 History of Jujutsu (source: Robert Rousseau)
History of Jujutsu (source: Robert Rousseau) Greetings, fellow reader of articles on the internet! Do you work on a service that you (and, presumably, your users) would like to keep working? Well, if so, I’m here to convince you that your service should have at least one or two generic mitigations ready to go. If it doesn’t, you’re in for a bad time. If it does, treasure them, maintain them, and use them, lest they rot beneath your feet.
Hold up, hang on, what’s a generic mitigation?
Alrighty. From the top: a mitigation is any action you might take to reduce the impact of a breakage, generally in production. A hotfix is a mitigation. SSHing into an instance and clearing the cache is a mitigation. Duct-taping a spare battery to a shoddy laptop counts, too. Cutting off power to a datacenter to close down a vulnerability is a mitigation, I guess, in the same way a guillotine cures the common cold.
A generic mitigation, then, is one that is useful in mitigating a wide variety of outages.
For example, a binary rollback is probably the most common generic mitigation. Many multi-homed services will have an emergency drain-the-traffic-off-the-broken-replica button, which is a good generic mitigation for query-based services. Others might have separate data rollbacks, or a tool to quickly add a whole bunch of additional capacity.
The most important characteristic of a generic mitigation is this: You don’t need to fully understand your outage to use it.
I mean, don’t we want to understand our outages?
No.
Okay, let me expand on that: you want to understand your outage after it is mitigated. Let’s draw a quick picture of a typical outage.
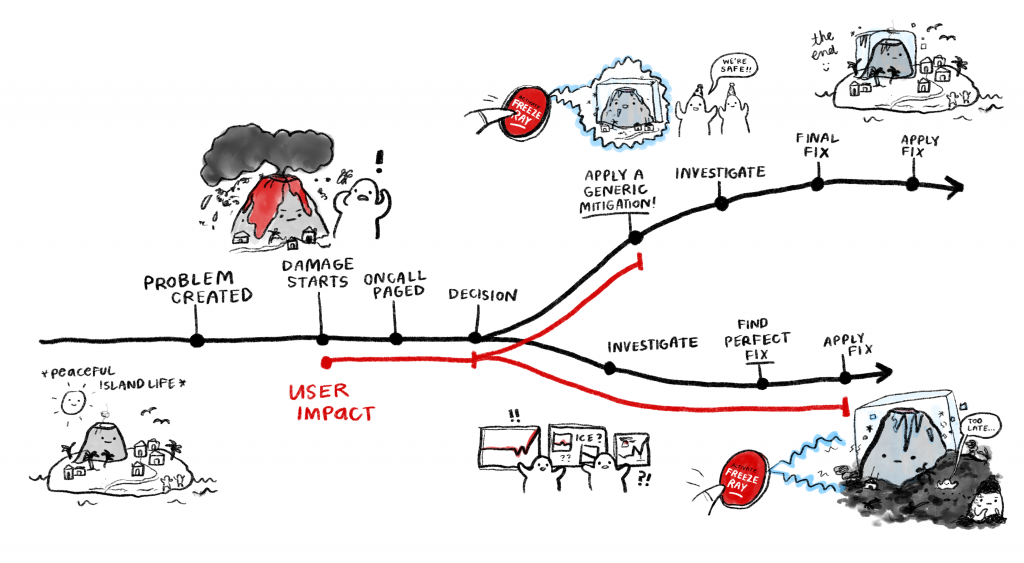
The goal of building good generic mitigations is to have a weapon ready to wield as early in the timeline as possible. If the only mitigations available to you are problem-specific, then you will be unable to help your users until you understand the problem in detail. It is very difficult to decrease the time it takes to understand a problem; if we could easily find problems, then we most likely wouldn’t have caused them in the first place.
So let’s assume that the measure of success for a team’s incident management is not “time to fix,” but “time to mitigate,” and that the thing we want to minimize is the time our users spend utterly broken. It is far easier to build mitigations with broad application than it is to make root-causing faster.

Sure. I’m with you. What’s stopping us?
Ironically, the difficulty is that generic mitigations are highly specific.
That’s a nonsense sentence. Let’s try again. A good, generic something-terrible-is-happening fix-it-quick button is simple (and safe!) to use in an emergency; a solid generic mitigation tool takes a lot of work beforehand to create and needs to be carefully tailored to the service it is mitigating.
There are, however, some very good general patterns for generic mitigations that we can learn from, though these will need careful tweaking to make them fit your specific service.
Okay, I’ll bite. What’re some generic mitigation patterns?
Glad you asked! Here’s a handful to get you started.
- Rollback
This reverts your service—most commonly, your binary, but there are other options—to a known-good state. Almost every service can implement a version of this strategy. Far too many think they have safe rollbacks, only to learn otherwise during an outage. - Data rollback
This is a sub-case of the previous one—it reverts just your data. Content-heavy services are more likely to find this useful, particularly those building data from pipelines. - Degrade
Is your service overloaded? Having a way to do less work but stay up is a huge improvement over crashing. Attempts to create a new degradation mechanism while your system burns will always bite you. - Upsize
Got too much traffic? Or is everything running hot for no reason? Add more replicas. It’s expensive, but cheaper than pissing off users with an outage. Note that this is rarely as simple as “scale up one binary”; system scaling is complex. - Block list
Got a query of death? Single spammy user taking out a zone? Block them. - Drain
Move your traffic to a different place. This one works great if you’re multi-homed and traffic driven: if one region sees high errors, move the requests elsewhere. - Quarantine
A good way to address the “bad instance” problem is to enforce a quarantine. Isolate a given unit of your usage—a hot DB row, a spammy user, a poisoned traffic stream—so whatever bug it is hitting stops breaking others.

Those…aren’t really all that generic
Yeah, you’d look pretty silly if you drained an instance because a recent release triggered errors, only to see the same errors 30 minutes later when the next instance upgrades. None of these are magic: you need to diagnose to the level of understanding the kind of failure scenario you’re dealing with.

These patterns are also not all equally useful to all services. For example, draining is nonsense for a lot of localized products whose users are pinned to a single physical zone. Quarantining is no use when your workloads are inseparable or when they’re already perfectly isolated. Degraded mode isn’t always an option.
So ask yourself what strategies make sense for your service. Make that part of your production readiness review—write down existing generic mitigations, and plan to add more if you’re falling short. (But not too many! Quality over quantity!) The better and more standardized your mitigations, the easier it is to scale support; there’ll be no need to page an expert awake at 2 AM if the mitigation will hold ‘til the morning.
Also? If you don’t use them, they won’t work.
Unfamiliar tooling is dangerous even in the hands of skilled oncallers. Whatever means you choose—running drills, adding automated tests, writing little checklists new team members must complete to gain production credentials—make certain your team has touched your mitigations. After all: tape backups no one’s ever practiced restoring might as well be fancy paperweights, for all the help they’ll be the first time someone runs rm -r /* in prod.

There’s a secondary benefit, too: by exercising your mitigations regularly, you validate their behaviors. Our systems are complex enough that you cannot know the knock-on effects of actually using your generic mitigation until you’ve used it for real.
The goal is to create easy, safe, frictionless panic buttons for your service that any oncall feels comfortable using at the slightest suspicion they might help. That’s not easy to build. But it is far, far cheaper to build them in advance than it is to endure the lengthy, unmitigatable outages you’ll see without.
Alright, boil it down for me
In brief: The most expensive stretch of an outage is the time when users can see it. A quick path to “mostly working” is far better for the user than waiting for “perfectly fixed.” If you’re driving a majestic old Toyota Corolla, sometimes the best tactic is making sure there’s duct tape in the glove box so you can make it to the mechanic when the wing mirror falls off.
Know what your duct tape is. You’re gonna need it.

This post is a collaboration between O’Reilly and Google. See our statement of editorial independence.
All images by Emily Griffin.