A real-time tool for a real-time problem
Using VoltDB and the Lambda Architecture to locate abnormal behavior.
Subscriber Identity Module box (SIMbox) fraud is a type of telecommunications fraud where users avoid an international outbound-calls charge by redirecting the call through voice over IP to a SIM in the country where the destination is located. This is an issue we helped a client address at Wise Athena.
Taking on this type of problem requires a stream-based analysis of the Call Detail Record (CDR) logs, which are typically generated quickly. Detecting this kind of activity requires in-memory computations of streaming data. You might also need to scale horizontally.

Learn faster. Dig deeper. See farther.
We recently evaluated the use of VoltDB together with our cognitive analytics and machine-learning system to analyze CDRs and provide accurate and fast SIMbox fraud detection. At the beginning, we used batch processing to detect SIMbox fraud, but the response time took too long, so we switched to a technology that allows in-memory computations in order to reach the desired time constraints.
VoltDB’s in-memory distributed database provides transactions at streaming speed in a fast environment. It can support millions of small transactions per second. It also allows streaming aggregation and fast counters over incoming data. These attributes allowed us to develop a real-time analytics layer on top of VoltDB.
The following social graphs visualize the difference between legitimate networks (image on the left) and fraudsters (image on the right).
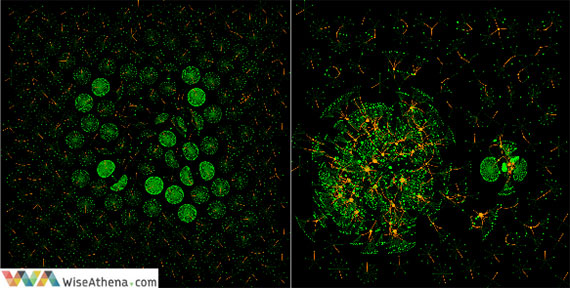
We used VoltDB to compute and maintain the calling patterns of each user in-memory. As the next step, we applied computed summaries to generate predictions in near-real time using thousands of decision trees (which had been previously trained with known fraud instances) to identify this abnormal behavior. The problem can be mitigated by doing this classification only over new or relatively new subscribers, since we do not expect a user with enough legitimate history to became a fraudster. The idea is to compute from the incoming CDRs per each user an in-memory digest of summary statistics and store the complete history in a disk-based database for batch operations.
When analyzing fast data, you can take two different approaches:
- Store data in disk and run parallel algorithms using Hadoop or Spark with enough machines, scaling the process to a desired level.
- Compute the online summaries of the input data in the real-time layer and store the input data in the batch layer (this is commonly known as Lambda Architecture, a term coined by Nathan Marz).
Following the latter approach, we built an in-memory computation of summaries that we later applied to detect abnormal behavior using VoltDB. First, we started an empty VoltDB database:
$>voltdb create
Then we loaded the following table’s definitions and stored procedures into VoltDB:
CREATE TABLE cdr_traffic ( Cell_start INTEGER, Source_num VARCHAR(32), Cell_end INTEGER, Dest_num VARCHAR(32), Event_date VARCHAR(10), Event_hour VARCHAR(8), Duration INTEGER, Imei VARCHAR(15), Type VARCHAR(3), Ts timestamp, Key_index VARCHAR(1) NOT NULL, ); PARTITION TABLE cdr_traffic on COLUMN Key_index; CREATE PROCEDURE ComputeCellDiversityPerNum AS SELECT Source_num, count(DISTINCT Cell_start) AS Uniq_cells FROM cdr_traffic WHERE Key_index =? AND Source_num =? GROUP BY Source_num; PARTITION PROCEDURE ComputeCellDiversityPerNum ON TABLE cdr_traffic COLUMN Key_index; CREATE PROCEDURE OutGoingUniqueCallsPerNum AS SELECT Source_num, count(DISTINCT Dest_num) AS Out_Uniq_Calls FROM cdr_traffic WHERE Key_index =? AND Source_num =? AND Type ='MOC' GROUP BY Source_num,Type; PARTITION PROCEDURE OutGoingUniqueCallsPerNum ON TABLE cdr_traffic COLUMN Key_index; -- similar procedures can be defined for other online summaries
By using the sqlcmd command:
$>sqlcmd < create_moc_table_procedures.sql
As you can see, the cdr_traffic table is partitioned on the column Key_index; — partitioning is one of the capabilities that VoltDB provides to allow faster computations.
In any stream-based application, the first step is to ingest the data into the system. In general, this can be done by using custom code that hooks directly into the data-generating API or by using a message queue (such as Kafka or rabbitmq) to gather the data. To simplify, we can use the VoltDB command csvloader to read the input data from disk and store into the cdr_traffic table.
$>csvloader --separator “|” --file 20150101.csv cdr_traffic
The next step is to perform the real-time computations over input data. This can be done in near-real time by using VoltDB custom stored procedures. On a different data workflow, complex analytics can be performed in batch mode by using the input data exported into a longer-term storage. So, streaming data is cleaned once, aggregated, joined in VoltDB, and accessed in near-real time to estimate the likelihood of the user being a SIMbox fraudster.
The two more relevant patterns used to detect SIMbox fraud are the disproportionate ratio of outgoing calls versus incoming calls, and zero or close-to-zero mobility. Mobile users generally make and receive calls at different locations — such as their homes, workplaces, etc. — in a regular and consistent pattern. By contrast, SIMboxes are mostly static because they consist of computer boxes with several SIM cards attached, and the fraud is performed at a given location. Therefore, legitimate users have more homogenous communication patterns and use multiple cell towers. When the input stream is ingested into VoltDB, several features should be computed, such as the user’s call diversity and mobility indicator.
Next, we executed the pre-defined procedures through an R script. The following snippet shows how to execute the ComputeCellDiversityPerNum procedure for a specific phone number through R and convert the result into a well-known data frame structure (other procedures can be accessed in similar ways):
request.proc <- c(Procedure = 'ComputeCellDiversityPerNum', Parameters = '["1", "9cdd45ce8cee1d400c4d11d28f398c11"]') cell.diversity <- getForm(volt.url, .params = request.proc) cell.diversity <- fromJSON(proc.result) cell.diversity <- unlist(proc.result$results[[1]]$data) dim(cell.diversity) <- c(1, 2) cell.diversity <- as.data.frame(cell.diversity)
In this way, it is possible to do feature computations through a combination of VoltDB procedures and custom R commands, and by using predictive models already trained with the fraud patterns. It is also necessary to flush the input stream data from time to time to avoid overflow problems; this can be done by a VoltDB client application, as in this VoltDB click stream processing example.
Conclusions
This post shows a specific use case of SIMbox fraud detection, but there are several scenarios that require similar stream-based analytics, such as sensors, machine-to-machine (M2M) devices, Internet of Things (IoT) platforms, and financial applications. Traditional databases and batch-processing approaches are not appropriate for streaming data, and it is better to use custom in-memory architectures. We found VoltDB to be a good choice for implementing Lambda Architectures because it enhances the traditional concept with ACID transactions at streaming speed and with the ability to perform SQL queries in the speed layer. Other in-memory databases such as Redis, Tokyo Cabinet, or Kyoto Cabinet can be used for similar purposes, but they are based on key-value NoSQL paradigm and don’t provide ACID transactions.
This post is a collaboration between O’Reilly and VoltDB. See our statement of editorial independence.