A data-centric approach to security monitoring
Learn how to understand the threats you face by collecting, mining, organizing, and analyzing as many relevant data sources as possible. Excerpt from Crafting the InfoSec Playbook.
 CERN tape library. (source: Cory Doctorow via Flickr)
CERN tape library. (source: Cory Doctorow via Flickr)
“Quickest way to find the needle… burn the haystack.”
Kareem Said

Learn faster. Dig deeper. See farther.
Effective security alarms are only useful when introduced with efficient, precise, and where possible, automated data analysis. This chapter describes fundamental building blocks to develop and implement a tailored security monitoring and response methodology. To that end, we’ll discuss:
-
How to prepare and store your data
-
How to give your operation authority and clarity with a solid logging policy
-
What metadata is and why you should care about it
-
How to develop and structure incident detection logic into your own playbook
Properly developing incident response methods and practices requires a solid plan and a foundational framework for every security incident response team. Finding security incidents and helpful clues to other nefarious behavior can be difficult. With no plans or framework in place, an incident response team can be immediately lost in a sea of data, or left with a dead end having no data (or no useful data) to analyze.
You could buy a bunch of expensive gear, point it all to a log management or a security incident and event management (SIEM) system, and let it automatically tell you what it knows. Some incident response teams may start this way, but unfortunately, many never evolve. Working only with what the SIEM tells you, versus what you have configured it to tell you based on your contextual data, will invariably fail. Truly demonstrating value from security monitoring and incident response requires a major effort. As with all projects, planning is the most important phase. Designing an approach that works best for you requires significant effort up front, but offers a great payout later in the form of meaningful incident response and overall improved security.
Learning from our early experience as a set-it-and-forget-it team, we distilled the basics for getting started with an effective data-centric incident response plan. Most importantly, you must consider the data: normalizing, field carving and extraction, metadata, context enrichment, data organization, all to set yourself up to create effective queries and reports within a sustainable incident detection architecture.
Get a Handle on Your Data
Data preparation requires as much forethought and execution as any other step in the data collection process. Failure to do so can have unanticipated and investigation-ending results. Those of us doing security work often fail to appreciate the importance of enforcing consistency during the preparation and organization of data sources. Simply aggregating logs into a single system may satisfy the letter of the law when it comes to regulatory compliance. And why not? Regulatory compliance may require central collection of data, but says nothing about preparing that data so that it can be effectively used for responsive monitoring or forensics. Data preparation, commonly an afterthought, satisfies the spirit of the law, and is a required process that supports any successful security monitoring infrastructure.
Note
As you prepare your log data for analysis, think of the classic database model of extract, transform, and load (ETL). The concepts are largely the same for log preparation and analysis, but can be more or less structured depending on the type of data you intend to consume.
In 1999, the National Aeronautics and Space Administration’s (NASA) Jet Propulsion Lab learned all too well the importance of consistency across data sources. NASA contracted Lockheed Martin to write an application to control thrusters in NASA’s Mars Climate Orbiter. Lockheed’s application returned thruster force calculated in imperial pounds. When NASA’s navigation program consumed this data, it assumed the thruster force was specified in metric newtons. Because of the discrepancy between actual and perceived calculations, the Orbiter’s navigation system was unable to correctly position itself for entry into Mars’ orbit. NASA lost over $100 million when the craft disappeared in space. The costly accident resulted from failing to properly normalize data by converting measurement units before processing the data.
Data mining log events for incident response requires a similar type of preparation before analysis that NASA and Lockheed failed to perform. Rather than converting from imperial pounds to metric newtons, a security log repository may need to convert timestamps from one time zone to another, correlate hosts with IPs to NetBIOS names, index the true source IP address behind a web proxy, or rename a security device–supplied field to an organization’s standardized field (for example, changing “dst IP” to “dest_IP”). Without ensuring proper data organization by including a standard (and consistent) nomenclature for event fields, you cannot compare or accurately link events between those disparate data sources.
When integrating a new data source, prepare for the possibility that the events may not only contain an entirely different type of data, but be formatted differently than any other data source you already have. To ease management and analysis of the data later on, you need to create an authoritative collection standard to organize event data. The standard should be applied to imported data as soon as possible. Mature organizations will apply the standard to originated data as well, influencing and enhancing data value across the organization.
Depending on the collection and search infrastructure, you may even be required to parse fields during data indexing time, as it’s not possible at search time. Though events from different log sources may have unique structures, they often contain similar data, such as source IP address and destination IP address. All logs at a minimum should contain a timestamp. Identifying these common fields, parsing, and labeling the fields consistently for each data source is the foundation for correlating the disparate data during search time.
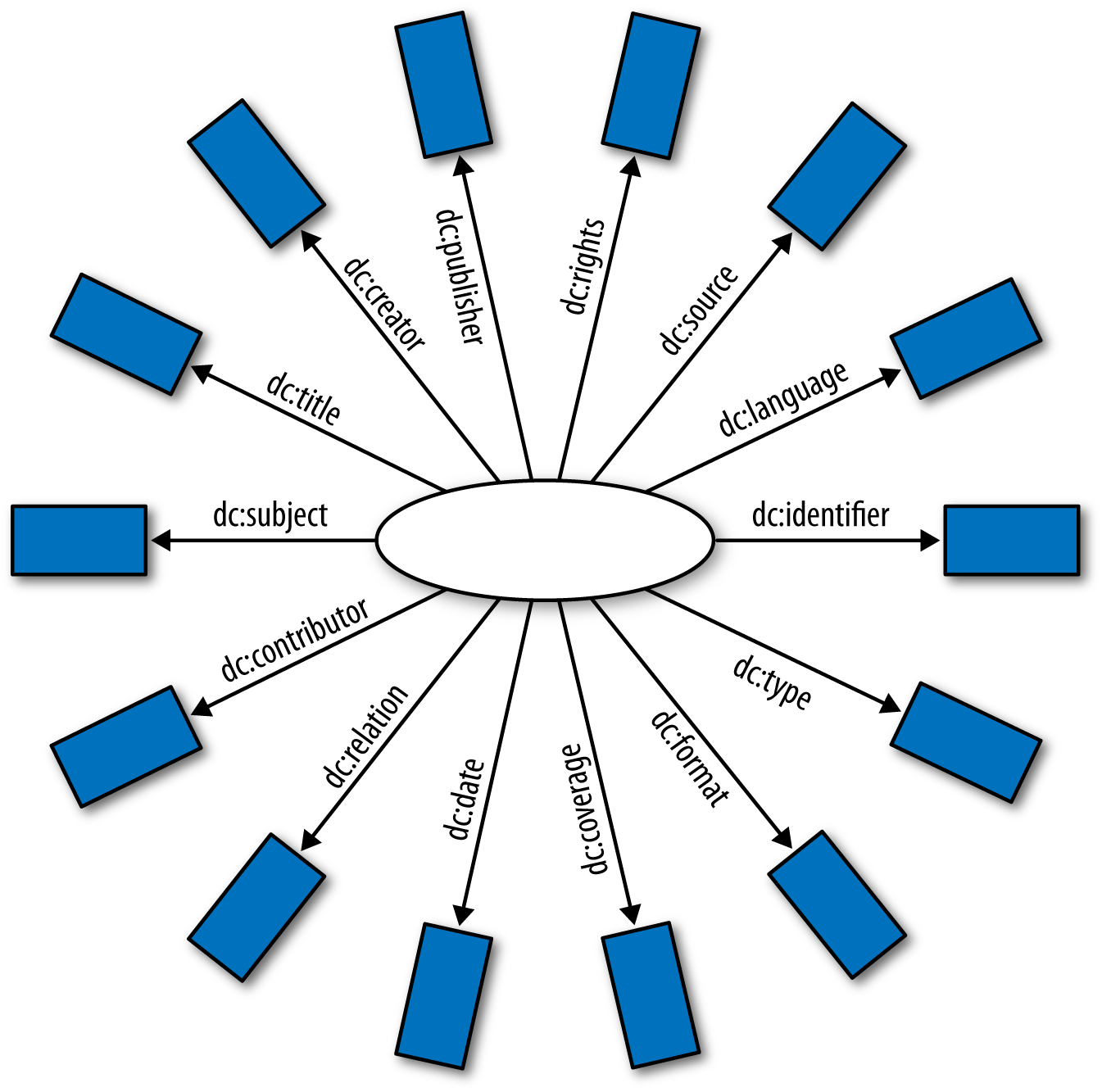
A great example of this concept is the Dublin Core (DC). Essentially the DC is a system of standard generic descriptors (metadata) that libraries can use for their archives (see Figure 1-1). Library systems that adhere to the DC can easily exchange information compatible with other library archiving systems.
Using a similar concept, security teams should ensure their digestible and queryable log data is also standardized with common field names for interoperability among queries and reports, as well as the various security monitoring technologies in place.
{kind=link}
Logging Requirements
Before taking on a log management project, it’s important to understand and develop the proper deployment planning steps. Things like scope, business requirements, event volume, access considerations, retention strategy, diverse export platforms, and engineering specifications are all factors in determining long-term success. You must be able to answer the following:
-
Will the detection be exclusively from network security devices, or will you gather host log/application data as well?
-
Can you partner with other teams to share appropriate access to log data for troubleshooting, performance, and security purposes?
-
By what process do you install an agent-based tool on a critical service, like a production email server, directory server, finance, or SCADA system? Is the risk of stability and availability worth the net gain in log data?
-
What network changes (ACLs, additional routes, account permissions, etc.) are affected by a log collector or exporter, or what impact will traffic rate limiting have on log streaming and storage over the network if log data surges in volume?
-
How much storage will you need and how many resources are required to maintain it?
-
Beyond all the IT resourcing, how many analysts are required to actually review the alert data?
-
Is there a comprehensive and enforceable logging policy? Have sysadmins enabled sufficient logging?
-
What is the expected event volume and server load?
-
What are the event/incident long-term retention requirements? How and when will data be purged from the system?
-
How do you ensure no loss in availability of your data feeds, either because of problems with your own toolset or service delivery issues with your dependencies?
We expect that we’ll get the proper logs with readable data from any host or service hosted by IT. Within your organization’s IT infrastructure, a solid and unified (think: Windows, Network, Unix, mobile, etc.) logging standard is a must. Following the strict corporate security logging standard our team developed, we enforce the following additional aspects of log collection and management through a similar policy:
-
Systems must log system events to satisfy requirements for user attribution, auditing, incident response, operational support, event monitoring, and regulatory compliance. Or more simply, who did what, from where, when, and for how long.
-
Systems must forward logs in real time to an InfoSec-approved centralized log management system to satisfy log retention, integrity, accessibility, and availability requirements. When real-time transfer of log data is infeasible, it is acceptable for logs to be transferred from the source device to the log management system using an alternative method such as a scripted pull or push of log data. In such cases, your logging policy should state the frequency of the data sync. Ideally, no more than 15 minutes should elapse between the time the log is generated and the time it is received by the log management system.
Note
Organizational policies should specify a maximum delay between the time a log is created and when it is available in the log management system.
While this may be unattainable by some data owners or systems, the key is to have a stated policy from which exceptions can be granted if necessary.
-
Systems that generate logs must be synchronized to a central time sourcing device (NTP) and configured for Coordinated Universal Time (UTC) (with offsets) and an ISO 8601 data expression format.
-
Systems that generate logs must format and store logs in a manner that ensures the integrity of the logs and supports enterprise-level event correlation, analysis, and reporting.
-
Systems must record and retain audit-logging information sufficient to answer the following:
-
What activity was performed?
-
Who or what performed the activity, including where or on what system?
-
When was the activity performed?
-
What tool(s) were used to perform the activity?
-
What was the status (e.g., success or failure), outcome, or result of the activity?
-
-
System logs must be created whenever any of the following events are requested or performed:
-
Create, read, update, or delete documents classified with “highly confidential” or “restricted information” privileges.
-
Initiate or accept a network connection.
-
Grant, modify, or revoke access rights, including adding a new user or group, changing user privilege levels, changing file permissions, changing database object permissions, changing firewall rules, and user password changes.
-
Change system, network, application or service configuration, including installation of software patches and updates or other installed software changes.
-
Start up, shut down, or restart of an application or process.
-
Abort, failure, or abnormal end of an application or process.
-
Detection of suspicious or malicious activity, such as from an intrusion detection system, antivirus system, or antispyware system.
-
Just the Facts
Before you can prepare your data for analysis, you need data worth preparing. In the context of security monitoring, that means the data you collect needs to provide some investigative value, or can help identify malicious or anomalous behavior. The sheer number of potentially generated events, combined with the number of possible event sources, can leave you overwhelmed. Keeping all logs everywhere is the easiest strategy, but has some significant drawbacks. Too often, teams hoard logs because they think the logs might be useful by somebody someday. The paradox between logging and incident response is that you never know what log file(s) will be useful throughout the course of an investigation that could cover almost any aspect of a computer or network system.
Logs that have no security content or context waste storage space and index processing, and affect search times. An example of such a log might be a debug from a compiler or even from a network troubleshooting session that is archived into syslog. These superfluous events can make analysis daunting or be distracting to sort through when you’re trying to find the gold. After you understand what type of events you need for security monitoring and incident response, you can proactively ensure that logs exist that contain the events you’re after. How then, in this superfluity of messages, do you identify what events are of value?
A common mistake (one that we admittedly made) is to simply throw all alarms from all devices into the log solution, only to find that discovering incidents over the long term is difficult. Most likely, you would notice results immediately from the noisiest alarms for the most common, typical malware. However, after those issues have been tamped out, it can be difficult to find value in the rest of the alarms. If you have not tuned anything, there will be hundreds or thousands of alarms that may mean nothing, or are simply informational. Do you really care that a ping sweep occurred from one of your uptime monitors? Did a long-running flow alarm trip on a large database replication? You’ll also need to consider the following:
-
Sanctioned vulnerability scanners
-
Normal backup traffic and replication
-
System reboots or service changes during a typical change window
-
Safe executables sent via email
-
Legitimate SQL in a URL (that gives the impression of SQL injection)
-
Encrypted traffic
-
Health monitoring systems like Nagios
These are just a few of the many ways unnecessary alarms can clog up the analysts’ incident detection capacity. It is true that some informational alarms can be useful, particularly if they are reviewed over a time range for trends and outliers. One example would be tracking downloads from an internal source code repository. If the standard deviation for the downloads rises dramatically, there could be unauthorized spidering or a potential data loss incident. A cluttered interface of alarm data is not only daunting to the analyst, but also a setup for failure as potentially valuable alarms may be lost or unnoticed in the sea of unimportant alarms, like in Figure 1-2.
Some non-security–centric data sources generate only a portion of total log events that contain useful InfoSec content, such as a boot log or display/driver messages (dmesg). Knowing that a new and unexpected service is starting, or that a local USB rootkit driver is loading, is of security value, but knowing that a filesystem consistency check happened is likely less valuable. Other log events like common application errors, verbose troubleshooting logs, or service health checks may be useful to the system administrators, but provide little value to a security analyst looking at the broader landscape. Splitting off the useful security event log data from routine operational log data provides the most efficient option. Take, for instance, Cisco ASA Virtual Private Network (VPN) syslog data. The ASA produces approximately 2,000 different syslog messages. Buried in all that logging are three syslog messages that provide attribution information (713228, 722051, and 113019).
Note
To cut through useless log data, try to focus on how you will apply the data in investigations. Determining who did what, when, and where requires logs that can provide attribution, attack details, unusual system issues, or confirmations of activity.
If you’re only trying to attribute remote VPN connections to IP addresses and users, failing to filter the almost 2,000 other message types will put undue overhead on your infrastructure and clutter your log analysis.
Useful security event log data can be found in non-security centric data sources by identifying activities such as the following:
-
Access, authenticate to, or modify confidential info
-
Initiate or accept a network connection
-
Manipulate access rights
-
System or network configuration changes
-
Process state changes (start, terminated, HUP, failure, etc.)
-
New services
Each of the events generated in the preceding list should contain the following information:
-
Type of action performed
-
Subsystem performing the action
-
Identifiers for the object requesting the action
-
Identifiers for the object providing the action
-
Date and time
-
Status, outcome, or result of the action
For established security event data sources, there’s often less concern with identifying the activities just listed, and more concern with preparing the data. After all, an IDS or antivirus system’s primary job is to provide you with information about the state of security for something, be it a network, operating system, or application. Despite the specificity of these types of events, additional filtering may still be required due to overwhelming volume, lack of relevancy to your environment, or for tuning to ensure accuracy. For instance, we know from experience that in most cases, TCP normalization IDS signatures fire loads of alarms because of network congestion and other expected behavior that the signature developers believe could be evidence of a potential attack or misuse.
Collecting only relevant data can have a direct impact on reducing costs as well.
Note
In planning a log collection infrastructure, you might offset additional costs by having other teams share access to the log data, not for security monitoring, but for development, system administration, accounting, or troubleshooting issues.
The effect extends to more than a requirement for large hard drives and backup systems. Indexing licenses, system computer cycles, and analysis cycles to parse growing data sets are all affected by the amount of data you store. An organization’s security and log management policies, preferably backed by the organization’s legal counsel, will dictate mandatory data retention time. Resource-strapped organizations must think critically about precisely what to collect, where to store it, and for how long. Filtering unnecessary data can keep licensing costs down, save on computer cycles, and require less logical storage space. Working with system and application administrators on what they would consider suspicious, and working to understand the unique qualities of their log data saves time and effort in determining what data to keep or reject. Spending time and resources to make intelligent decisions regarding the data you need once at collection time will save time and resources every time the logs are searched. Only after you’ve identified the data to collect can you start to prepare the data for your collection and analysis systems.
Normalization
Once the logs have been filtered, you can begin to organize and compartmentalize the remaining security event data. Taking a tip from the NASA measurement SNAFU, it should be quite clear how important this next step becomes. Data normalization for the purposes of log mining is the process by which a portion, or field, of a log event is transformed into its canonical form. The organization consuming the data must develop and consistently use a standard format for log normalization. Sometimes, the same type of data can be represented in multiple formats. As a common example, consider timestamps. The C function strftime() and its approximately 40 format specifiers give an indication of the potential number of ways a date and time can be represented. ISO 8601 attempts to set an internationally recognized standard timestamp format, though the standard is all too often ignored. That, combined with the fact that most programming libraries have adopted strftime()’s conversion specifications, means that application developers are free to define timestamps as they see fit. Having a diverse group of incoming timestamps from various logging systems can be troublesome when trying to match up dates and times in an investigative query. Consuming data that includes timestamps requires recognizing the different formats and normalizing them to the official, standard format.
Besides timestamps, other data elements requiring normalization are MAC addresses, phone numbers, user IDs, IP addresses, subnet masks, DNS names, and so on. IPv6 addresses in particular can be represented in multiple ways. As a rule, leading zeros can be omitted, consecutive zeros can be compressed and replaced by two colons, and hexadecimal digits can be either upper- or lowercase (though RFC 5952 recommends the exclusive use of lowercase). As an example, consider the following IPv6 address variations:
-
2001:420:1101:1::a
-
2001:420:1101:1::A
-
2001:420:1101:1:0:0:0:a
-
2001:0420:1101:0001:0000:0000:0000:000a
-
2607:f8b0:0000:0000:000d:0000:0000:005d
-
2607:f8b0::d:0:0:5d
-
2607:f8b0:0:0:d::5d
-
::ffff:132.239.1.114
-
::132.239.1.114
-
2002:84ef:172::
If web proxy logs identify requests from a host via a compressed AAAA record (no zeros), and DHCP logs attribute a host to AAAA address leases containing the zeros, for successful correlation, one of the AAAA records must be converted at some stage to link the results from both data sources. It’s important to define the types of data requiring normalization before the logs are imported and indexed, rather than at analysis time to improve operational efficiency. Think of the regular expressions you might apply during some future search. For a regex to work properly on all the logs, the data needs to have regularity.
Playing Fields
Now that the log data is cleaned up after normalization and filtering, you can begin to consider how best to search it. Finding security events will be much easier if the logs are intuitive and human readable. The best way to carve up the logs is by creating fields. Fields are elements in a log file that represent a unique type of data. Every log file can have fields, and in fact some log files already have embedded fields like this DHCP log:
time="2014-01-09 16:25:01 UTC" hn="USER-PC" mac="60:67:40:dc:71:38"
ip="10.1.56.107" exp="2014-01-09 18:54:52 UTC"
time="2014-01-09 16:25:01 UTC" hn="USER-PC" mac="60:67:40:dc:71:38"
gw="10.1.56.1" action="DHCPREQUEST"
The DHCP server generated this log with descriptive, readable fields (time, hn, mac, ip, exp) nicely laid out in key-value pairs with spaces as field delimiters.
Consistent use of standard field names makes interacting with log data much easier. You might standardize on a field name of source_host for events from the monitoring infrastructure that include an originating, or source IP address. Authentication logs containing a username might label that particular attribute field user. Whatever the field is named, use the same label each time a newly acquired data source possesses the same field type. Most well-formed logs will have a timestamp. Networked event data sources will also include source or destination IP addresses. Additional common field types across the core security event data sources include:
-
timestamp(date, or_time) -
source IP(host) -
source port -
destination IP(s_ip) -
destination port -
hostname -
nbtname -
sourcetype -
eventsource -
alerttype -
event action
This list represents our common minimum fields for any event source. These are the minimum mandatory fields we require before we decide whether to index an additional log source for searching. You want as much descriptive metadata as possible, without logging and subsequently indexing useless data or fields. Without an indication of who did what, when, and where, we can never attribute an event to any particular security incident. Not all fields in our list may be present from every event source, but when they are available, they provide the most basic information necessary to respond to an alert. Alerttype and event action broadly represent the type of security alarm and the details as described by an event source.
More information, at least in security event data, is often better than less. More fields can be extracted and leveraged with additional parsing to illustrate information unique to the event source itself. Beyond this basic metadata, some security event sources provide a wealth of information available as additional fields. For example, an IDS alarm may include more context about an alert than what is captured in either alerttype or event action. Take, for instance, an ASCII-decoded snippet of an IP packet payload. More fields allow for fine-tuned searching and provide more statistical sorting and comparison options when querying for incident data. A rule identifier is also common across data sources—such as an IDS signature—and should use the predefined label for that field.
Application documentation often contains information on the possible events and formats that an application might output to a log. This should be the primary reference for understanding what data a log source can provide. In the absence of such documentation, the CSIRT must coalesce the log data using context about the data source itself and type of messages being generated. For instance, attribution data sources like authentication servers are likely to associate an action with a host or user, while classic security event data sources like IDS contain some alert about an asset or observed action. If the CSIRT can’t manage the log export options, or if it’s not flexible enough to be tailored, post-filtering is the only option.
Fields in Practice
In our experiences dealing with mountains of log data, we’ve come to the conclusion that in any useful logs, there are always similar fields with different names that mean the same thing. We’ve also determined that you’ll probably need to split out the fields exactly the way you want them, and it won’t always be automatic. Knowing what fields help build queries and how to best extract the fields consistently across data sources goes a long way toward creating useful detection logic.
Comparable applications in different environments will likely produce similar log events with different formats. The following example is from one of our actual data sources. Our first event is raw data from a single host-based intrusion detection system (HIDS) log:
2015-09-21 14:40:02 -0700|mypc-WIN7|10.10.10.50|4437|The process 'C:\Users\mypc\Downloads\FontPack11000_XtdAlf_Lang.msi' (as user DOMAIN\mypc) attempted to initiate a connection as a client on TCP port 80 to 199.7.54.72 using interface Virtual\Cisco Systems VPN Adapter for 64-bit Windows. The operation was allowed by default (rule defaults).
Where to begin on how to split this singular log event into useful fields? An initial qualitative assessment of the message identifies | used as a field delimiter (with a very generous fifth field!). Other common delimiters include spaces, quotes, or tabs. Unfortunately, many events may lack a parseable delimiter entirely. Assuming the delimiter is unique to the message (i.e., it does not exist elsewhere within the event message), it can easily be parsed into fields with a Perl-like split() function.
There are a handful of other remarkable artifacts in the event. First and foremost is the highly recommended ISO 8601 standardized timestamp, with a date format of year-month-day, the use of a 24-hour clock specified to seconds, and an American Pacific Standard time zone defined as a numeric offset from UTC:
2015-09-21 14:40:02 -0700
Already there are questions to answer: How does this timestamp format align with other logs already in the log collection system? In this case, it appears to be using the desired ISO 8601 format, but how can you be sure what (or who) is generating this timestamp? Is this the client application, the collector’s message received time, or something totally different?
Additionally, delimited fields include an IP address (10.10.10.50), a hostname (mypc-WIN7), a numeric rule identifier (4437), and a long event action field occupying the remainder of the event. As mentioned, source IP address and hostname should be fairly standard log attributes, so it’s important to normalize these fields and match them up with other event sources. More queries around this one field and timestamp can yield much more information toward understanding an incident.
Lastly, the log message contains the event action. In this case, the log revealed that a Windows process successfully attempted to create a network connection over a VPN interface. At a minimum, this entire field can be labeled as Event Action. Bear in mind that the same log feed will likely contain various actions. There is so much information hidden in that single field that it’s worth extracting additional fields to handle more flexible queries.
Consider what is necessary to properly extract fields from event data:
-
Are the fields in a given log finite and enumerable?
-
Do similar events generate a log message consistent with previous events of the same type? In the example, different operating systems or agent versions may generate similar but varying messages for the same action.
-
Can the parser properly handle inconsistently formatted event actions?
Having consistency within event actions is crucial, because there may be additional attributes within the action itself worth parsing.
How does another log source compare to the HIDS data? The following is an event from a web proxy:
1381888686.410 - 10.10.10.50 63549 255.255.255.255 80 - -6.9 http://servicemap.conduit-services.com/Toolbar/?ownerId=CT3311834 - 0 309 0 "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)" - 403 TCP_DENIED - "adware" "Domain reported and verified as serving malware. Identified malicious behavior on domain or URI." - - - - GET
In this example, we’re missing the convenience of an obviously unique delimiter. Fields are delimited with spaces, but spaces also exist within field values themselves. In the preceding example, when there is a space in the field value, the entire field value is enclosed in double quotes as a means of escaping the spaces. Abstracted, the question becomes, how do you parse a field where the field delimiter is legitimately used in the field itself? A simple split() will no longer work to break the event into fields. This log event requires a parser with logic that knows not to split when the delimiter is escaped or quoted.
Beyond the difference between delimiters, the timestamp is in a different format from the HIDS data. In this instance, the web proxy uses Unix epoch time format. If, at a minimum, we have only the HIDS data and this web proxy data, at least one of the time values must be normalized so that the data can be easily understood and correlated during analysis. Log timestamp inconsistencies are rampant. CSIRTs should prepare to convert and format data in line with the organization’s internal standard time format for each new type and instance of data source.
Similar to the HIDS data, the web proxy identifies with a client IP Address 10.10.10.50. The same standardized field name as used for source IP address should be used in the proxy logs. Because this is a web proxy log, we can expect basic HTTP information, all of which should be parsed into uniquely representative fields:
-
URL
-
Browser user-agent
-
HTTP server response
-
HTTP method
-
Referer [sic]
As a final data source, let’s compare DHCP logs to the HIDS and web proxy events. This example shows multiple events:
10/08/2013 20:10:29 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" gw="10.10.10.1" action="DHCPREQUEST" 10/08/2013 20:10:29 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" ip="10.10.10.50" exp="10/09/2013 22:11:34 UTC" 10/08/2013 22:11:34 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" gw="10.10.10.1" action="DHCPREQUEST" 10/08/2013 22:11:34 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" ip="10.10.10.50" exp="10/09/2013 02:11:33 UTC" 10/09/2013 02:11:37 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" ip="10.10.10.50" exp="10/09/2013 02:11:33 UTC" 10/09/2013 02:11:38 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" ip="10.10.10.50" action="EXPIRED"
Initial analysis again reveals fields delimited with spaces and clearly identifies fields in key-value pairs, with keys:
-
hn(hostname) -
mac(MAC address) -
ip(source IP Address) -
gw(gateway) -
action(DHCP server action) -
exp(DHCP lease expiration timestamp)
Notice that each value in the tuple is also double quoted. This is important, because the data source may identify additional key fields. Even if documentation identifying each field is lacking, an analysis should manually enumerate each field with a large enough sample set of log data.
Proper analysis requires a very strict parser that only matches what’s already been identified. With this parsing, do any messages fail to match? Is the parser overly greedy or too specific? An iterative approach to parsing allows for finding rare exceptions. For example, if the mac field looks to be lowercase a–f, 0–9, and colons (:), then start by writing a regular expression that will only match those characters. Run the parser and identify any missed events that should have been caught, perhaps from events containing MAC addresses with uppercase A–F. The same process applies to any fields that require parsing.
Similar to the VPN and web proxy logs, the timestamp format. It’s using the month/day/year format and a 24-hour clock. But what about time zone? Did the DHCP administrators neglect to configure an export of time zone information in the log message, or does the DHCP server not even support exporting the time zone? Either way, determination and normalization of the event time zone is a responsibility of the custodian—as opposed to the log analyst—and must be performed prior to writing the event data to the collector. Incorrect or disputed timestamps can quickly jeopardize an investigation.
Whereas earlier we looked at individual HIDS and web proxy log messages, a number of DHCP log messages are presented in this example. While each event has meaning and value individually, the combined events show a single DHCP session over the course of approximately six hours for a single host. We label multiple log entries that all describe different phases of a single event as a transaction. Continuing to use DHCP as an example, the different common phases of a DHCP session include:
-
DISCOVER
-
OFFER
-
REQUEST
-
ACKNOWLEDGEMENT
-
RENEW
-
RELEASE
The first four phases—DISCOVER, OFFER, REQUEST, ACK—are all individual events (log messages) that comprise a DHCP lease. Identifying a successful DHCP lease transaction provides attribution for hosts in the DHCP pool. Therefore, grouping the phases of a DHCP lease together and being able to search on the completed transaction itself rather than individual messages eases an analyst’s ability to confirm an IP was assigned to an asset at a given time:
10/08/2013 20:10:29 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" gw="10.10.10.1" action="DHCPREQUEST" 10/08/2013 20:10:29 hn="mypc-WS" mac="e4:cd:8f:05:2b:ac" ip="10.10.10.50" exp="10/09/2013 22:11:34 UTC"
There are additional instances where it’s ideal to identify transactions in log data that have the potential to span multiple events, such as VPN session data, authentication attempts, or web sessions. Once combined, the transaction can be used for holistic timelines or to identify anomalous behavior. Consider a transaction identifying normal VPN usage. If the same user initiates a new VPN connection before an older connection has been terminated, it may be indicative of a policy violation or shared VPN credentials—both the responsibility of a CSIRT to identify.
Fields Within Fields
As stated previously, additional attributes may exist within individual fields that are worth parsing themselves. Consider the action from the HIDS alert, and the Requested URL from the web proxy log:
HIDs 'Event Action' field: The process 'C:\Users\mypc\Downloads\FontPack11000_XtdAlf_Lang.msi' (as user DOMAIN\mypc) attempted to initiate a connection as a client on TCP port 80 to 199.7.54.72 using interface Virtual\Cisco Systems VPN Adapter for 64-bit Windows. The operation was allowed by default (rule defaults). Web Proxy 'Requested URL' field: http://servicemap.conduit-services.com/Toolbar/?ownerId=CT33118
Both fields contain data that very well could be a field in and of itself, and may possibly be a field in another data source. The HIDS log identifies the following additional fields:
-
Path (
C:\Users\mypc\Downloads) -
Filename (
FontPack11000_XtdAlf_Lang.msi) -
Active Directory domain (
DOMAIN\mypc) -
Destination IP address (
199.7.54.72) -
Port (
80) -
Protocol (
TCP) -
Verdict (
operation was allowed)
The URL from the web proxy contains the following additional fields:
-
Domain (
conduit-services.com) -
Subdomain (
servicemap) -
URL path (
Toolbar/) -
URL parameter (
?ownerId=CT331183)
Though lacking in this example, the web proxy URL could have just as easily contained a filename. Each of these fields is a potential metadata attribute that can be used to correlate, or link, the HIDS or web proxy event with another data source. From the HIDS event, an analyst may want to determine what other hosts also contacted the IP address on port 80 by searching NetFlow data. Or the analyst may want to correlate the filename identified in the web proxy log with HIDS data to see if the same filename attempted execution on the same or other hosts.
Had NASA at least done some data normalization, they would have differentiated between units of measurement and potentially controlled their spacecraft as intended. A calculated value, much like a timestamp, can and will be represented in multiple different ways. An organization can choose to use any representation of the data they want, as long as the usage is consistent, the data representation has meaning to the organization, and any deviations from the standard format are adjusted and documented prior to analysis time. However, understanding data’s significance requires context, which can be garnered using metadata.
Metadata: Data About Data About Data
Metadata is a loaded term. It’s an imprecise word that broadly attempts to describe both data structures and data components. In other words, it is both a category and a value. Figuratively, metadata is the envelope, and the letter inside is the data, but the fact that you received a letter at all is also data. Metadata is, in fact, itself data. This tautology manifests itself when applied to the concepts of incident response and security monitoring. Metadata could be a single component, like the field descriptor in a log file (e.g., source IP address), or it could also be the log file itself depending on how it’s applied to a security incident or investigation. To determine whether something is metadata, simply apply these two age-old maxims: “it depends,” and “you know it when you see it.”
Metadata for Security
In the context of security monitoring, we consider metadata as it applies to log and event data. Metadata is a collection of attributes that describes behavior indicative of an incident. It is more than the sum of all of its parts. As an example, NetFlow logs are both wholly metadata and comprised of metadata elements that contain values. Looking at a typical NetFlow log (version 5), you have a standard list of fields including:
-
Source and destination IP addresses and ports
-
IP protocol
-
Network interface data
-
Flow size
-
Flow duration
-
Timestamps
These elements provide basic context for every network event. This contextual information is metadata that describes the event in generic terms. However, consider the following information derived from a NetFlow record: a two-day flow from an internal host transmitting 15 gigabytes of data to an external host from source port 30928 to destination TCP port 22.
Because of the nature of this traffic (unusually large and encrypted outbound file transfers), we could make a circumstantial judgement based on the context that data exfiltration has occurred. However, it could have just as easily been a really big (and benign) SCP/SFTP file transfer, or a complete dead end. Knowing when our assumptions are being tested, or that we may have imperfect log data, always factors into achieving conclusive closure for an investigation.
Log data alone means very little. The context built from log data matters the most. Metadata brings us a step closer to understanding what the events in a log represent. We derive context by organizing and sorting raw data into metadata, or groups of metadata, and applying knowledge and analysis to that context. When the log data is massive, reducing to, and searching with metadata elements yields understandable and digestible information, cutting through to the most valuable information and providing the capability to search efficiently.
Blinded Me with [Data] Science!
In 2013, the New York Times published details on the United States National Security Agency (NSA) and its metadata gathering and analysis program exposed by NSA insider, Edward Snowden. According to the leaked secret documents, the NSA performed “large-scale graph analysis on very large sets of communications metadata without having to check foreignness of every e-mail address, phone number or other identifier”. Despite the constitutional ramifications for American citizens, on the surface, the operation was colored as a benign exercise. According to the NSA, they were only looking at connections and patterns between various phone numbers and email addresses to help identify terrorist cells or plots. The data they mined included phone call and email records. From those records, they extracted metadata like source phone number, destination phone number, call date, and call duration. With this metadata alone, the NSA had enough information to build statistical models around their log data to make assumptions. An agent could confirm that unknown person A made phone calls to suspicious persons B, C, and D. By association, the Agent would assume suspicion for person A as well, making them a target of a larger investigation. However, the real power, as well as a big part of the controversy, stems from how the NSA “enriched” their surveillance with additional components (and how they obtained those components).
As we’ve described already, context around data and metadata makes all the difference. If we yell “fire” in an empty building, it means nothing. If an officer yells it to their soldiers, it means something completely different. If we yell it in a crowded public place, we’ve potentially committed a crime. The piece of data (the word fire) is identical. However, the context in which it’s used is totally different, and as such, it has a dramatically different impact. The NSA used both publicly and privately available data to enhance its analysis. According to the New York Times, sources of public information could include property tax records, insurance details, and airline passenger manifests. Phone numbers could be associated with a Facebook profile, which could infer a human owner of the phone number, along with a wealth of other data that the person was willing to share on Facebook. With these additional data sources, the NSA could develop a profile with more than just a basic list of call records. Seemingly benign phone record data when combined and correlated with other attribution data could generate context. This context could help the agency with its profiling and investigations, and provide more intelligence on a suspect than they would have had with just statistical graph modeling.
Putting the contentious ethical and legal concerns aside and getting back to the playbook, a similar approach could be used in security incident response. We describe data and classify its log file containers by extracting metadata, and then apply logical conditions and calculations to yield information. That new information is then analyzed to create knowledge that drives the incident response process.
Metadata in Practice
In one incident, we detected an internal client attempting to resolve an unusual external hostname. The domain looked suspicious because of its random nature (i.e., lots of ASCII characters arranged in a nonlinguistic pattern). We remembered from a previous case that a dynamic DNS provider who has hosted many malicious sites in the past hosted this particular domain as well. On the surface, so far all we knew was that an internal client was trying to resolve a suspicious external hostname. We did not know if it successfully connected to the Internet host or why it attempted to resolve the hostname. We did not know if the resolution was intentional on behalf of the client, if it was a result of remotely loaded web content, or if it was unexpected and potentially malicious. However, we had already realized a bit of metadata. We knew:
| Metadata | Metacategory: Data |
|---|---|
| The remote hostname appeared randomly generated. | Hostname: dgf7adfnkjhh.com |
| The external host was hosted by a dynamic DNS provider. | Network: Shady DDnS Provider Inc. |
With this metadata alone, we could not have made an accurate judgement about the incident. However, combining these elements with other metadata began an illustration of what happened and why we should have cared. This information, along with our experience and encounters with these types of connections in the past, led us to presume that the activity was suspicious and warranted additional investigation. This is an important concept—having responded to incidents in the past with similar characteristics (e.g., this particular combination of metadata), we deduced that this was most likely another security incident. More precisely, we applied our knowledge derived from experience to these metadata components.
Building on the initial metadata we now had:
| Metadata | Metacategory: Data |
|---|---|
| The DNS lookup occurred at a certain time. | Timestamp: 278621182 |
| The internal host sent a DNS PTR request. | Network protocol: DNS PTR |
| The internal host had a hostname. | Location: Desktop subnet
Source IP Address: 1.1.1.2 Hostname: windowspc22.company.com |
| The internal host resolved an external host. | Location: External
Destination IP Address: 255.123.215.3 Hostname: dgf7adfnkjhh.com |
| The external host was hosted by a dynamic DNS provider. | Network: Shady DDnS Provider Inc.
ASN: SHADY232 Reputation: Historically risky network |
| The remote hostname appeared randomly generated. | Hostname: dgf7adfnkjhh.com
Category: Unusual, nonlinguistic |
However, we were stuck with very little context. Similar to only knowing that a phone number reached out to some suspicious phone numbers, we were left with statistical models, some bias based on previous investigations, and a hunch to figure out if the connection was indeed unexpected.
Context Is King
To determine whether this was a malicious event indicative of malware or some other type of attack demands, we include more context. Looking at NetFlow data from the client host before, during, and after the DNS lookup, we assessed other connections and assumptions based on metadata yielded from the flow records. From the flow data, we could see numerous HTTP connections to Internet hosts in the moments leading up to the suspicious DNS request. After the DNS request, we saw additional HTTP connections on nonstandard ports to other remote hosts. Up to this point, we still had very little confirmed evidence to go on. NetFlow could not provide enough useful context for this event to take us further. However, when NetFlow is associated with other metadata from the event, it can provide additional details. It is great to confirm that connections occurred, but with no additional context or packet contents, we had not moved closer to confirming an infection or security incident. We knew nothing more than that an internal client made some suspicious connections. Because of our prior knowledge on those types of connections (i.e., the context we’ve developed experientially and applied to our play), the only reason this host was highlighted for investigation was because of the suspicious destination.
At this point, we have realized enough metadata to get us speculating about what actually happened with this host. Was it a malicious connection, or was it just an oddball DNS request? We had lots of data, some metadata, but no real actionable information yet. As already mentioned, we flagged this event as suspicious because of our prior experience looking at similar threats. This experience resulted in the development of knowledge, which we could apply to the information we’ve collected.
Note
The evolution of knowledge is: data→information→knowledge.
We applied our knowledge that connections to random-looking hostnames are generally bad (domain-generation algorithm) to data (the passive DNS logs) and extracted information: that an internal client may be at risk of a malware infection. This last piece is what will inform the security incident if one is necessary. Without more context, though, we still don’t know that it’s truly “bad.” An algorithm can predict or discover a domain-generation algorithm, but it will not be capable of understanding its context within the transaction.
Context enrichment provides more context by enhancing our current data sets. We can pivot on various pieces of metadata to narrow down our focus to a digestible window and continue to build the case for an incident. We can take the metadata values of timestamp and source IP and add those to an additional query. Our web proxy log data is often a wealth of contextual information. Looking at web-browsing activity in a linear fashion can help to uncover unusual activity. In this case, we pivoted on the source IP field at the same timeframe the suspicious DNS lookup was performed. The proxy log data showed typical browsing to a regional news site. However, mixed in with the browsing, we noted a few HTTP connections to domains apparently not part of the news website.
The power of the web is its ability to link together various organizations and networks. However, this also allows many, many remote objects to be pulled in by the client browser just from the action of reading the news online. The domains referenced matched up with the domains from the passive DNS collection system. Right after those objects were fetched from the suspicious domains, we saw a different browser user-agent, namely Java/1.7.0_25, attempting to pull down a Java Archive (JAR) file from yet another odd-looking domain:
278621192.022 - 1.1.1.2 62461 255.123.215.3 80 - http://dgf7adfnkjhh.com/wp-content/9zncn.jar - http://www.newsofeastsouthwest.com/ 344 215 295 "Java/1.7.0_25" - 200 TCP_MISS
After this happened, the host intrusion prevention (HIPS) logs indicated the same Java JAR file trying to unpack and make additional HTTP requests to another remote domain for a DOS executable. The executable was fetched by the Java client, and the host intrusion prevention logs showed system-level modification attempts from the newly download executable. Fortunately, the HIPS blocked the executable from causing any damage, but at this point, based on all the context provided by metadata, we can clearly call this an exploit attempt, followed by a multistage malware dropper:
| Metadata | Metacategory: Facts |
|---|---|
| A known vulnerable Java plug-in attempted to download additional JAR files from other odd domains. | User-Agent: Java1.7.0_25
Hostname: dgf7adfnkjhh.com Category: Unusual, nonlinguistic Vulnerability: Java1.7.0_25 Plugin Filetype: JAR |
| HIPS blocked execution after JAR unpack | Filetypes: JAR, EXE, INI
Filenames: 9zncn.jar, svchost.exe, winini.ini Path: \Users\temp\33973950835-1353\.tmp HIPS action: Block |
So to get from raw data in the form of passive DNS logging to responding to a security incident, we had to take multiple transformative and additive steps. We reshaped the raw data with contextual information synthesized from additional data sources, with the help of metadata, into usable information. We applied our existing knowledge of suspicious indicators to the information we developed from our log queries to ferret out details of an actual security incident. However, this whole exercise took no more than five minutes to investigate.
Going forward, we can take streamlined queries to find the same or similar behavior in the future, and roll those into regular, high-fidelity reports. Illustrating by way of key-value pairs with fictitious field names:
external_hostname=DDNS, AND http_action=GET, AND remote_filetype=JAR, AND local_filetype=REG, AND local_path="\windows\sysWOW64" OR "\windows\system32", AND HIPS_action=block
A query that can yield results based on this context will provide plenty of detail for investigation, and could potentially roll into a regular report. Metadata and context provide seed material for new reports based on investigating singular events with an experienced eye for finding odd behavior.
Metadata is the catalyst that allows you to transform raw data into information. You cannot organize your data further without metacategories, and you cannot query efficiently without it. One of the best parts of relying on metadata is that it is reusable. Many fields were common for all the data sources mentioned in the preceding investigation. Basic details like timestamps, IP addresses, hostnames, and the like are typically available in all event sources. It’s a matter of how to correlate those event sources around the metadata fields available. At the end, once you have a good method for regularly distilling raw data into security incidents, you have a report. When you have a collection of repeatable reports, you have an incident response playbook.
Chapter Summary
-
There are many ways to provide security monitoring and incident response, but the best approach will leverage an understanding of an organization’s culture, risk tolerance, business practices, and IT capabilities.
-
Log data can record critical information that can be used in security investigation, as well as providing foundational data for an entire security monitoring program.
-
Well-prepared and normalized log data is essential for efficient operations.
-
Metadata is a powerful concept to help simplify log data and analysis.
-
Context around data and assets is an indispensable component in a successful monitoring strategy.