
 Traditional cell phone versus smart phone. (source: By Takashi Hososhima on Wikimedia Commons)
Traditional cell phone versus smart phone. (source: By Takashi Hososhima on Wikimedia Commons) When developing intelligent, real-time applications, one often has access to a data platform that can wade through and unlock patterns in massive data sets. The back-end infrastructure for such applications often relies on distributed, fault-tolerant, scaleout technologies designed to handle large data sets. But, there are situations when compressed representations are useful and even necessary. The rise of mobile computing and sensors (IoT) will lead to devices and software that push computation from the cloud toward the edge. In addition, in-memory computation tends to be much faster, and thus, many popular (distributed) systems operate on data sets that can be cached.
To drive home this point, let me highlight two recent examples that illustrate the importance of efficient compressed representations: one from mobile computing, the other from a popular distributed computing framework.
Deep neural networks and intelligent mobile applications
In a recent presentation, Song Han, of the Concurrent VLSI Architecture (CVA) group at Stanford University, outlined an initiative to help optimize deep neural networks for mobile devices. Deep learning has produced impressive results across a range of applications in computer vision, speech, and machine translation. Meanwhile the growing popularity of mobile computing platforms means many mobile applications will need to have capabilities in these areas. The challenge is that deep learning models tend to be too large to fit into mobile applications (these applications are downloaded and often need to be updated frequently). Relying on cloud-based solutions is an option, but network delay and privacy can be an issue in certain applications and domains.
One solution is to significantly reduce the size of deep learning models. CVA researchers recently proposed a general scheme for compressing deep neural networks in three steps:
- prune the unimportant connections,
- quantize the network and enforce weight sharing,
- and finally apply Huffman encoding.
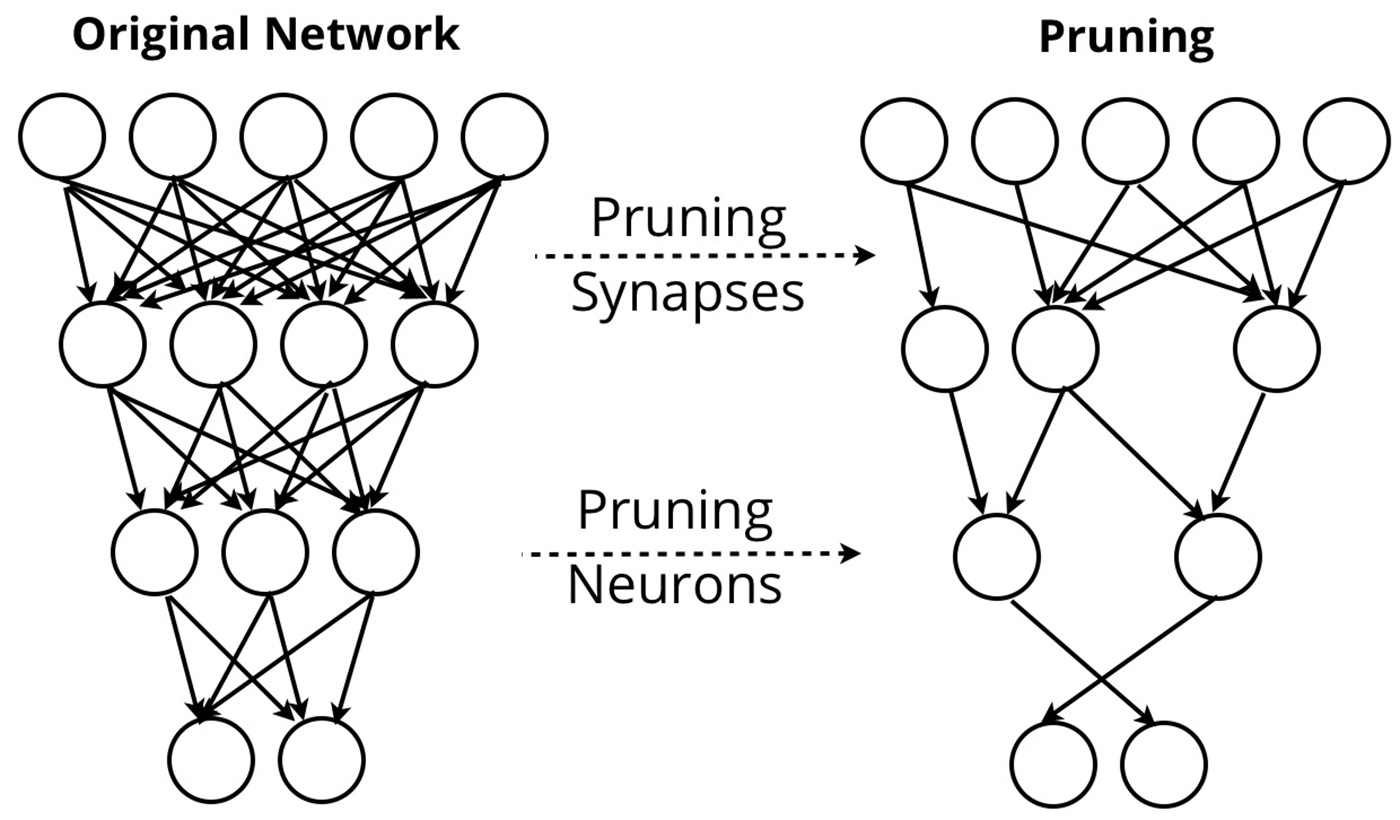
Initial experiments showed their compression scheme reduced neural network sizes by 35 to 50 times, and the resulting compressed models were able to match the accuracy of the corresponding original models. CVA researchers also designed an accompanying energy-efficient ASIC accelerator for running compressed deep neural networks, hinting at next-generation software + hardware designed specifically for intelligent mobile applications.
Succinct: search and point queries on compressed data over Apache Spark
Succinct is a “compressed” data store that enables a wide range of point queries (search, count, range, random access) directly on a compressed representation of input data. Succinct uses a compression technique that empirically achieves compression close to that of gzip, and supports the above queries without storing secondary indexes, without data scans, and without data decompression. Succinct does not store the input file, just the compressed representation. By letting users query compressed data directly, Succinct combines low latency and low storage:
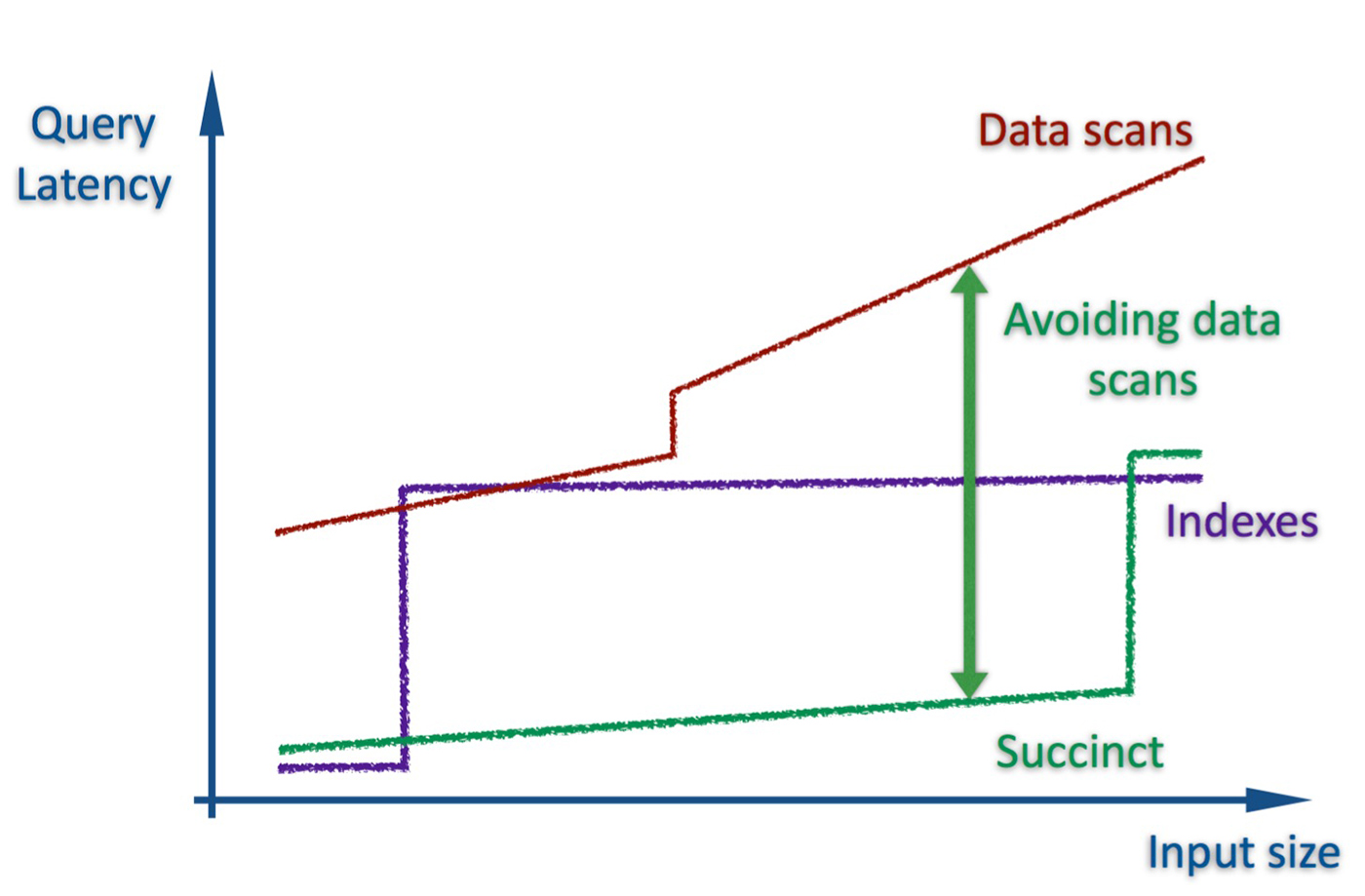
While this AMPLab project had been around as a research initiative, Succinct became available on Apache Spark late last year. This means Spark users can leverage Succinct against flat files and immediately execute search queries (including regex queries directly on compressed RDDs), compute counts, and do range queries. Moreover, abstractions have been built on top of Succinct’s basic flat (unstructured) file interface, allowing Spark to be used as a document or key-value store, and a DataFrames API currently exposes search, count, range, and random access queries. Having these new capabilities on top of Apache Spark simplifies the software stack needed to build many interesting data applications.
Early comparisons with ElasticSearch have been promising and, most importantly for its users, Succinct is an active project. The team behind it plans many enhancements in future releases, including Succinct Graphs (for queries on compressed graphs), support for SQL on compressed data, and further improvements in preprocessing/compression (currently at 4 gigabytes per hour, per core). They are also working on a research project called Succinct Encryption (for queries on compressed and encrypted data).
Related Resources:
- At the upcoming Emerging Technology day in Strata + Hadoop World San Jose, Kanu Gulati will describe Opportunities for Hardware Acceleration in Data Analytics.
- Big Data: Efficient Collection and Processing, Anna Gilbert’s Strata + Hadoop World presentation on Compressed Sensing.
- Doing the Impossible (Almost), Ted Dunning’s Strata + Hadoop World presentation on t-digest and approximation algorithms.
- Hardcore Data Science California 2015 complete Video Compilation.