Accelerating big data analytics workloads with Tachyon
How Baidu combined Tachyon with Spark SQL to increase speed 30-fold
 Train approaches warp speed. (source: By Joe Lanman on Flickr.)
Train approaches warp speed. (source: By Joe Lanman on Flickr.)
As an early adopter of Tachyon, I can testify that it lives up to its description as “a memory-centric distributed storage system, enabling reliable data sharing at memory-speed, across cluster frameworks.” Besides being reliable and having memory-speed, Tachyon also provides a means to expand beyond memory to provide enough storage capacity.
As a senior architect at Baidu USA, I’ve spent the past nine months incorporating Tachyon into Baidu’s big data infrastructure. Since then, we’ve seen a 30-fold increase in speed in our big data analytics workloads. In this post, I’ll share our experiences and the lessons we’ve learned during our journey of adopting and scaling Tachyon.

Learn faster. Dig deeper. See farther.
Creating an ad-hoc query engine
Baidu is the biggest search engine in China, and the second biggest search engine in the world. Put simply — we have a lot of data. How to manage the scale of this data, and quickly extract meaningful information, has always been a challenge.
To give you an example, product managers at Baidu need to track top queries that are submitted to Baidu daily. They take the top 10 queries, and drill down to find out which province of China contributes the most information to the top queries. Product managers then analyze the resulting data to extract meaningful business intelligence.
Due to the sheer volume of data, however, each query would take tens of minutes, to hours, just to finish — leaving product managers waiting hours before they could enter the next query. Even more frustrating was that modifying a query would require running the whole process all over again. About a year ago, we realized the need for an ad-hoc query engine. To get started, we came up with a high-level of specification: the query engine would need to manage petabytes of data and finish 95% of queries within 30 seconds.
From Hive, to Spark SQL, to Tachyon
With this specification in mind, we took a close look at our original query system, which ran on Hive (a query engine on top of Hadoop). Hive was able to handle a large amount of data and provided very high throughput. The problem was that Hive is a batch system and is not suitable for interactive queries.
So, why not just change the engine?
We switched to Spark SQL as our query engine (many use cases have demonstrated its superiority over Hadoop Map Reduce in terms of latency). We were excited and expected Spark SQL to drop the average query time to within a few minutes. Still — it did not quite get us all the way. While Spark SQL did help us achieve a 4-fold increase in the speed of our average query, each query still took around 10 minutes to complete.
So, we took a second look and dug into more details. It turned out that the issue was not CPU — rather, the queries were stressing the network. Since the data was distributed over multiple data centers, there was a high probability that a query would hit a remote data center in order to pull data over to the compute center — this is what caused the biggest delay when a user ran a query. With different hardware specifications for the storage nodes and the compute nodes, the answer was not as simple as moving the compute nodes to the data center. We decided we could solve the problem with a cache layer that buffered the frequently used data, so that most of the queries would hit the cache layer without leaving the data center.
A high-performance, reliable cache layer
We needed a cache layer that could provide high performance and reliability, and manage a petabyte-scale of data. We developed a query system that used Spark SQL as its compute engine, and Tachyon as a cache layer, and we stress tested for a month. For our test, we used a standard query within Baidu, which pulled 6TB of data from a remote data center, and then we ran additional analysis on top of the data.
The performance was amazing. With Spark SQL alone, it took 100-150 seconds to finish a query; using Tachyon, where data may hit local or remote tachyon nodes, it took 10-15 seconds. And if all of the data was stored in Tachyon local nodes, it took about five seconds, flat — a 30-fold increase in speed. Based on these results, and the system’s reliability, we built a full system around Tachyon and Spark SQL.
Tachyon + Spark SQL
The anatomy of the system:
- Operation Manager: A persistent Spark application that wraps Spark SQL. It accepts queries from query UI, and performs query parsing and optimization.
- View Manager: Manages cache metadata and handles query requests from the operation manager.
- Tachyon: Serves as a cache layer in the system and buffers the frequently used data.
- Data Warehouse: The remote data center that stores the data in HDFS-based systems.
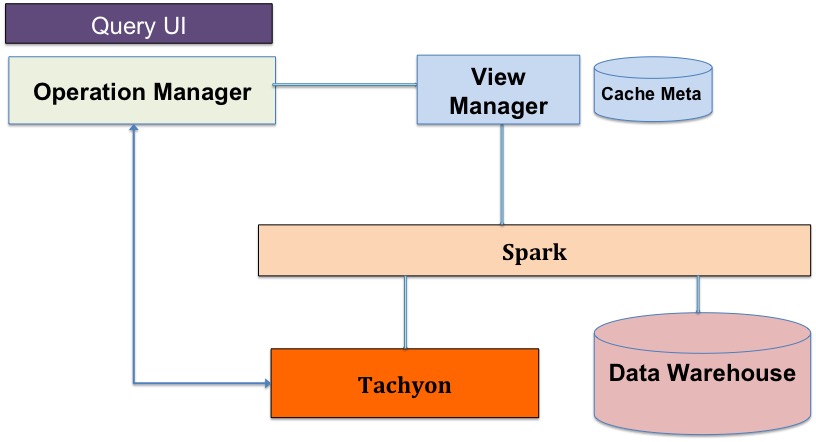
Now, let’s discuss the physiology of the system:
- A query gets submitted. The operation manager analyzes the query and asks the view manager if the data is already in Tachyon.
- If the data is already in Tachyon, the operation manager grabs the data from Tachyon and performs the analysis on it.
- If data is not in Tachyon, then it is a cache miss, and the operation manager requests data directly from the data warehouse. Meanwhile, the view manager initiates another job to request the same data from the data warehouse and stores the data in Tachyon. This way, the next time the same query gets submitted, the data is already in Tachyon.
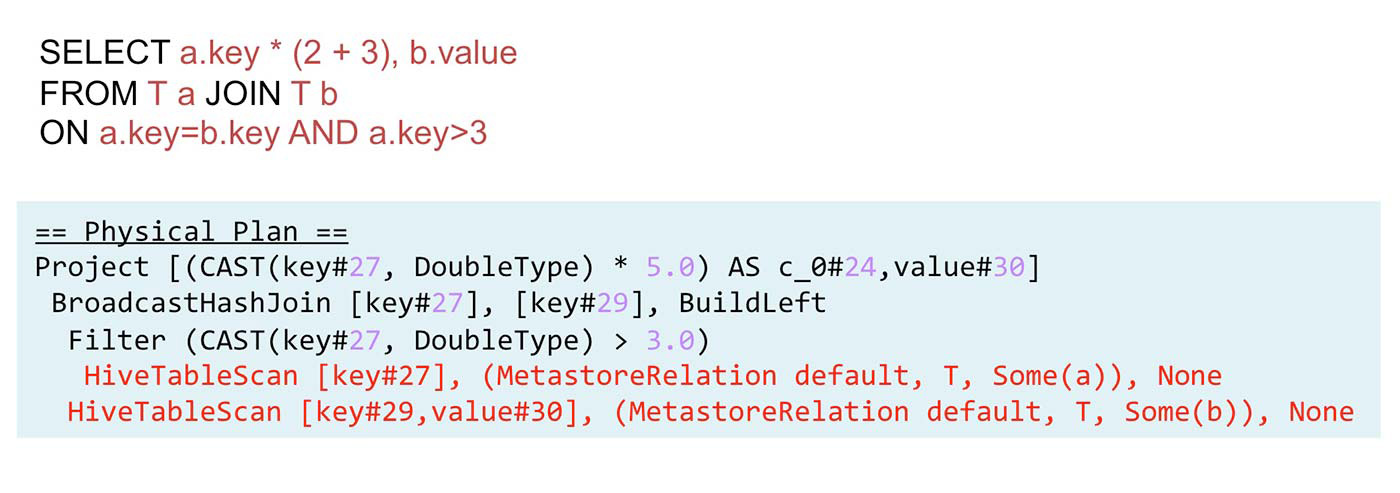
How to get data from Tachyon
After the Spark SQL query analyzer (Catalyst) performs analysis on the query, it sends a physical plan, which contains HiveTableScan statements. These statements specify the address of the requested data in the data warehouse. The HiveTableScan statements identify the table name, attribute names, and partition keys. Note that the cache metadata is a key-value store, the <table name, partition keys, attribute names> tuple is the key to the cache metadata, and the value is the name of the Tachyon file. So, if the requested <table name, partition keys, attribute names> combination is already in cache, we can simply replace these values in the HiveTableScan with a Tachyon file name, and then the query statement knows to pull data from Tachyon instead of the data warehouse.
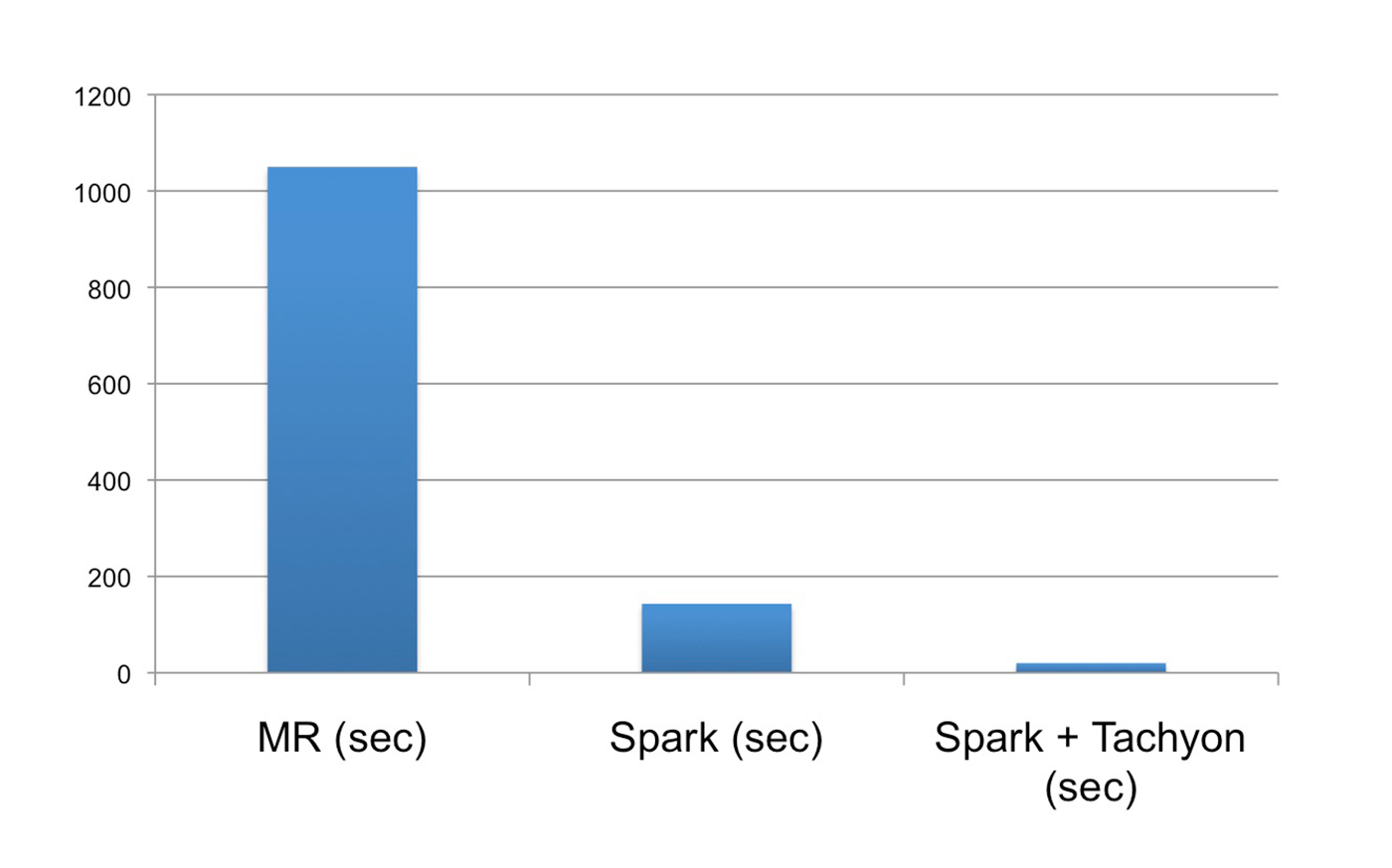
Performance and deployment
With the system deployed, we also measured its performance using a typical Baidu query. Using the original Hive system, it took more than 1,000 seconds to finish a typical query. With the Spark SQL-only system, it took 150, and using our new Tachyon + Spark SQL system, it took about 20 seconds. We achieved a 50-fold increase in speed and met the interactive query requirements we set out for the project.
Today, the system is deployed in a cluster with more than 100 nodes, providing more than two petabytes of cache space, using an advanced feature (tiered storage) in Tachyon. This feature allows us to use memory as the top-level cache, SSD as the second-level cache, and HDD as the last-level cache; with all of these storage mediums combined, we are able to provide two petabytes of storage space.
Problems encountered in practice
Cache
The first time we used Tachyon, we were shocked — it was not able to cache anything! What we discovered was that Tachyon would only cache a block if the whole block was read into Tachyon. For example, if the block size was 512 MB, and you read 511 MB, the block would not cache. Once we understood the mechanism, we developed a work-around. The Tachyon community is also developing a page-based solution so that the cache granularity is 4KB instead of the block size.
Locality
The second problem we encountered was when we launched a Spark job, the Spark UI told us that the data was node-local, meaning that we should not have to pull data from remote Tachyon nodes. However, when we ran the query, it fetched a lot of data from remote nodes. We expected the local cache hit rate to be 100%, but when the actual hit rate was about 33%, we were puzzled.
Digging into the raw data, we found it was because we used an outdated HDFS Input Format, meaning that if we requested block 2 for the computation, it would pull a line from block 1 and a line from block 3, even though you didn’t need any data from block 1 or 3. So, if block 2 was in the local Tachyon node, then blocks 1 and 3 may be in remote Tachyon nodes — leading to a local cache hit rate of 33% instead of 100%. Once we updated our input format, this problem was resolved.
SIGBUS
Sometimes we would get a SIGBUS error, and the Tachyon process would crash. Not only Tachyon, but Spark had the same problem, too. The Spark community actually has a work-around for this problem that uses fewer memory-mapped files, but that was not the real solution. The root cause of the problem was that we were using Java 6 with the CompressedOOP feature, which compressed 64-bit pointers to 32-bit pointers, to reduce memory usage. However, there was a bug in Java 6 that allowed the compressed pointer to point to an invalid location, leading to a SIGBUS error. We solved this problem by either not using CompressedOOP in Java 6, or simply updating to Java 7.
Time-To-Live feature and what’s next for Tachyon
In our next stage of development, we plan to expand Tachyon’s functionalities and performance. For instance, we recently developed a Time-To-Live (TTL) feature in Tachyon. This feature helps us reduce Tachyon cache space usage automatically.
For the cache layer, we only want to keep data for two weeks (since people rarely query data beyond this point). With the TTL feature, Tachyon is able to keep track of the data and delete it once it expires — leaving enough space for fresh data. Also, there are efforts to use Tachyon as a parameter server for deep learning (Adatao is leading the effort in this direction). As memory becomes cheaper, I expect to see the universal usage of Tachyon in the near future.
To learn more about how Tachyon helped improve the efficiency of big data analytics within Baidu, join us at Strata + Hadoop World Singapore in December 2015 and attend the session on Fast big data analytics with Spark on Tachyon in Baidu.