

 Symphony of the Stones carved by the Goght River at Garni Gorge in Armenia is an example of an emergent natural structure. (source: Wikimedia Commons)
Symphony of the Stones carved by the Goght River at Garni Gorge in Armenia is an example of an emergent natural structure. (source: Wikimedia Commons) The GDELT Project, supported by Google Ideas, aims to create a real-time, open source index of the world’s news media, and to share that codified metadata with the world. The GDELT Project archives are among the world’s largest open data sets about global society. The complexity, growth rate, and analytic load pose unique challenges in terms of comprehension and accessibility of the data. GDELT’s diverse user community and application areas means there is little consistency in access patterns — queries may access tens of columns in a single analysis, negating the use of a traditional indexed database.
Due to the growing array of themes and emotions assessed from each article, the GDELT framework must be able to effectively store and access millions of dimensions per row. Additionally, a growing number of queries aim to discover macro-level patterns over the entire archive at scale. Because even routine queries may require sophisticated algorithms be applied to terabytes of data, in-database execution is a necessity.
As an open data initiative, the goal of the GDELT Project is to make its data instantly and freely open to the world. Yet, the unique size and characteristics of this data make it difficult to share. We turned to Google’s BigQuery platform to help users access and query this constantly growing database. This post will discuss how GDELT and BigQuery work together to address the unique data analytics challenges of real-time exploration of the world’s news media.
What is the GDELT Project?
The GDELT Project uses a massive inventory of the world’s news media, developed in collaboration with partners across the globe, to perform real-time monitoring of every accessible print, broadcast, and online news report around the globe, with a special emphasis on local news in local languages. Every article GDELT monitors is first machine-translated into English (a small selection of material is human-translated), then processed using a vast pipeline of algorithms. These algorithms are capable of identifying hundreds of categories of events (from protests to peace appeals), thousands of emotions (from anxiety to excitement), millions of narrative themes (from women’s rights to clean water access), as well as locations, people, organizations, and other indicators.
This codified metadata (but not the actual text of the articles) is then released as an open data stream, updated every 15 minutes, providing a multilingual annotated index of the world’s news. Lending context to this real-time data stream is an array of identically processed historical archives, including a 70-year archive of 21 billion words of academic literature encompassing JSTOR, DTIC, and the Internet Archive’s 1.7 billion PDF collection; 50 years of the world’s human rights reports; half a million hours of American television news; and 200 years of books.
What is Google BigQuery?
Google BigQuery is a cloud-based analytics database, built for enormous data sets like GDELT’s. It uses Google’s infrastructure to enable interactive SQL queries against multi-petabyte data sets and archives with tens of trillions of rows. Queries are submitted through a REST API and expressed in standard SQL that can be extended through user-defined JavaScript functions for advanced queries. Several hundred terabytes of new data (batch and streaming) are loaded into BigQuery each day by its customers, which are instantly available for querying. Thousands of processors can be brought to bear on a single query, returning rapid results without the need for data indexing or partitioning.
How GDELT is using Google BigQuery to overcome big data challenges
Given the tremendous volume and variety of GDELT data sets, questions of accessibility arise. What is the best way to share a database of trillions of data points, ranging from a traditional table of 310 million rows and 59 columns to highly fluid tables containing millions of effective dimensions per row times hundreds of millions of rows, all of it growing in real time? Though all of the data is available as downloadable CSV files, few users have the disk and processing power to download terabytes of data, and effectively query and analyze it. This is where Google’s BigQuery platform proved to be uniquely suited to GDELT’s needs.
The following features of BigQuery enable users to efficiently interact with GDELT data sets:
- Scalability and flexibility: GDELT’s data sets collectively encode tens of trillions of data points in multiple formats. Some data streams, like catalogs of events, such as protests or peace appeals, have highly structured schemas purpose-built for use with RDBMS systems and optimized over decades of use. Other streams, like catalogs of narratives and emotions, represent fundamentally new applications of metadata designed for use at extremely small scales — there is little precedent in encoding at these scales. Adding to the complexity, the number of dimensions to be assessed is constantly growing, requiring a fluid schema capable of constant expansion. Each assessed dimension must encode numeric information, such as its relative proximity to other information, or its intensity. This requires a flexible data format that supports complex nesting, numeric values, and constant expansion, which BigQuery provides.
- Constant addition of new columns: One of GDELT’s data sets involves identifying the presence, context, and intensity of millions of themes and thousands of emotions from each monitored news report. The list of themes and emotions is constantly growing over time, requiring the ability to query and analyze what is effectively millions of dimensions per row, each of which must store numeric values associated with the score. GDELT makes use of BigQuery’s advanced regular expression support for storing data in nested delimited formats and extracting selected values at query time.
- Combined real-time and historic data: Patterns emerging from GDELT’s real-time updates can be considered within the context of historical archives to determine their importance, relevance, and underlying driving forces. Because real-time updates must become available immediately to enable analysis of breaking events, an environment that allows unified querying across both real-time and historical data stores is necessary, which BigQuery supports through streaming inserts.
- Adhoc index-free search over many columns: One of GDELT’s data sets is a 37-year-old archive of global events totaling more than 310 million rows and 59 columns. Queries typically combine many columns, with each query accessing a different combination of columns. No single column or set of columns offers sufficient reducing power, making it impossible to use a traditional indexed RDBMS model and instead requiring an index-free query processing model like that used by BigQuery.
- Public access: All GDELT data streams are freely available as open data. This means it needs to run on a platform that separates resources related to data hosting and management from those related to querying. BigQuery allows datasets to be made publically accessible.
- Advanced computation: GDELT queries often involve sophisticated logic, such as pairing themes with locations in a given document, potentially requiring the processing of terabytes of data to output a final geographic histogram for mapping. As such, GDELT needs to be able to execute equally sophisticated control flows and algorithms entirely within the database platform itself, bringing the computation to the data. BigQuery’s user-defined functions make this possible.
- Whole-of-data in-database analysis: In addition to the more traditional analyses outlined above, certain kinds of analyses require the ability to effectively analyze the entire database against itself. For example, examining cycles and patterns of history as expressed in news media requires the ability to cross-correlate the entire database in a moving window, necessitating transparent computational and data movement scaling. The massive number of processors needed for such analysis requires a cloud-hosted environment like BigQuery.
BigQuery and GDELT at work
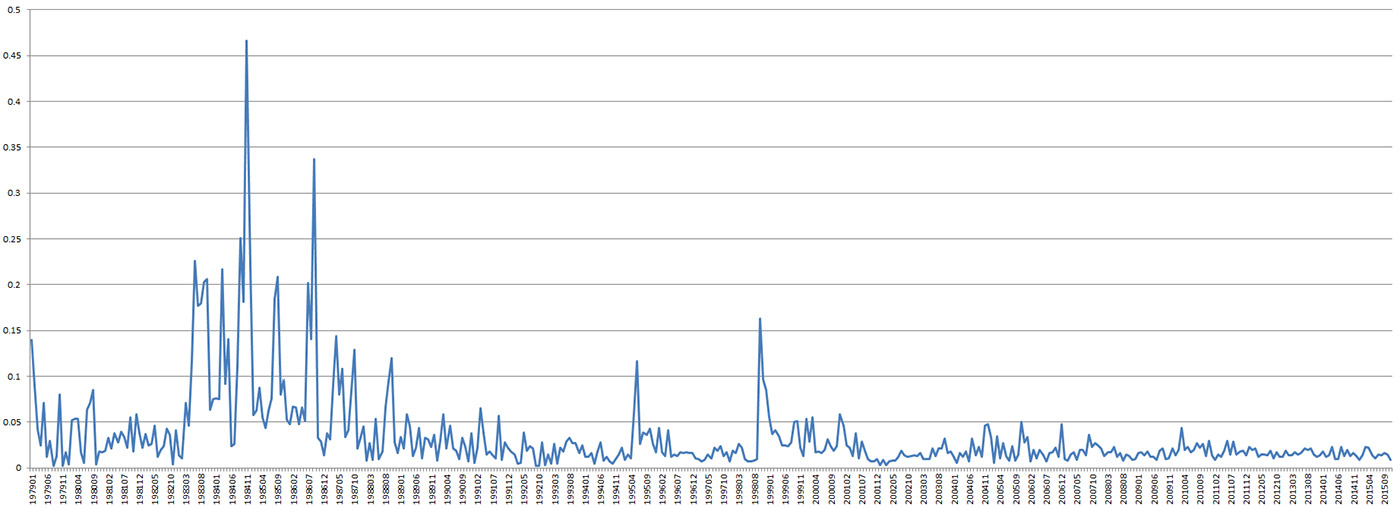
BigQuery makes it possible to explore GDELT’s massive archives in near real time, interactively querying, analyzing, and visualizing its insights. Often, BigQuery is used to examine longitudinal trends in protests or conflicts within a nation, placing current unrest in its historical context. For example, the graph below shows instability in Chile since 1979, highlighting the uprising against the Pinochet regime from 1983 to 1988, his arrest a decade later in October 1998, and the relative stability of the country since. An identical approach was used recently to compare protest trends across the European Union over the last four decades. What makes this kind of analysis so powerful is the ability to look across millions of global events spanning decades and quickly generate a quantitative timeline of the stability of a particular country, showing precisely its ebbs and flows of unrest.
Another GDELT data set records all people, organizations, locations, themes, and emotions found in each monitored news article and constructs a massive metadata index with this information. With just a single line of SQL, BigQuery scanned 150 million news records to compile a list of the top 1,500 pairs of names mentioned most frequently together in news coverage of the Greek bailout referendum. This action was performed in seconds. BigQuery then output a CSV file designed for visualizing with Gephi to produce the network diagram below. This type of diagram allows users to quickly explore how a particular topic has been presented by the world’s news media, who the central figures are, and how they are being related to one another. In this case, the pivotal roles of EU leaders like Angela Merkel and Wolfgang Schaeuble of Germany, Jean-Claude Juncker of Luxembourg, and Francois Hollande of France are all clearly visible.

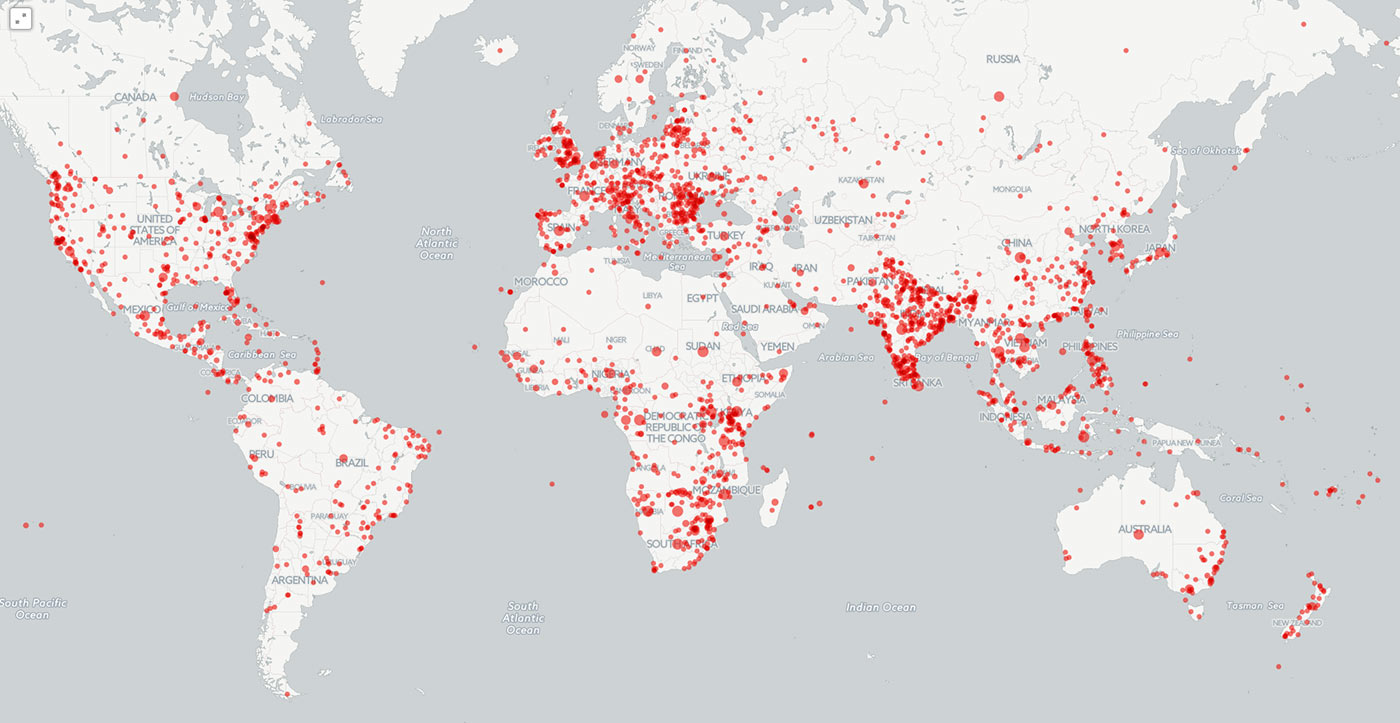
Another way in which GDELT commonly uses BigQuery is to map locations that appear in context with specific topics. BigQuery’s user-defined functions capability allows arbitrarily complex JavaScript applications — such as nested loops and complex filtering that associates each theme with its nearest location in a document — to be run as part of a query, enabling the entire analytic pipeline to run exclusively in BigQuery. In the graphic below, all locations mentioned in context with wildlife crime between February and June 2015 are mapped using CartoDB. This map has been used to communicate just how widespread wildlife crime has become. Other maps generated by GDELT and BigQuery include locations in context with anti-tank weapons, climate change, 200 years of books, the Greek debt crisis, and even the Islamic State.
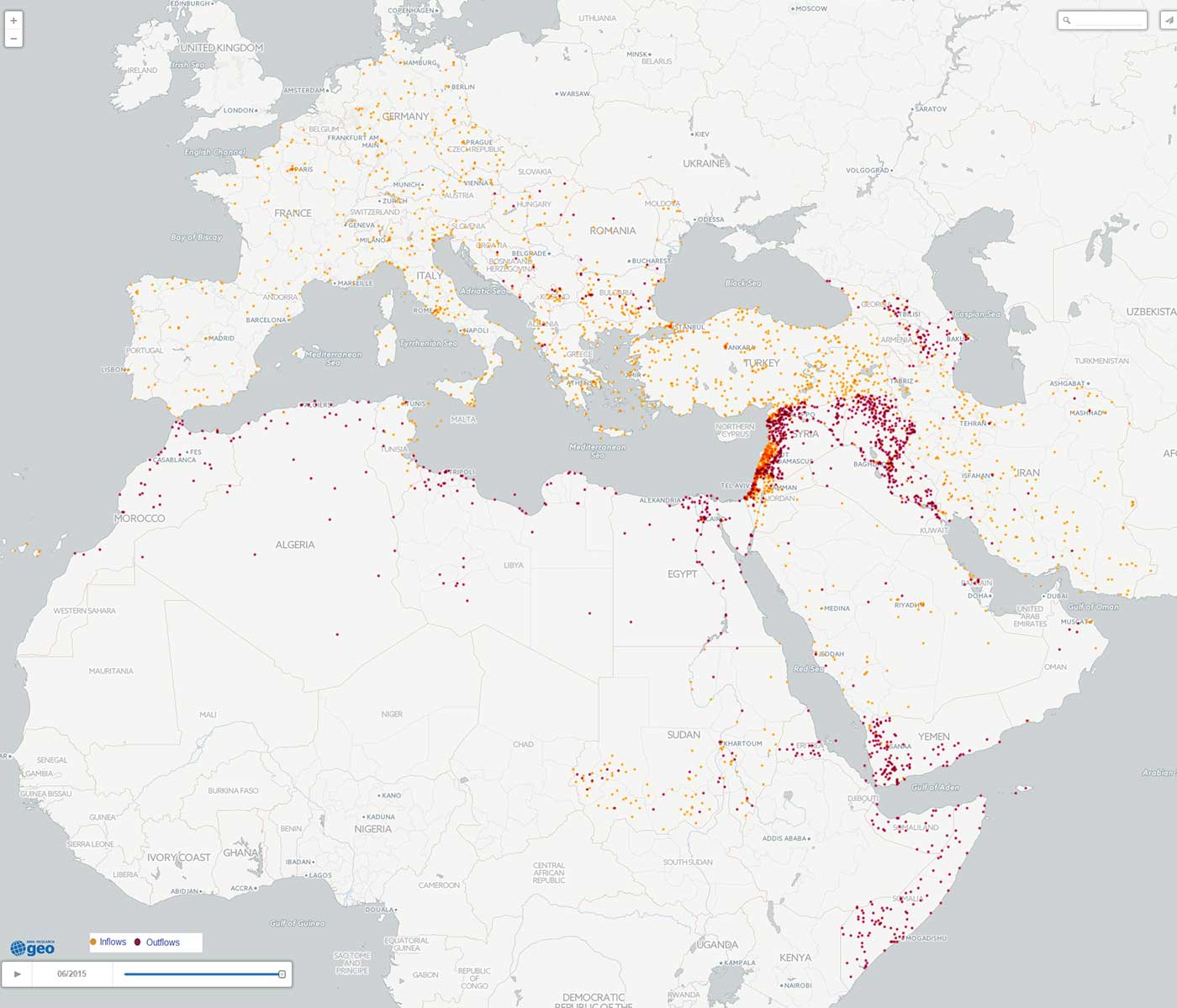
The research staff in Banco Bilbao Vizcaya Argentaria (BBVA)’s Cross-Country Emerging Markets Unit has produced a number of analyses with GDELT using BigQuery, ranging from a map of the current European refugee crisis, shown below, to more complex modeling of social unrest dynamics. In the map below, BBVA traces the geographic inflows (orange) and outflows (red) of refugees across Europe and North Africa in the first six months of this year. Maps like this, which surface trends found across millions of news reports, offer critical insights into the scale and geographic distribution of emerging crises that have potential to trigger significant instability and unrest.
The future of research
The GDELT Project is comprised of a highly diverse assembly of data schemas, coupled historical and real-time queries, in-database computation, and open access data sets holding tens of trillions of data points. To us, this is the future of research for traditionally “small data” fields like the social sciences, as they begin embrace big data — cloud services, such as BigQuery, will transparently handle scaling and data management, allowing researchers to focus on answering the questions that drive new insight and inspire innovation.