Building and deploying large-scale machine learning pipelines
We need primitives, pipeline synthesis tools, and most importantly, error analysis and verification.
 Motor Manufacturing (source: BiblioArchives)
Motor Manufacturing (source: BiblioArchives)
There are many algorithms with implementations that scale to large data sets (this list includes matrix factorization, SVM, logistic regression, LASSO, and many others). In fact, machine learning experts are fond of pointing out: if you can pose your problem as a simple optimization problem then you’re almost done.
Of course, in practice, most machine learning projects can’t be reduced to simple optimization problems. Data scientists have to manage and maintain complex data projects, and the analytic problems they need to tackle usually involve specialized machine learning pipelines. Decisions at one stage affect things that happen downstream, so interactions between parts of a pipeline are an area of active research.

Learn faster. Dig deeper. See farther.

In his Strata+Hadoop World New York presentation, UC Berkeley Professor Ben Recht described new UC Berkeley AMPLab projects for building and managing large-scale machine learning pipelines. Given AMPLab’s ties to the Spark community, some of the ideas from their projects are starting to appear in Apache Spark.
Identify and build primitives
The first step is to create building blocks. A pipeline is typically represented by a graph, and AMPLab researchers have been focused on scaling and optimizing nodes (primitives) that can scale to very large data sets. Some of these primitives might be specific to particular domains and data types (text, images, video, audio, spatiotemporal) or more general purpose (statistics, machine learning). A recent example would be ml-matrix — a distributed matrix library that runs on top of Apache Spark.

Casting machine learning models in terms of primitives makes these systems more accessible. To the extent that the nodes of your pipeline are “interpretable,” resulting machine learning systems are more transparent and explainable than methods relying on black boxes.
Make machine learning modular: simplifying pipeline synthesis
While primitives can serve as building blocks, one still needs tools that enable users to build pipelines. Workflow tools have become more common, and these days, such tools exist for data engineers, data scientists, and even business analysts (Alteryx, RapidMiner, Alpine Data, Dataiku).
As I noted in a recent post, we’ll see more data analysis tools that combine an elegant interface with a simple DSL that non-programmers can edit. At some point, DSL’s to encode graphs that represent these pipelines will become common. The latest release of Apache Spark (version 1.2) comes with an API for building machine learning pipelines (if you squint hard enough, it has the makings of a DSL for pipelines).
Do some error analysis
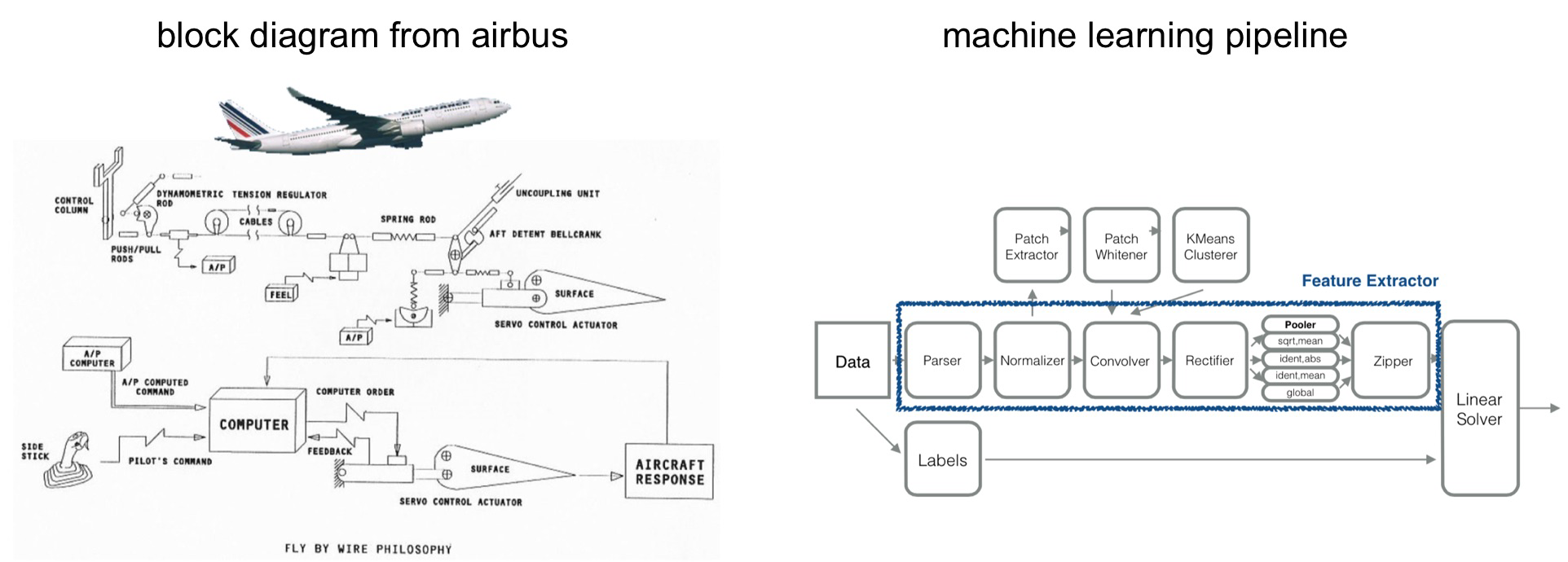
“We’re trying to put (machine learning systems) in self-driving cars, power networks … If we want machine learning models to actually have an impact in everyday experience, we’d better come out with the same guarantees as one of these complicated airplane designs.” —

{kind=link}
Can we bound approximation errors and convergence rates for layered pipelines? Assuming we can can compute error bars for nodes, the next step would be to have a mechanism for extracting error bars for these pipelines. In practical terms, what we need are tools to certify that a pipeline will work (when deployed in production) and that can provide some measure of the size of errors to expect.
To that end Laurent Lessard, Ben Recht, and Andrew Packard have been using techniques from control theory to automatically generate verification certificates for machine learning pipelines. Their methods can analyze many of the most popular techniques for machine learning on large-data sets. And their longer term goal is to be able to derive performance characteristics and analyze the robustness of complex, distributed software systems directly from pseudocode. (A related AMPLab project Velox provides a framework for managing models in production.)
As algorithms become even more pervasive, we need better tools for building complex yet robust and stable machine learning systems. While other systems like scikit-learn and GraphLab support pipelines, a popular distributed framework like Apache Spark takes these ideas to extremely large data sets and a wider audience. Early results look promising: AMPLab researchers have built large-scale pipelines that match some state-of-the-art results in vision, speech, and text processing.
To view Ben Recht’s talk, sign-up for a free trial of Safari Books Online. Among his many hats, Ben Recht is the co-organizer of Hardcore Data Science day at Strata+Hadoop World.