Design, build, release, run
Including design in every iteration of your cloud-native app development.
 Lunar eclipse cycle (source: Unsplash via Pixabay)
Lunar eclipse cycle (source: Unsplash via Pixabay)
In Beyond the Twelve-Factor App, I present a new set of guidelines that builds on Heroku’s original 12 factors and reflects today’s best practices for building cloud-native applications. I have changed the order of some to indicate a deliberate sense of priority, and added factors such as telemetry, security, and the concept of “API first” that should be considerations for any application that will be running in the cloud. These new 15-factor guidelines are:
- One codebase, one application
- API first
- Dependency management
- Design, build, release, and run
- Configuration, credentials, and code
- Logs
- Disposability
- Backing services
- Environment parity
- Administrative processes
- Port binding
- Stateless processes
- Concurrency
- Telemetry
- Authentication and authorization
Build, release, run, of the original 12 factors, calls for the strict separation of the build and run stages of development. This is excellent advice, and failing to adhere to this guideline can set you up for future difficulties. In addition to the twelve-factor build, release, run trio, the discrete design step is crucial.

Learn faster. Dig deeper. See farther.
In the figure below, you can see an illustration of the flow from design to run. Note that this is not a waterfall diagram: the cycle from design through code and to run is an iterative one and can happen in as small or large a period of time as your team can handle. In cases where teams have a mature CI/CD pipeline, it could take a matter of minutes to go from design to running in production.
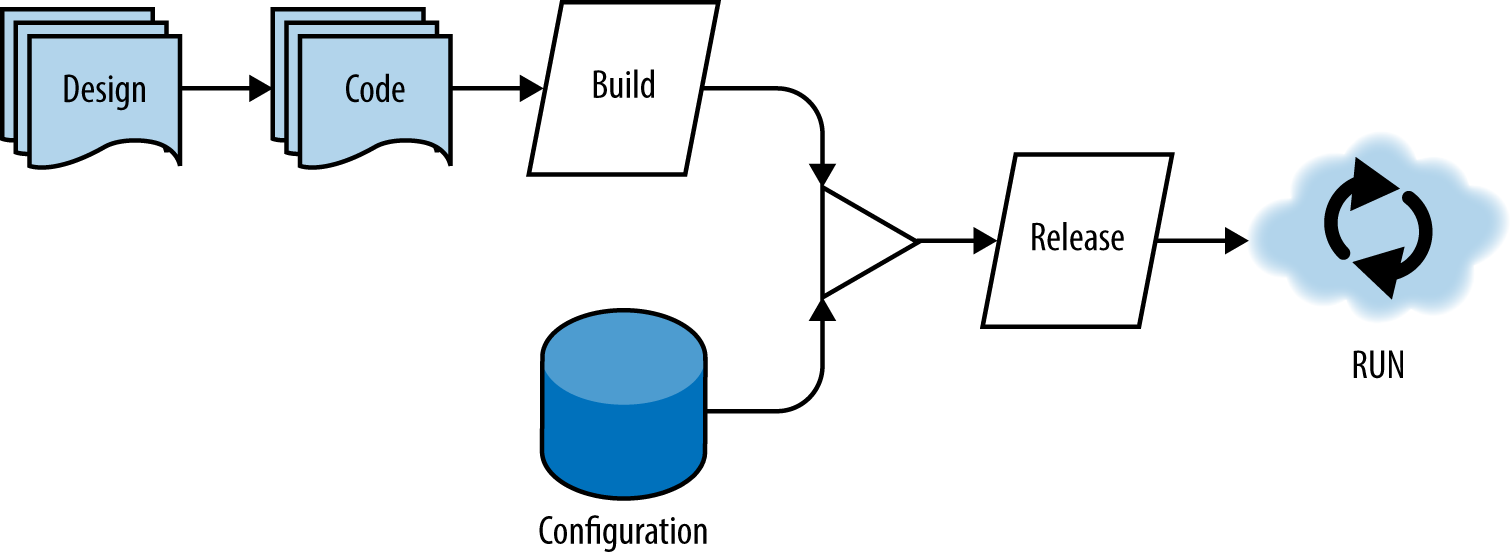
A single codebase is taken through the build process to produce a compiled artifact. This artifact is then merged with configuration information that is external to the application to produce an immutable release. The immutable release is then delivered to a cloud environment (development, QA, production, etc.) and run. The key takeaway is that each of the following deployment stages is isolated and occurs separately.
Design
In the world of waterfall application development, we spend an inordinate amount of time designing an application before a single line of code is written. This type of software development life cycle is not well suited to the demands of modern applications that need to be released as frequently as possible.
However, this doesn’t mean that we don’t design at all. Instead, it means we design small features that get released, and we have a high-level design that is used to inform everything we do; but we also know that designs change, and small amounts of design are part of every iteration rather than being done entirely up front.
The application developer best understands the application dependencies, and it is during the design phase that arrangements are made to declare dependencies as well as the means by which those dependencies are vendored, or bundled, with the application. In other words, the developer decides what libraries the application is going to use, and how those libraries are eventually going to be bundled into an immutable release.
Build
The build stage is where a code repository is converted into a versioned, binary artifact. It is during this stage that the dependencies declared during the design phase are fetched and bundled into the build artifact (often just simply called a “build”). In the Java world, a build might be a WAR[1] or a JAR file, or it could be a ZIP file or a binary executable for other languages and frameworks.
Builds are ideally created by a Continuous Integration server, and there is a 1:many relationship between builds and deployments. A single build should be able to be released or deployed to any number of environments, and each of those unmodified builds should work as expected. The immutability of this artifact and adherence to the other factors (especially environment parity) give you confidence that your app will work in production if it worked in QA.
If you ever find yourself troubleshooting “works on my machine” problems, that is a clear sign that the four stages of this process are likely not as separate as they should be. Forcing your team to use a CI server may often seem like a lot of upfront work, but once running, you’ll see that the “one build, many deploys” pattern works.
Once you have confidence that your codebase will work anywhere it should, and you no longer fear production releases, you will start to see some of the truly amazing benefits of adopting the cloud-native philosophy, like continuous deployment and releases that happen hours after a checkin rather than months.
Release
In the cloud-native world, the release is typically done by pushing to your cloud environment. The output of the build stage is combined with environment- and app-specific configuration information to produce another immutable artifact, a release.
Releases need to be unique, and every release should ideally be tagged with some kind of unique ID, such as a timestamp or an auto-incrementing number. Thinking back to the 1:many relationship between builds and releases, it makes sense that releases should not be tagged with the build ID.
Let’s say that your CI system has just built your application and labeled that artifact build-1234. The CI system might then release that application to the dev, staging, and production environments. The scheme is up to you, but each of those releases should be unique because each one combined the original build with environment-specific configuration settings.
If something goes wrong, you want the ability to audit what you have released to a given environment and, if necessary, to roll back to the previous release. This is another key reason for keeping releases both immutable and uniquely identified.
There are a million different types of problems that arise from an organization’s inability to reproduce a release as it appeared at one point in the past. By having separate build and release phases, and storing those artifacts, rollback and historical auditing is a piece of cake.
Run
The run phase is also typically done by the cloud provider (although developers need to be able to run applications locally). The details vary among providers, but the general pattern is that your application is placed within some kind of container (Docker, Garden, Warden, etc.), and then a process is started to launch your application.
It’s worth noting that ensuring that a developer can run an application locally on her workstation while still allowing it to be deployed to multiple clouds via CD pipeline is often a difficult problem to solve. It is worth solving, however, because developers need to feel unhindered while working on cloud-native applications.
When an application is running, the cloud runtime is then responsible for keeping it alive, monitoring its health, and aggregating its logs, as well as a mountain of other administrative tasks like dynamic scaling and fault tolerance.
Ultimately, the goal of this guidance is to maximize your delivery speed while keeping high confidence through automated testing and deployment. We get some agility and speed benefits out of the box when working on the cloud; but if we follow the design, build, release, run guidelines, we can squeeze every ounce of speed and agility out of our product release pipeline without sacrificing our confidence in our application’s ability to do its job.