from making its way into the aggregate data set. The training pipeline includes steps for checking data quality: as the training pipeline collects raw input data, it then filters and imputes it. These initial steps of the pipeline address basic data quality: by parsing the input data, the pipeline can check that these values have expected semantics and fall within valid ranges. Next, the pipeline can impute any missing values, substituting for missing data based on statistical models. Alternatively, the system can label missing data before it passes it on to the training phase, allowing the model to use properties of other data to determine a value for the missing data.7 The system can ultimately discard invalid or incomplete data as long as a sufficient dataset exists; the size of the dataset depends on the problem domain as well as on the quality of the data. Regardless of the volume of data fed into a training pipeline, all of the data needs to be of a sufficient quality to be in any way useful. For YouTube, this representative data might mean ensuring representation for different geographic regions as well as varying demographics, and will entail tuning the data input to the system as well as monitoring the recommendations provided by the model to users.
For the training phase of the pipeline (see Figure 1), machine learning sometimes uses specialized compute resources such as graphics processing units (GPUs) or tensor processing units (TPUs), rather than general-purpose CPUs. Efficient use of compute resources is important “any time a service cares about money,”8 and this certainly applies to scarce resources such as TPUs. Filtering data saves space and compute time by sending less data to the processor-intensive training phase. For example, training on ten percent of randomized input data leads to a useful model yet uses less compute time or resources, by a factor of ten. This reduces training time, and leads to faster iterations between model generations. While learning on more data is often helpful, keep in mind that simply training on more data does not necessarily mean getting a more accurate model. Training on the right amount of representative data produces the most efficient, accurate model. Filtering also cleans out corrupted or irrelevant data, ensuring that only high-quality data is used to build the model. The Unreasonable Effectiveness of Data illustrates the notion of better data leading to higher-performing models, referring to a study on a corpus of photographs.9
An approach called online training can further improve the performance of a model. An SRE can use this technique to reduce processing costs and to enable training over a growing data set. This technique uses repeated steps for training a model, processing data from oldest to newest as it becomes available; contrast this with the batch training approach that ingests and processes all of the data in a single step in order to produce a model. Looking at the pipeline in Figure 1, imagine a loop from the end of the pipeline back to the beginning: that’s online training. The online training method applies to an ML pipeline regardless of the complexity of the machine-learning algorithms the pipeline uses to build a model. In using this method in critical ML pipelines at Google, we have observed accuracy gains over a purely batch-training approach. In addition, projects can use online training to reduce training time for each update. By initially using batch training over a large corpus, and then subsequently improving the model with online training, a project can take a hybrid approach in order to efficiently use resources in the long term and also improve the model. Note that the batch training will use more compute resources, and the online training will use a smaller amount: thus a project can run a large initial training over all the training data to quickly catch up to real time, then use a much smaller amount of compute resources to update the model with new data as it arrives. Online training keeps the training time proportional to the daily influx of data, so keeping models up-to-date becomes much more scalable by orders of magnitude, compared to retraining from scratch for every data update. However, due to the lack of supervision on online training, we open our models to other problems such as catastrophic forgetting10—that is, a model’s abrupt and utter loss of previous information when it receives new data.
An analysis/monitoring pipeline slices input data into what data scientists identify as relevant dimensions. The production engineers then track the distribution among those dimensions. In order to effectively monitor the pipeline, SREs can develop expectations for the inputs and outputs at each stage of the pipeline and alert accordingly on changes. For example, if you have data with a geographic component, the input data is analyzed for substantial changes in the distribution across geography or geographic regions that are missing. If the input data handles pictures containing objects, the pipeline might analyze the data for the distribution of size, color, and even the semantic realm of the objects in question. During continuous training, when new data is added to existing models, the pipeline must maintain the same proportions of this distribution. It’s a good idea to have an alert for when proportions change; this prevents the introduction of bias to the model. Using statistical process control methods11 for monitoring can guide the development of these alerts and lead to more stable systems.
Manage your models
SREs can draw on principles for cheap and easy rollouts to improve model management. These principles manifest as model snapshots, validation, and qualification, as well as familiar release and rollback procedures.
Take snapshots of your models
To maximize resources used in processing data, the workflow involves taking snapshots of the models to a checkpoint on disk. Failures become increasingly common with large, distributed processes that run over a long period of time, and these failures can interrupt training. Taking snapshots periodically during training avoids time lost from hardware or software failures. Snapshots also allow the system to resume training from a known-good point. A reliable snapshotting mechanism saves the approximate data state to ensure that data is neither skipped nor reused as input when training resumes. This setup further contributes to clean input data. Cloud-managed ML services usually take care of setting up a reliable snapshotting mechanism for you.
Validate your models
Validating an ML model for serving means to verify that the model produces reasonable outputs for data that were not used during the training phase. We’ll discuss in detail the notion of “reasonable” in the “Develop specific monitoring” section later. To validate a model, reserve part of the input data set for validation before training the model. How much and which data a system splits between training and validation requires discussion with a data scientist, and the answer is specific to each model. A consistent best practice with time-influenced models is to validate them with more recent data rather than training data.
Qualify your models
A large number of ML-related outages for large services at Google resulted from putting new models of lower quality or incompatible format into a serving system. The good news is that after such an incident, service owners developed and exercised rollback procedures. These procedures allowed engineers involved in subsequent incidents to mitigate bad model pushes within the hour, and kept the service within its service level objective,12 or SLO.
Some common patterns of failure caused by model rollouts include the following; we will discuss monitoring to avoid these failures in detail below.
- Model is not tested with representative data. When the model fails to account for new or differing data patterns, the quality of inferences decreases. Practically speaking for a service such as YouTube, this scenario means lower-quality ads, less relevant suggestions, and incongruent “Up Next” video queues for users. For other automated systems, this means bad or nonactionable information on where to place data. Monitoring for engagement, and for changes in engagement over time, will indicate the ongoing effectiveness of the model.
- Model is not compatible with the API in production. As models evolve, so does an ML API. In several incidents, users pushed a model to production using an incompatible API. This scenario is a well-known problem, and can lead to rapid system failure when a new model is deployed against an older version of the API (or vice versa). API compatibility was a root cause for enough incidents across Google that our basic ML serving infrastructure now enforces that models being pushed to production are compatible with the APIs they use. Monitoring for model use will provide a defense against this issue.
- Model is not validated against real data. Other outages have occurred when the data format of the inference input was changed without updating the model. As a result, the inference input was not compatible with the model. As the pipeline did not validate this new data in a canary step,13 the user-facing part of the system sent less useful suggestions to users. Users, in turn, clicked on fewer suggestions and overall engagement went down. Monitoring for model accuracy, especially by collecting user feedback, will provide a signal on data quality.
You can build your system to defend against various failure modes by automating validation during rollouts. One such failure mode is API incompatibility: by including a check in the rollout to verify that the same API and data schema is used in training and deployment, your system will be resilient in deploying a model that a binary cannot successfully serve. The ML framework you use should validate all ML models; and, in addition, testing the model in canary or a staged rollout allows the binaries, configuration, and data to be mutually tested. If you don’t test the model, you may end up with a production system with an unknown combination of inputs.
Requiring a human to intervene and roll back a poorly performing model is generally regarded as a suboptimal approach.14 Not having humans involved in the process removes the risk of deploying an incompatible model. Even if a human is involved, the more automated the process, the better it is. For example, at Google, an SLO-affecting outage in a global, user-facing service was the result of binary skew, the condition in which a model relies on software features such as a framework or API version that are not present in the serving binary, yet were present in the preproduction or testing binary. During this SLO-affecting outage, newer models could not talk to older production binaries because of the skew. The skew also affected the speed of rollback, which likely extended the incident. Google now encourages automated checking of the model signature, for both deployments and rollbacks, to prevent this problem.
Skew between training and serving data leads to another common failure mode. This happens when the metadata about training features doesn’t match the metadata about those same features in serving. Think of a feature that now represents zip code but the serving system believes is cost. This can cause potentially huge, difficult-to-detect quality problems with ML systems. One way to defend against this skew is to establish a golden set of queries and the expected responses. This manually built, human-curated golden set provides a canary test to show that a model behaves as expected, and can show whether a model’s quality has drifted over generations.
To compare outcomes between current and new generations of a model, A/B testing in production is a common practice. To compare outcomes, A/B testing uses multiple models for inference, and follows one of these two approaches:
- All models get all inputs, and the output is compared by evaluation of specific metrics, or
- The system uses gradual deployment, where a new model only gets a portion of the inputs.
The latter technique allows for finer control when pushing the new model. There is also better control of different outcomes from the new model, and very fast rollback because the old model is still running. Whether or not the system uses A/B testing, you should include instrumentation to allow production engineers to observe the behavior of models during deployment. The metrics must provide enough contextual information to identify changes in performance and accuracy.
Deploy your model
When deploying a service with ML models, you must ensure that you have a process to roll back the model and binary release, in case of bad training or an unexpected outcome of your model. As discussed in Site Reliability Engineering, a process that is not continually exercised is essentially broken!15 Effective model management suggests that rollbacks for both the binary and the model should form part of a regularly tested process, and be testable and fast.
Model labels such as API and model compatibility are attributes you can use to drive model management. These attributes are captured in the metadata, and the system confirms these attributes at both deployment and rollback time. The only reliable way to ensure safe rollbacks is to run system tests that verify backward compatibility. These tests should run as the code is built—before each version is deployed. Doing these tests guarantee that the rollback is safe, and the guarantee itself is only possible with the metadata information in the model’s signature. This scenario is similar to changing the database schema, except that the SQL queries in your application are updated during database schema changes. The ML Metadata library, available as part of TensorFlow, provides management of this metadata and the hooks needed to automate model deployment, verification, and rollback.
Develop specific monitoring
The customary approach to monitoring systems—and especially distributed systems—involves collecting metrics, aggregating them, and acting on changes beyond a specified threshold.16 This approach suits many distributed systems but is not as useful for describing common entities, such as model age and predictions served per model. It’s not sufficient to capture the quality of end-user experience or answer the question, “How good is this ML model?”
Complete monitoring for any system includes identifying metrics, building dashboards, and defining SLOs and alerts. Other authors have previously described the complexity and importance of monitoring and metrics for ML systems in production. For simplicity, this section focuses only on the metrics.
Our recommendations for the key signals in ML monitoring include the following:
- Presence. The first and most important step is to make sure a working model in production is present. To achieve this, use a metric that indicates when a deployment or a rollback has been completed. Model version number is a valid metric for this case, and useful to reliability engineers if it is linked to the model’s metadata. Resource-usage metrics are a proxy for the model version number: “the model is using Central Processing Unit (CPU) resources; it is present in production.”
- Use. Verify that the model, in addition to being present, is being used by the production system.CPU and memory are two key resource metrics to ensure that training and production are correct and working properly. The variance of these metrics might indicate anomalies. Queries per second, error rate (ideally split by error type), and latency are follow-up metrics that translate users’ usage of the models. Variations in latency are important if they are defined in the SLO. However, monitoring latency is a must. Resource usage monitoring is important for capacity planning; data is needed for informed designs and scalability concerns.
- Accuracy. ML model predictions include accuracy, recall, and loss, among others, as metrics for confidence on inference. Monitoring these metrics over time provides insight into the quality of the models being pushed. Distinct from other data-driven services, you need metrics that are context-aware to monitor users’ happiness with ML. After the model makes a prediction, you must collect user feedback over the output. This feedback can be in the form of a user accepting a word suggested by a keyboard; a phrase suggested by a search engine’s autocomplete feature; a click on an “Up Next” video; or a brief dialog with the user (for example, “Good result?”). The software we are using for this article itself does this, asking for feedback as it offers suggestions for words and phrases as we type (see Figure 2).
Figure 2: Screen capture of an in-the-moment feedback mechanism, Google Docs 2020
The presence metric became especially important after a few different Google engineering teams conducted retrospectives for model rollouts, and found that in some cases a new model had been deployed but was not yet wired into the serving system—even though the model was available, the binary was not able to use it! In each case, after the teams added a step to their process to ensure that a model intended for production use was in fact serving (and added specific monitoring to verify this), user engagement rose visibly.
This presence metric is one example of a class of basic things that can go wrong with any ML system. Other examples of basic metrics that SREs should monitor include:
- Can the serving system load a model?
- Is a new model processing a similar rate of queries as the previous model?
- Is a newly trained model of a reasonable size? If the delta is beyond a certain threshold, say 5%, the system should raise an alert.
In order to measure the model accuracy, we suggest a more engaged approach: once the user has received an ML-based response, follow up by directly asking the user if the response was valuable. In the case of a photo-sharing application that identifies faces and tags them with names, ask the user for confirmation! The system can then feed this confirmation back into the training data for the model, and iteratively build new models from this. A similar approach takes place by measuring the number of autocorrect suggestions the user accepts in a system such as Gmail Smart Reply, which suggests three possible responses to an incoming email message.
ML models also need metrics for the performance of each model in the wild. Historical data guides the system in establishing a threshold, against which you evaluate the performance of subsequent models. A model accuracy graph can achieve this evaluation and help detect overfitting, where a model memorizes rather than generalizes. Although some practices such as statistical translation models identify memorization as a useful practice, we found that this does not apply to the larger data sets that make up “Big Data.” Overfitting is a common cause for degraded inferences, especially since overfit models typically perform well during testing on small input sets, but their accuracy drops during canary and production. This makes these degraded inferences easier to detect.
In his memoir Bitwise,17 the technologist David Auerbach observes a contemporary corollary of Occam’s razor. He states that “bizarre or offensive behavior is far more likely to be an accident than it is a consequence of the actual design of the algorithm.” Without intentional observation of the ML-based system and an examination of the system end-to-end, you cannot be certain that it accomplishes what you designed it to do. Engineers must deal with corner cases as they arise, either recommending changes to the underlying system within the pipeline or making behavioral modifications to the pipeline itself. These actions are the traditional responsibility of the SRE. Unusual for large systems, some of these cases may need human oversight in the form of quality evaluators. These evaluators take an early look at the models and predictions, and gauge them against reasonable outputs and their own individual expectations. We’ve seen that this process, in addition to automated testing, is a useful step to provide comprehensive quality control of models.
Conclusion
Machine learning has become a powerful tool for new features, for companies and large services alike. Companies are rapidly integrating ML into their products, and systems that use data models developed with ML offer exciting personalization features, which puts users first. ML-based services are becoming commonplace and readily available through cloud-based platforms, allowing novice and expert developers to use technology such as image-recognition through an API call.
Even though ML-based features are becoming ubiquitous, the industry lacks well-established methodologies to control how to productionize and properly deploy them. Therefore, we propose that engineers responsible for ML pipelines in production do the following:
- Define the training pipeline: check quality, take data snapshots, and provide clean, high-quality data
- Manage the model: Qualify and validate models, and ensure that the system can safely and reliably roll back models and other pipeline components
- Develop ML-specific instrumentation to monitor system attributes
These best practices make integrating ML into a production service more robust. Application developers can use a platform such as TensorFlow Extended (TFX), which encapsulates many of these behaviors and provides a turnkey toolkit for reliable ML deployments. We recommend using instrumentation and monitoring to provide insight into the behavior of your ML-based products. You can read more about this in “Practical Alerting from Time-Series Data.”18 A deep understanding of pipeline operations will also guide your ML operations, and the chapter on data processing pipelines19 in The Site Reliability Workbook provides a solid introduction to this topic.
Acknowledgments
This article draws on research conducted with Chris Farrar, Steven Ross, and Todd Underwood. The authors are grateful for the technical-writing guidance of Carmela Quinito and Jessie Yang; for the guidance from our colleagues at Google, Ben Appleton, Luis Quesada Torres, Andrew W. Moore; and for the suggestions from our external technical reviewers.
Footnotes
1 For this usage of the term postmortem, see Chapter 15, “Postmortem Culture: Learning from Failure,” in Site Reliability Engineering (Beyer et al., eds.), also known as the SRE book.
2 See https://support.google.com/photos/answer/6128838 or https://www.blog.google/products/photos/relive-your-best-memories-new-features-google-photos.
3 Breck, Eric, et al. 2019. “Data Validation for Machine Learning.” Proceedings of SysML. https://mlsys.org/Conferences/2019/doc/2019/167.pdf.
4 Dixon, Lucas, et al. 2018. “Measuring and Mitigating Unintended Bias in Text Classification.” Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society. https://www.aies-conference.com/2018/contents/papers/main/AIES_2018_paper_9.pdf.
5 Chapter 2, “Implementing SLOs,” of The Site Reliability Workbook (Beyer et al., eds.), also known as the SRE workbook.
6 For a detailed list of production best practices, including their motivations and outcomes, see Appendix B, “A Collection of Best Practices for Production Services,” of the SRE book.
7 Tools such as Automunge, https://github.com/Automunge/AutoMunge, provide this infill functionality.
8 This point is important enough that it’s in the Introduction to the SRE book.
9 Halevy, Alon, Peter Norvig, and Fernando Pereira. 2009. “The Unreasonable Effectiveness of Data.” IEEE Intelligent Systems 24 (1). https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/35179.pdf.
10 McCloskey, Michael and Neal H. Cohen. 1989. “Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem.” Psychology of Learning and Motivation 24: 109-165. https://www.sciencedirect.com/science/article/pii/S0079742108605368.
11 Wikipedia provides an overview of these methods.
12 See Chapter 2, “Implementing SLOs,” of the SRE workbook.
13 Canarying in systems means pushing code changes to a limited number of users to validate that the new changes do not break the system. Chapter 17, “Testing for Reliability,” of the SRE book discusses this in depth.
14 See Chapter 16, “Canarying Releases,” of the SRE workbook.
15 See Chapter 17, “Testing for Reliability,” in the SRE book.
16 Ewaschuk, Rob. 2016. “Monitoring Distributed Systems.” O’Reilly Radar. https://www.oreilly.com/radar/monitoring-distributed-systems.
17 Auerbach, David. 2018. Bitwise: A Life in Code. New York: Knopf Doubleday Publishing Group. https://www.penguinrandomhouse.com/books/538364/bitwise-by-david-auerbach/
18 See Chapter 10, “Practical Alerting,” from the SRE book.
19 See Chapter 13, “Data Processing Pipelines,” from the SRE workbook.
This post is part of a collaboration between O’Reilly and Google. See our statement of editorial independence.