Accelerating Spark workloads using GPUs
Transparent matching of Spark portability with GPU performance.
 Warp speed. (source: Pixabay)
Warp speed. (source: Pixabay)
Spark has emerged as the infrastructure of choice for developing in-memory distributed analytics workloads. It provides high-level abstractions in multiple languages (e.g., Java, Scala, and Python) that hide the underlying data and work distribution operations such as data transfer to and from the Hadoop Distributed File System (HDFS) or that maintain resiliency in the presence of system failures. Spark also provides libraries for relational Online Analytical Processing (OLAP) using SQL, machine learning, graph analytics, and streaming workloads. These features enable developers to build complex analytics workflows quickly to support different data sources in various operating environments.
Spark supports both computationally and memory-intensive in-memory workloads. Computationally intensive workloads include machine learning applications that use a variety of sparse and dense matrix algorithms and OLAP applications that use aggregation functions (e.g., MIN, MAX, or AVG over large numerical datasets. Memory-intensive workloads include traversal-based graph analytics algorithms and relational query processing. Both types of workloads provide ample opportunities for acceleration using software and hardware approaches. Because Spark’s primary design focus is on providing ease-of-use for application developers, any acceleration approach needs to balance performance with productivity.

Learn faster. Dig deeper. See farther.
This post describes an approach for accelerating Spark applications using GPUs. Because GPUs provide both high-memory bandwidth and high-compute capabilities, we can use them to accelerate both computationally and memory-intensive Spark workloads.
There are three key approaches for integrating GPUs in the Spark ecosystem:
- Use GPUs for accelerating Spark libraries and operations without changing interfaces and the underlying programming model.
- Automatically generate native GPU code from high-level Spark source code written in Scala or Java.
- Integrate Spark with an external GPU-accelerated system.
These three approaches have their own pros and cons: although the automatic code-generation approach provides the maximum flexibility, generating optimized GPU code from a Java/Scala source fragment is not a trivial task. The compiler needs to consider various issues, such as auto-parallelizing source kernels and optimizing for the target GPU, managing multi-GPU execution, and supporting computations on large data sets. Integrating with an already GPU-accelerated system (e.g., a deep learning system such as Caffe) is the easiest way to integrate GPU code; however, in this scenario, the Spark system has no control over GPU resources and is used primarily for managing input/output data. The final approach of accelerating Spark libraries and operations enables transparent exploitation of GPUs without modifying existing Spark interfaces. This allows existing Spark programs to use GPUs without changing a single line of code. However, this approach requires building GPU-accelerated versions of different algorithms. Our implementation follows the third approach, integrating Spark with an external GPU-accelerated system, and uses this approach for implementing key Spark library functions.
We focus on accelerating entire kernels, rather than accelerating individual functions. Initially, we target key kernels from the analytics/machine learning domains from Spark ML and MLlib packages (noted in green in Figure 1). In the analytics domain, our current focus is on regression (e.g., logistic regression, Elastic Net, Lasso, etc.), distributed optimization (e.g., ADMM), factorization (e.g., ALS, NNMF, and PCA), natural language processing (e.g., Word2vec) and nearest neighbor similarity searches.
We have also started exploring kernels from the deep learning (e.g., Dataframe-based tensors, and gradient descent learning), graph analytics using GraphX (e.g., breadth-first/depth-first search and link prediction ), and relational OLAP using Spark SQL (noted in blue in Figure 1). All of our modifications are implemented without changing the top-level interfaces. To use the GPU-accelerated versions of the library kernels, users need to activate a Spark systems variable. This variable triggers the library code to invoke the GPU-accelerated routines. We follow the Spark execution model and rely on the Spark runtime to distribute the data into partitions. Our implementation assumes a Spark workload with multiple executors, each with multiple threads, executing on a cluster of compute nodes, each connected to one or more GPUs (Figure 2).
The GPUs are accessible only to the executors running on the owner compute node. On a compute node, partitions from different executors are mapped independently in round-robin manner over the GPUs. Currently, we do not support concurrent execution of partitions on the same GPU. Each partition invokes one or more GPU functions. We have implemented our GPU functions using the Nvidia CUDA framework (we use both native CUDA code and libraries such as cuBLAS and cuSPARSE). The GPU functions operate on the data stored in a non-heap memory; the data is copied into a GPU’s device memory during function invocation. Currently, we assume that the data required for a GPU function can be stored in the GPU’s device memory. For scenarios that involve large memory footprints, we increase the number of partitions so that the per-partition memory footprint is less than the GPU’s device memory size. Data generated by the GPU functions on the device memory can persist on the device memory and can be reused by different GPU functions.
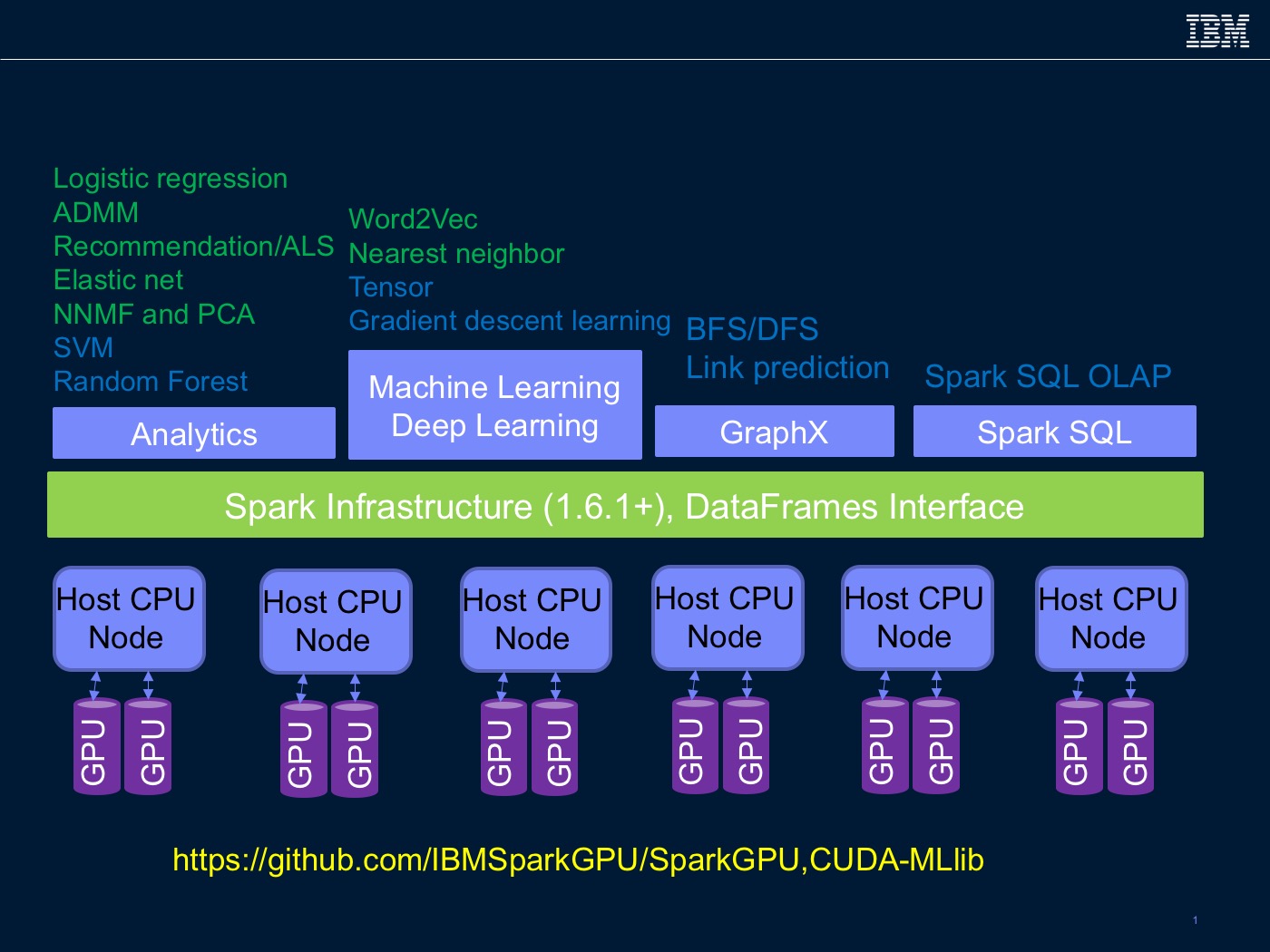
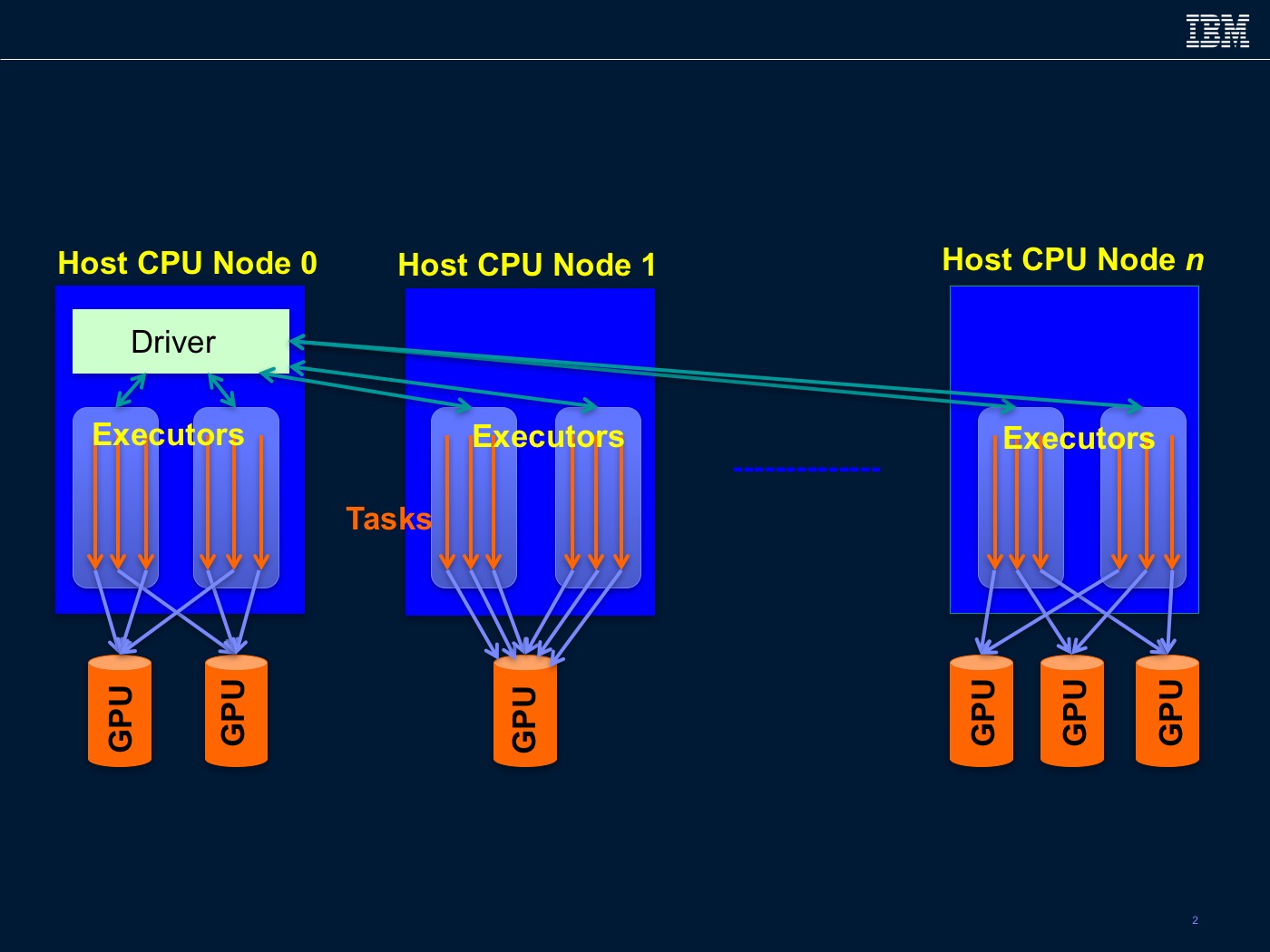
Figure 1 presents the current set of Spark libraries that will be accelerated using GPUs. In addition to the traditional machine learning/analytics libraries, we are also exploring how to accelerate Spark-based deep learning, graph analytics, and relational OLAP. From this set, we have released the code for logistic regression (L-BFGS-based training and prediction) and ALS algorithms on GitHub. The modified Spark code (based on a fork of the Spark master branch) is available in the Spark-GPU repository, and the CUDA code for the Logistic Regression and ALS algorithms are available in the CUDA-MLlib repository. For both these algorithms, the GPUs were able to speed up significantly over original code, demonstrating a more than 30-times gain for Logistic Regression training and a 6-times gain for the ALS algorithm. In both cases, we observed that the overall performance gain is affected by non–GPU Spark components of the implementation. We also observed that in most cases, the Spark runtime system generated more partitions than the available GPUs and resulted in unnecessary GPU invocations.
In general, we observed that to get the full benefit of GPU acceleration, Spark’s current execution models need to be extended to enable seamless integration of GPUs into the Spark environment. Specifically, the following open issues need to be addressed:
- Integrated Resource Management: The Spark ecosystem is designed as a homogeneous distributed system. Spark’s resource and cluster managers currently have no visibility of the GPU resources. These need to be updated to manage load balancing, access control, and job scheduling on the GPU resources.
- Spark Partition Management: Spark currently uses CPU core information to determine the number of data partitions to distribute the work. The number of GPUs is usually smaller than the number of cores in a traditional multi-socket multi-core system. However, each GPU can concurrently execute multiple kernels, each using a large number of threads. Therefore, a different strategy is needed to determine the number of partitions for the tasks executing on the GPUs.
- GPU Data Persistence Issues: With GPUs in the mix, Spark has to consider two different memory regions: CPU (host) memory and GPU device memory. Functions executing on the GPUs allocate their own memory regions, with lifetimes different than the data allocated on the host memory. In addition, multiple functions can reuse memory regions across invocations. The Spark execution model needs to be aware of the differences between host and GPU device memories and determine their persistence characteristics.
- GPU-Specific Data Layout: Because GPUs operate only on vectors, it is imperative that complex data structures are laid out properly in memory. Currently, users cannot control how a data structure is laid out. The Spark execution model needs to be extended to incorporate specialized memory layout such as the columnar layout used in Spark Parquet and IBM’s GPUEnabler package.
To summarize, we believe that as Spark continues to gain momentum, there will be increasingly more workloads that can be accelerated using GPUs. As our experience has demonstrated, GPUs provide significant gains for key machine learning workloads. In addition, software and hardware features from the upcoming GPU models—specifically, faster CPU–GPU interconnect fabric called NVLink—and better support for unified virtual memory will alleviate some of the limitations of the current implementation (e.g., memory footprint limited to the GPU’s device memory). In addition to the traditional analytics/machine learning domains, we see a huge potential for GPU acceleration in a variety of other Spark domains—for example, graph analytics and relational OLAP. We believe that seamless integration of GPUs into Spark would enable wider use of Spark (e.g., in high-performance computing applications). To achieve broader application of GPUs in the Spark ecosystem, wider community involvement is needed.