Apache Hadoop 2.0 represents a generational shift in the architecture of Apache Hadoop. With YARN, Apache Hadoop is recast as a significantly more powerful platform – one that takes Hadoop beyond merely batch applications to taking its position as a ‘data operating system’ where HDFS is the file system and YARN is the operating system.
YARN is a re-architecture of Hadoop that allows multiple applications to run on the same platform. With YARN, applications run “in” Hadoop, instead of “on” Hadoop:
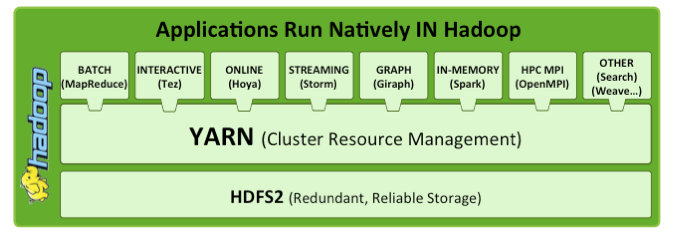
The fundamental idea of YARN is to split up the two major responsibilities of the JobTracker and TaskTracker into separate entities. In Hadoop 2.0, the JobTracker and TaskTracker no longer exist and have been replaced by three components:
- ResourceManager: a scheduler that allocates available resources in the cluster amongst the competing applications.
- NodeManager: runs on each node in the cluster and takes direction from the ResourceManager. It is responsible for managing resources available on a single node.
- ApplicationMaster: an instance of a framework-specific library, an ApplicationMaster runs a specific YARN job and is responsible for negotiating resources from the ResourceManager and also working with the NodeManager to execute and monitor Containers.
The actual data processing occurs within the Containers executed by the ApplicationMaster. A Container grants rights to an application to use a specific amount of resources (memory, cpu etc.) on a specific host.
YARN is not the only new major feature of Hadoop 2.0. HDFS has undergone a major transformation with a collection of new features that include:
- NameNode HA: automated failover with a hot standby and resiliency for the NameNode master service.
- Snapshots: point-in-time recovery for backup, disaster recovery and protection against use errors.
- Federation: a clear separation of namespace and storage by enabling generic block storage layer.
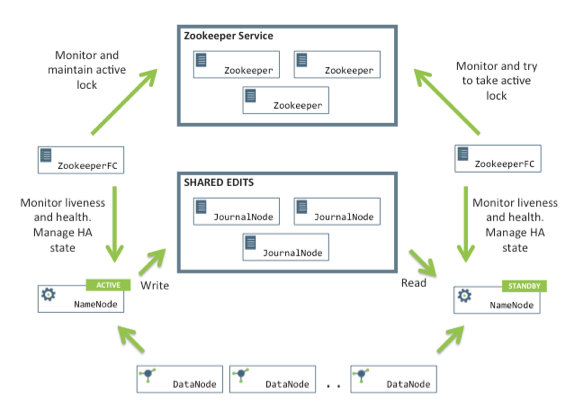
NameNode HA is achieved using existing components like ZooKeeper along with new components like a quorum of JournalNodes and the ZooKeeper Failover Controller (ZKFC) processes:
Federation enables support for multiple namespaces in the cluster to improve scalability and isolation. Federation also opens up the architecture, expanding the applicability of HDFS cluster to new implementations and use cases.
In our upcoming tutorial, we will discuss the details of YARN and provide an overview of how you might develop your own YARN implementation. We will also discuss the components of HDFS High Availability, how to protect your enterprise data with HDFS Snapshots, and how Federation can be used to utilize your cluster resources more effectively. We will also include a brief discussion on migrating from Hadoop 1.x to 2.0.
Tutorial attendees should be familiar with the basic components of Hadoop 1.x, and should bring pen and paper for taking notes.