Efficient Machine Learning Inference
The benefits of multi-model serving where latency matters
 (Source: Pixabay)
(Source: Pixabay)
Machine Learning (ML) inference, defined as the process of deploying a trained model and serving live queries with it, is an essential component of many deployed ML systems and is often a significant portion of their total cost. Costs can grow even more uncontrollably when considering hardware accelerators such as GPUs. Many modern user-focused applications critically depend on ML to substantially improve the user experience (by providing recommendations or filling in text, for example). Accelerators such as GPUs allow for even more complex models to still run with reasonable latencies, but come at a cost. This article is for developers and systems engineers with production responsibilities who run ML inference services, and explains how to employ multi-model serving to lower costs while maintaining high availability and acceptable latency.
Benefits of Multi-Model Serving
ML inference queries create different resource requirements in the servers that host them. These resource requirements are proportional to the requirements of the model, to the user query mix and rate (including peaks), and to the hardware platform of the server. Some models are large while others are small. This impacts the RAM or High-Bandwidth Memory (HBM) capacity requirements. Other models get periodic bursts of traffic, while others have consistent load. Yet another dimension to think about is the cost per query of a model: some models are expensive to run, others are quite cheap. The combination of these determines the necessary compute capacity for a model.

Learn faster. Dig deeper. See farther.
Typically, ML applications that serve user-facing queries will provision for one model per host because it enables predictable latency by monitoring the per-host throughput. With this setup, increasing capacity is easy: just add more hosts. This horizontal scaling, however, ignores common pitfalls including inefficient capacity planning or unused resources such as the RAM or HBM on the accelerator. However, for most ML applications, it is unusual for one model to receive enough queries per second (QPS) to saturate the compute capacity of sufficient servers for reliable, redundant, and geographically distributed serving. This approach wastes all the compute capacity provisioned for these servers in excess of what is necessary to meet peak demand. While this waste can be mitigated by reducing the server VM size, doing so has the side effect of increasing latency.
Multi-model serving, defined as hosting multiple models in the same host (or in the same VM), can help mitigate this waste. Sharing the compute capacity of each server across multiple models can dramatically reduce costs, especially when there is insufficient load to saturate a minimally replicated set of servers. With proper load balancing, a single server could potentially serve many models receiving few queries alongside a few models receiving more queries, taking advantage of idle cycles.
Analyzing Single- Versus Multi-Model Serving Latency
Consider a real-world example of how multi-model serving can dramatically reduce costs. For this example, we will be using the Google Cloud Platform VM instance types in order to have a concrete example of provisioning and for gathering test data, but these points should apply to VMs in all major public cloud providers. A typical large VM on modern cloud services with no dedicated accelerators has 32 vCPUs and 128GB of RAM. A VM with a single Nvidia A100 GPU has 12 vCPUs, 85GB of host RAM, 40GB of HBM, and costs approximately 3.5x as much per VM.1 This configuration assumes on-demand pricing pertinent to low latency serving. For simplification, assume hosts are always provisioned for peak and that all models can fit on a single host if chosen to serve that way. Horizontal scaling can additionally help control costs.
The typical traffic pattern over the span of a week for 19 models may look like the following:
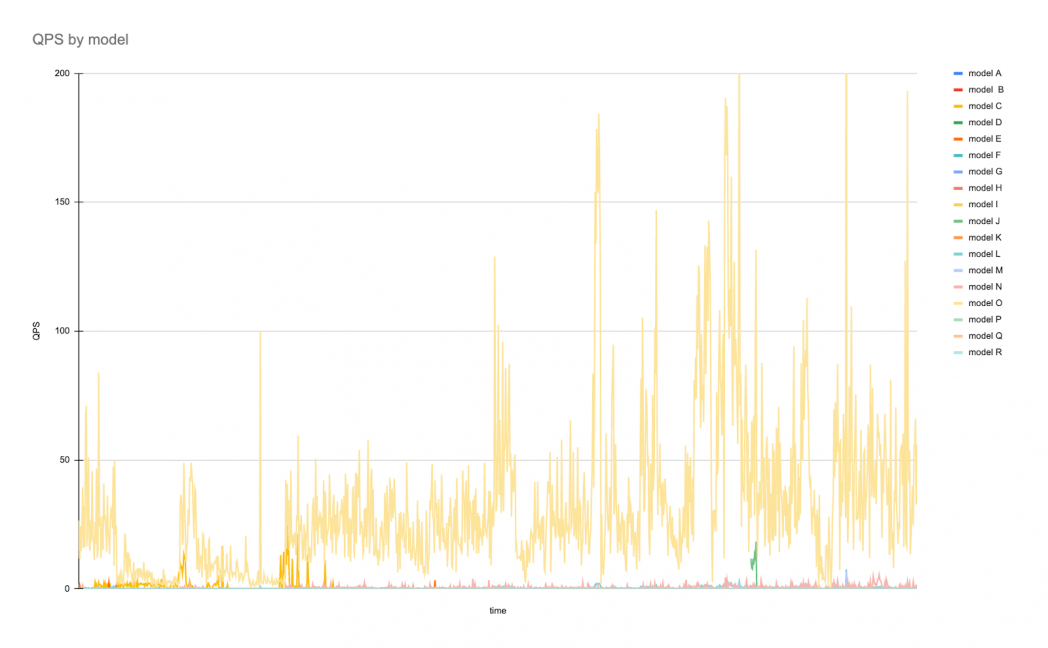
And latency over the same period of time:
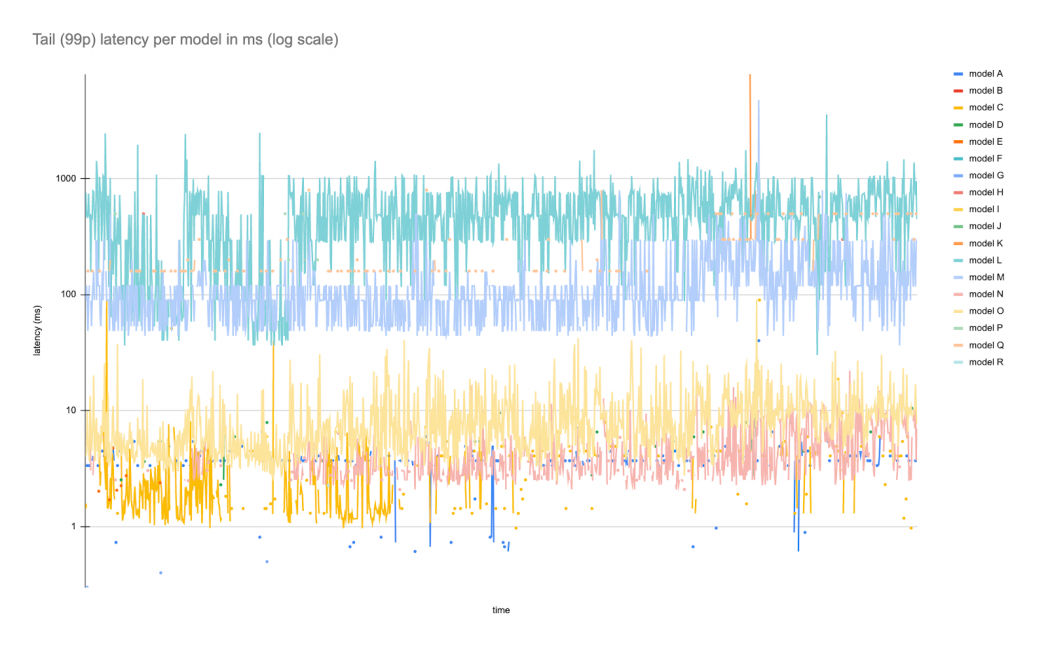
This example shows one model with a constant flow of traffic with occasional spikes and many other models with infrequent but bursty levels of traffic. Latency falls into different bands due to the varying model architectures and latency profiles, but apart from occasional spikes, tend to stay within a specific range.
Served from a standard GCP VM, this host is utilizing 21% of the CPU at peak but averages much lower. With single model serving, all 19 of these models would need a separately provisioned host, meaning one needs to provision for at least 19x the cost of a base VM at all times for on-demand serving. This design does not yet account for geographic or other forms of redundancy.
Taking just the higher QPS model (served in a multi-model setup), one observes the following latency graph:
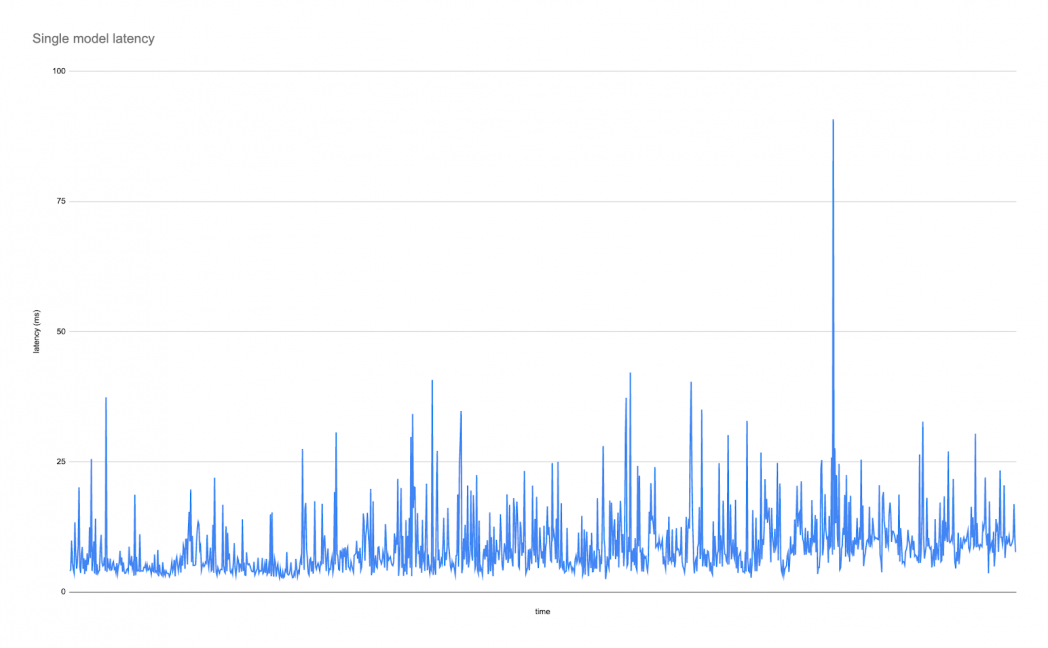
These graphs show the effect on tail latency, measured in this case as the 99th percentile latency since that is typically the metric that is most affected by multi-model serving and that users tend to care about. This example shows that latency can go as low as 4ms, with brief spikes up to 40ms and only one single spike of double that. For some applications, this variance in latency is unacceptable and single-model serving is the only reasonable choice for provisioning. This is because provisioning for a single use case leads to predictable latency and low variability on tail latency, while average latency would be in the same ballpark in most cases. Consider this scenario the “latency at any cost” scenario. Provisioning for this case naively implies spinning up at least 19 hosts, 1 per model. For GPU models, apply the 3.5x multiplier to the base costs.
At the other extreme, having all of these models in the same host makes better use of the RAM capacity. This particular host is using 40GB of RAM for these 19 models, or about 22% of capacity. Hosting them together amortizes the costs, and uses existing RAM capacity by recognizing that no CPU comes without at least some RAM attached to it, therefore minimizing stranding of resources.
Costs Versus Latency
At moderate CPU utilization, latency varies inversely with the amount of vCPU attached to the VM, as ML models can take advantage of parallel threads to process queries faster. This means that for “latency at any cost,” large VMs are best. From a cost perspective for the vast majority of models that serve at low QPS, reserving an entire large VM for each model is expensive, so a common approach is to use a smaller VM. This approach reduces cost, but sacrifices latency, as the graph below shows:
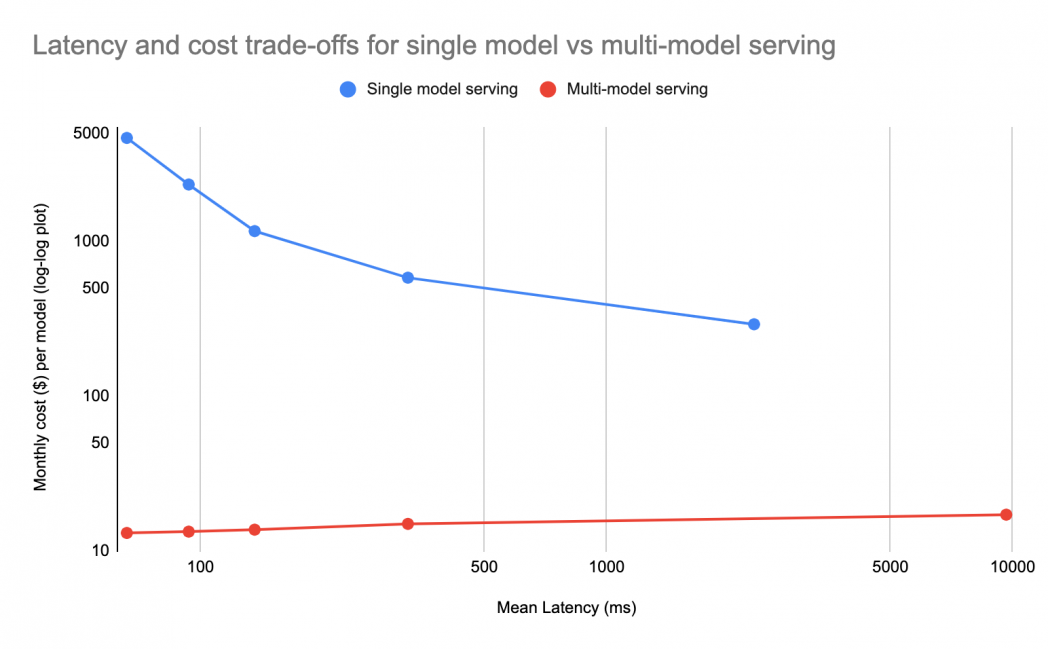
An alternative approach is to pack as many models as possible onto a single VM using multi-model serving. This approach affords the latency benefits of the large VM but divides the costs across many more models, which can be hundreds. The above graph shows the latency versus cost tradeoff for a relatively slow parallel model with 10 QPS peak and 0.1 QPS on average, 3 VMs per region over 2 regions, going from 32 vCPU VMs on the left to 2 vCPU VMs on the right. Each point on the graph represents a separate VM size. Note how multi-model serving is about the same cost per model on larger VMs because more models can fit on the larger VMs, and the costs also have slight economies of scale due to binary overhead, while for single-model serving, the left of the graph shows latency at any cost.
For the rarer models with high QPS, the benefits of multi-model serving diminish but are still significant. Multi-model serving only needs to provision resources for the peak of sums load, enabling substantial savings when peak load for different models occurs at different times.
Conclusion
Multi-model serving enables lower cost while maintaining high availability and acceptable latency, by better using the RAM capacity of large VMs. While it is common and simple to deploy only one model per server, instead load a large number of models on a large VM that offers low latency, which should offer acceptable latency at a lower cost. These cost savings also apply to serving on accelerators such as GPUs.
1 Sourced from the official GCP VM pricing documentation
This post is part of a collaboration between O’Reilly and Google. See our statement of editorial independence.