Get started with Hadoop: From evaluation to your first production cluster
Best practices for evaluating Hadoop and setting up an initial cluster (updated March 2012)
Hadoop is growing up. Apache Software Foundation (ASF) Hadoop and its related projects and sub-projects are maturing as an integrated, loosely coupled stack to store, process and analyze huge volumes of varied semi-structured, unstructured and raw data. (Updated March 12, 2012).
Hadoop has come a long way in a relatively short time. Google papers on Google File System (GFS) and MapReduce inspired work on co-locating data storage and computational processing in individual notes spread across a cluster. Then, in early 2006 Doug Cutting joined Yahoo and set up a 300-node research cluster there, adapting the distributed computing platform that was formerly a part of the Apache Nutch search engine project. What began as a technique to index and catalog web content has extended to a variety of analytic and data science applications, from ecommerce customer segmentation and A/B testing to fraud detection, machine learning and medical research.

Learn faster. Dig deeper. See farther.
Now, the largest production clusters are 4,000 nodes with about 15 petabytes of storage in each cluster. For example, at Yahoo they run over 42,000 Hadoop nodes storing more than 200 petabytes of data. According to a Hortonworks presentation at Hadoop World 2011, with Next-Generation MapReduce (YARN), Hadoop clusters can now scale to between 6,000 and 10,000 nodes with more than 100,000 concurrent tasks and 10,000 concurrent jobs.
Over time since I wrote an introduction to this emerging stack in August 2011, it has become easier to install, configure and write programs to use Hadoop. Not surprisingly with an emerging technology, there is still work to do. As Tom White notes in his Hadoop: The Definitive Guide, Second Edition:
To gain even wider adoption, we need to make Hadoop even easier to use. This will involve writing more tools; integrating with more systems; and writing new, improved APIs.
Hadoop: The Definitive Guide, Third Edition is available as an Early Release.
This piece provides tips, best practices and cautions for an organization that would like to evaluate Hadoop and deploy an initial cluster. It focuses on the Hadoop Distributed File System (HDFS) and MapReduce. If you are looking for details on Hive, Pig or related projects and tools, you will be disappointed in this specific article, but I do provide links for where you can find more information. You can also refer to the presentations at O’Reilly Strata: Making Data Work starting February 28, 2012 in Santa Clara, Calif., including an Introduction to Apache Hadoop presentation by Cloudera director of educational services Sarah Sproehnle.
Start with a free evaluation in stand-alone or pseudo-distributed mode
If you have not done so already, you can begin evaluating Hadoop by downloading and installing one of the free Hadoop distributions.
The Apache Hadoop website offers a Hadoop release 0.23 Single Node Setup guide along with a more detailed description in the release 0.22 documentation. The Hadoop community grouped updates into Hadoop version 1.0, although there are some previous updates that so far have not been reflected in Hadoop v1. For example, next-generation MapReduce (project name YARN) and HDFS federation (which partitions the HDFS namespace across multiple NameNodes to support clusters with a huge number of files) are included in Hadoop v0.23 but not in Hadoop v1.0. So be conscious of version control between Hadoop versions.
You can start an initial evaluation by running Hadoop in either local stand-alone or pseudo-distributed mode on a single machine. You can pick the flavor of Linux you prefer.
As an alternative to Linux or Solaris, you also have the option to run HDFS and MapReduce on Microsoft Windows. Microsoft ended its Dryad project, supports a Hadoop to SQL Server direct connector as an extension of Sqoop, launched a Hadoop-based Service for Windows Azure, partnered with Hortonworks, and announced plans to include support for Hadoop in the Microsoft SQL Server 2012 release.
In stand-alone mode, no daemons run; everything runs in a single Java virtual machine (JVM) with storage using your machine’s standard file system. In pseudo-distributed mode, each daemon runs its own JVM but they all still run on a single machine, with storage using HDFS by default. For example, I’m running a Hadoop virtual machine in pseudo-distributed mode on my Intel-processor MacBook, using VMWare Fusion, Ubuntu Linux, and Cloudera’s Distribution including Apache Hadoop (CDH).
If it’s not already pre-set for you, remember to change the HDFS replication value to one, versus the default factor of three, so you don’t see continual error messages due to HDFS’ inability to replicate blocks to alternate data notes. Configuration files reside in the directory named “conf” and are written in XML. You’ll find the replication parameter at dfs.replication. Note: some prefixes have changed in Hadoop versions 0.22 and 0.23 (but are not reflected yet in Hadoop version 1.0); see an explanation on the changes in HDFS prefix names.
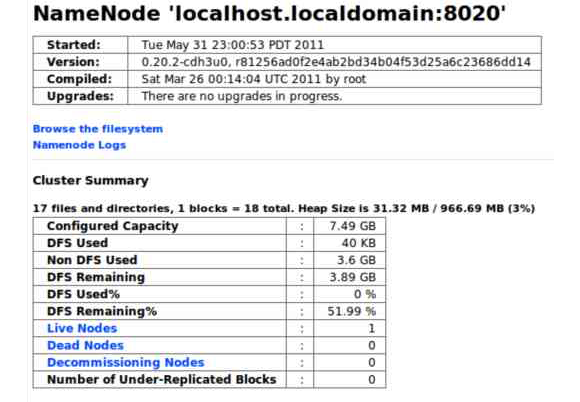
Even with a basic evaluation in pseudo-distributed mode, you can start to use the web interfaces that come with the Hadoop daemons such as those that run on ports 50030 and 50070. With these web interfaces, you can view the NameNode and JobTracker status. The example screen shot below shows the NameNode web interface. For more advanced reporting, Hadoop includes built-in connections to Ganglia, and you can use Nagios to schedule alerts.
Pick a distribution
As you progress to testing a multi-node cluster using a hosted offering or on-premise hardware, you’ll want to pick a Hadoop distribution. Apache Hadoop has Common, HDFS and MapReduce. Hadoop Common is a set of utilities that support the Hadoop sub-projects. These include FileSystem, remote procedure call (RPC), and serialization libraries. Additional Apache projects and sub-projects are available separately from Apache or together as a software bundle from vendors such as Cloudera, EMC Greenplum and Hortonworks that package Hadoop software distributions.
Hadoop is a work in progress, with a wealth of innovation by the Apache Hadoop community. Additions in 2011 and 2012 to Apache Hadoop include next-generation MapReduce, work on NameNode high availability (HA), separation of cluster resource management and MapReduce job scheduling, support for the Avro data file format in all Hadoop components, and HCatalog for metadata management.
One benefit of picking a commercial distribution in addition to the availability of commercial support services is that the vendor tests version compatibility among all of the various moving parts within the related Apache projects and sub-projects. It’s similar to the choice of commercially supported Red Hat Linux or Canonical Ubuntu Linux, but arguably of even greater importance given Hadoop’s relative youth and the large number of loosely coupled projects and sub-projects.
To date, Cloudera’s Distribution including Apache Hadoop has been the most complete, integrated distribution. It includes Apache Hadoop, Apache Hive, Apache Pig, Apache HBase, Apache Zookeeper, Apache Whirr (a library for running Hadoop in a cloud), Flume, Oozie, and Sqoop. CDH3 supports Amazon EC2, Rackspace and Softlayer clouds. With Cloudera Enterprise, Cloudera adds a proprietary management suite and production support services in addition to the components in CDH3.
Yahoo and Benchmark Capital teamed to fund Hortonworks, which offers Apache Hadoop software, training and consulting services. The Hortonworks Data Platform (HDP) version two is based on Hadoop 0.23 and includes Next Generation MapReduce and HDFS Federation. To date, all of the Hortonworks distribution is open source, including its Ambari management console. In February and March 2012 Hortonworks switched the roles of two executives (Rob Bearden become CEO with Eric Baldeschwieler as CTO); for marketing VP hired John Kreisa (who previously held that role at Cloudera); announced release of Apache Hadoop 0.23.1 and HDFS NameNode high availability; discussed new or expanded partnerships with Microsoft, Talend and Teradata; and reaffirmed commitment to supporting a Hortonworks Hadoop distribution with 100% open-source.
In June 2011, Tom White and Patrick Hunt at Cloudera proposed a new project for the Apache Incubator named Bigtop. To quote from their Bigtop proposal: “Bigtop is a project for the development of packaging and tests of the Hadoop ecosystem. The goal is to do testing at various levels (packaging, platform, runtime, upgrade etc…) developed by a community with a focus on the system as a whole, rather than individual projects.” Bigtop has reached the Apache Incubator phase, and provides binary packages (RPMs and Debian packages) for installation.
The EMC Greenplum HD Community Edition includes HDFS, MapReduce, Zookeeper, Hive and HBase. EMC also announced an OEM with MapR but may de-emphasize its MapR partnership following the EMC acquisition of storage vendor Isilon.
MapR replaces HDFS with proprietary software. At the Hadoop Summit 2011, MapR announced general availability (GA) of its M3 and M5 editions, with customer references from comScore and Narus, and partner references from CX, Karmasphere and Think Big Analytics. According to MapR, its distribution includes HBase, Pig, Hive, Cascading, the Apache Mahout machine learning library, Nagios integration and Ganglia integration. In addition to replacing HDFS, MapR has worked to speed MapReduce operations, and has added high availability (HA) options for the NameNode and JobTracker. MapR supports Network File System (NFS) and NFS log collection, and provides data interoperability with Apache-standad HDFS through the HDFS API, per conversations at the Hadoop Summit with MapR CEO and Co-Founder John Schroeder and VP of Marketing Jack Norris.
The free M3 Edition is available for both research and unlimited production use, with technical Q&A available through MapR Forums. The fee-based M5 Edition adds mirroring, snapshots, NFS HA and data placement control, along with commercial support services. MapR and Informatica announced support for Informatica Parser in the MapR Hadoop distribution in March 2012.
The IBM Distribution of Apache Hadoop (IDAH) contains Apache Hadoop, a 32-bit Linux version of the IBM SDK for Java 6 SR 8, and an installer and configuration tool for Hadoop. At the Hadoop Summit 2011, in the session Q&A following the talk by IBM’s Anant Jhingran, I asked Dr. Jhingran about the future of the IBM distribution. He explained to the audience that IBM has issued its own distribution as a temporary step while the technology and market mature, but does not plan on a long-term basis to continue to issue a separate IBM distribution of Hadoop.
IBM has indicated that it sees Hadoop as a cornerstone of its big data strategy, in which IBM is building software packages that run on top of Hadoop. IBM InfoSphere BigInsights supports unstructured text analytics and indexing, along with features for data governance, security, developer tools, and enterprise integration. IBM offers a free downloadable BigInsights Basic Edition. IBM clients can extend BigInsights to analyze streaming data from IBM InfoSphere Streams. In the Jeopardy game show competition, IBM Watson used Hadoop to distribute the workload for processing information, including support for understanding natural language.
Amazon Elastic MapReduce (EMR) builds proprietary versions of Apache Hadoop, Hive, and Pig optimized for running on Amazon Web Services. Amazon EMR provides a hosted Hadoop framework running on the web-scale infrastructure of Amazon Elastic Compute Cloud (EC2) or Simple Storage Service (S3).
HStreaming’s distribution is a proprietary version of Hadoop with support for stream processing and real-time analytics as well as standard MapReduce batch processing.
Consider Hadoop training
Education courses can be helpful to get started with Hadoop and train new staff. I had the opportunity to take a two-day Hadoop system administrator course taught by senior instructor Glynn Durham at Cloudera, and would recommend that course for system administrators and enterprise IT architects. Hortonworks offers support subscriptions and training. To find other organizations offering Hadoop training and other support services, visit the Apache Hadoop wiki support page.
For the Cloudera-taught Hadoop system administrator course, prior knowledge of Hadoop is not required, but it is important to have at least a basic understanding of writing Linux commands. Some understanding of Java is also beneficial, as each Hadoop daemon runs in a Java process. Following completion of the course, you can take a one-hour test to become a Cloudera Certified Hadoop Administrator. The systems admin class and test covers Hadoop cluster operations, planning and management; job scheduling; monitoring and logging.
Plan your Hadoop architecture
For an on-premise cluster, once you start to have more than several dozen nodes, you will probably want to invest in three separate enterprise-grade servers, one for each of the following central daemons:
- NameNode
- SecondaryNameNode (Checkpoint Node)
- MapReduce Resource Manager
These enterprise-grade servers should be heavy on RAM memory, but do not require much of their own disk storage capacity — that’s the job of the DataNodes. For the NameNode memory, consider a baseline of enough RAM to represent 250 bytes per file plus 250 bytes per block. Note that for the blocks, most organizations will want to change the default block size from 64 MB to 128 MB. You can change that at dfs.block.size.
Beginning with Hadoop v0.23, but not yet included in Hadoop v1, is the option for HDFS federation to share the namespace among multiple NameNodes. Consider using HDFS federation if you must store a huge number of very small files. Each file, directory and block take up about 150 bytes of NameNode memory, making it impractical or impossible to store billions of files without using HDFS federation.
For large clusters, 32 GB memory for the NameNode should be plenty. Much more than 50 GB of memory may be counter-productive, as the Java virtual machine running the NameNode may spend inordinately long, disruptive periods on garbage collection.
Garbage collection refers to the process in which the JVM reclaims unused RAM. It can pop up at any time, for almost any length of time, with few options for system administrators to control it. As noted by Eric Bruno in a Dr. Dobb’s Report, the Real-Time Specification for Java (RTSJ) may solve the garbage collection problem, along with providing other benefits to enable JVMs to better support real-time applications. While the Oracle Java Real-Time System, IBM WebSphere Real-Time VM, and the Timesys RTSJ reference implementation support RTSJ, as a standard it remains in the pilot stage, particularly for Linux implementations.
If the NameNode is lost and there is not a backup, HDFS is lost. HDFS is based on the Google File System (GFS), in which there is no data caching. From the NameNode, you should plan to store at least one or two synchronous copies as well as a Network File System (NFS) mount disk-based image. At Yahoo and Facebook, they use a couple of NetApp filers to hold the actual data that the NameNode writes. In this architecture, the two NetApp filers are run in HA mode with non-volatile RAM (NVRAM) copying. HDFS now supports the option for a Standby NameNode to provide high-availability (HA) hot failover for the NameNode. The NameNode HA branch has merged into the HDFS trunk. Organizations with previous Hadoop releases (0.23.1 or older) can access the code through HDFS-1623.
The poorly named SecondaryNameNode (which is being renamed as the Checkpoint Node) is not a hot fail-over, but instead a server that keeps the NameNode’s log from becoming ever larger, which would result in ever-longer restart times and would eventually cause the NameNode to run out of available memory. On startup, the NameNode loads its baseline image file and then applies recent changes recorded in its log file. The SecondaryNameNode performs periodic checkpoints for the NameNode, in which it applies the contents of the log file to the image file, producing a new image. Even with this checkpoint, cluster reboots may take 90 minutes or more on large clusters, as the NameNode requires storage reports from each of the DataNodes before it can bring the file system online.
There is the option from Hadoop version 0.21 onward to run a Backup NameNode. However, as explained by MapR Co-Founder and CTO M.C. Srivas in a blog Q&A, even with a Backup NameNode, if the NameNode fails, the cluster will need a complete restart that may take several hours. You may be better off resurrecting the original NameNode from a synchronous or NFS mount copy versus using a Backup NameNode.
Future editions of HDFS will have more options for NameNode high-availability, such as a pair of NameNodes in an active-standby configuration (NameNode and StandbyNameNode) or a BookKeeper-based system built on ZooKeeper). If you need to support a fully distributed application, consider Apache ZooKeeper.
Beginning with YARN (Next-Generation MapReduce), MapReduce job tracking uses the following components and sub-components:
Source: graphic adapted by Brett Sheppard from Apache Hadoop YARN Release Documentation
(1) Resource Manager:
1a. Scheduler: You can use hierarchical queues or plug in MapReduce schedulers such as Capacity Scheduler or Fair Scheduler or workflow tools such as Azkaban or Oozie.
1b. Applications Manager: The Applications Manager is responsible for accepting job submissions, negotiating the first container to execute the Application Master, and restarting an Application Master container on failure.
1c. Resource Tracker: Contains settings such as the maximum number of Applications Master retries, how often to check that containers are still alive, and how long to wait until a Node Manager is considered dead.
(2) Each hardware node has a Node Manager agent that is responsible for managing, monitoring and reporting resource “containers” (CPU, memory, disk and network) to the Resource Manager / Scheduler. These containers replace the fixed Map and Reduce slots in previous-generation MapReduce.
(3) The per-application, paradigm-specific Application Master (App Mstr) schedules and executes application tasks. If your cluster uses multiple paradigms such as MapReduce and MPI, each will have its own Applications Master, such as the MapReduce Application Master and MPI (message passing interface) Application Master.
As with terminology such as namespace, you’ll often see these YARN components written as ResourceManager, NodeManager and ApplicationMaster. It is possible for the ApplicationMaster to communicate with more than one hardware node, so it is not a requirement to replicate the Application Master on every node. As shown on this chart, some nodes may only have containers, with the Application Master (App Mstr) residing on an adjacent node (for a example a node in the same rack using rack awareness).
For more information about Next-Generation MapReduce, refer to the YARN release notes.
Current-generation Hadoop does not support IPV6. For organizations with IPv6, investigate using machine names with a DNS server instead of IP addresses to label each node. While organizations in quickly growing markets such as China have been early adopters to IPv6 due to historical allocations of IPv4 addresses, IPv6 is started to get more attention in North America and other regions too.
For the DataNodes, expect failure. With HDFS, when a DataNode crashes, the cluster does not crash, but performance degrades in proportion to the amount of lost storage and processing capacity as the still-functioning DataNodes pick up the slack. In general, don’t use RAID for the DataNodes, and avoid using Linux Logical Volume Manager (LVM) with Hadoop. HDFS already offers built-in redundancy by replicating blocks across multiple nodes.
Facebook has worked on HDFS RAID. And NetApp is one organization that does advocate use of RAID for the DataNodes. According to an email exchange with NetApp head of strategic planning Val Bercovici on June 26, 2011: “NetApp’s E-Series Hadooplers use highly engineered HDFS RAID configurations for DataNodes which separate data protection from job and query completion… we are witnessing improved Extract and Load performance for most Hadoop ETL tasks, plus the enablement of Map Reduce pipelining for Transformations not previously possible. Long-tail HDFS data can also be safely migrated to RAID-protected Data Nodes using a rep count of 1 for much greater long-term HDFS storage efficiency.”
For total storage per DataNode, 12 terabytes is common, although this is increasing. According to a Hortonworks presentation at Hadoop World 2011, each DataNode may have 16 (or more) cores, 48G/96G RAM and 24TB/36TB disks.
In addition to file storage, DataNodes require about 30 percent of disk capacity to be set aside as free disk space for ephemeral files generated during MapReduce processing. For memory, a previous rule of thumb for each DataNode was to plan between 1 GB and 2 GB of memory per Map or Reduce task slot. This changes though with Next-Generation MapReduce / YARN, which replaces fixed Map and Reduce slots with virtual containers.
Hadoop gives you the option to compress data using the codec you specify. For example, at Facebook, they rely on the gzip codec with a compression factor of between six and seven for the majority of their data sets. (SIGMOD’10 presentation, June 2010, “Data Warehousing and Analytics Infrastructure at Facebook”).
Try to standardize on a hardware configuration for the DataNodes. You can run multiple families of hardware, but that does complicate provisioning and operations. When you have nodes that use different hardware, your architecture begins to be more of a grid than a cluster
As well, don’t expect to use virtualization — there is a major capacity hit. Hadoop works best when a DataNode can access all its disks. Hadoop is a highly scalable technology, not a high-performance technology. Given the nature of HDFS, you are much better off with data blocks and co-located processing spread across dozens, hundreds or thousands of independent nodes. If you have a requirement to use virtualization, consider assigning one VM to each DataNode hardware device; this would give you the benefit of virtualization such as for automated provisioning or automated software updates but keep the performance hit as low as possible.
Several operations tips for system admins:
- Aim for large size files: Try not to store too many small files. There is overhead per file in the NameNode memory. Some small files are fine — even hundreds or thousands of them — but you should try to have a fair number of files that are a 100 Megabyte, single-digit Gigabyte, or larger.
- No spaces in comma-separated lists in configuration files: spaces can introduce errors.
- Load balance: Remember to run load balancer periodically to update nodes that may be over or under utilized. Rebalancing does not interfere with MapReduce jobs.
- Equip rack awareness: Remember to define and update rack configurations to support rack awareness, so that HDFS can recognize the nearest nodes. Note that this does not apply for Amazon Elastic Compute Cloud, which to date does not support rack-awareness.
- Run fsck daily during off-hours to check for corruption in HDFS.
- Synch the clocks on the nodes (a basic but easy-to-forget step).
From Facebook, Application Operations Engineer Andrew Ryan shared lessons learned for Hadoop cluster administrators at the Bay Area Hadoop User Group (HUG) meetup in February 2011 at the Yahoo Sunnyvale campus. A few of the suggestions from his excellent talk:
- Maintain a central registry of clusters, nodes, and each node’s role in the cluster, integrated with your service/asset management platform.
- Failed/failing hardware is your biggest enemy — the ‘excludes’ file is your friend.
- Never fsck ext3 data drives unless Hadoop says you have to.
- Segregate different classes of users on different clusters, with appropriate service levels and capacities.
While it may seem obvious with a cluster, it’s still worth a reminder that Hadoop is not yet well suited for running a cluster that spans more than one data center. Even Yahoo, which runs the largest private-sector Hadoop production clusters, has not divided Hadoop file systems or MapReduce jobs across multiple data centers. Organizations such as Facebook are considering ways to federate Hadoop clusters across multiple data centers, but it does introduce challenges with time boundaries and overhead for common dimension data. Expedia is running production Hadoop clusters than span across more than one data center, per an Expedia presentation at O’Reilly Strata 2012 by Senior Director of Architecture and Engineering Mr. Eddie Satterly.
Import data into HDFS
Regardless of the source of the data to store in the cluster, input is through the HDFS API. For example, you can collect log data files in Apache Chukwa, Cloudera-developed Flume, or Facebook-developed Scribe and feed those files through the HDFS API into the cluster, to be divided up into HDFS’ block storage. One approach for streaming data such as log files is to use a staging server to collect the data as it comes in and then feed it into HDFS using batch loads.
Sqoop is designed to import data from relational databases. Sqoop imports a database table, runs a MapReduce job to extract rows from the table, and writes the records to HDFS. You can use a staging table to provide insulation from data corruption. It can be helpful to begin with an empty export table and not use the same table for both imports and exports. You can export from SQL databases straight into a Hive data warehouse or HBase tables. You can also use Oozie with Sqoop to schedule import and export tasks. You can download Sqoop directly from the Apache Sqoop project page or as part of Hadoop distributions such as Cloudera’s.
Since data transfer to / from relational databases and Hadoop using JDBC or ODBC can be slow, many vendors provide faster direct connectors that support native tools, often via an extension to Sqoop. Vendors with direct connectors include EMC Greenplum, IBM Netezza, Microsoft SQL Server, Microsoft Parallel Data Warehouse (PDW), Oracle and Teradata Aster Data, among others. Quest developed a connector for Oracle (available as a freeware plug-in to Sqoop). More recently, Oracle partnered with Cloudera to provide a Hadoop distribution and support for the Oracle Big Data Appliance.
Manage jobs and answer queries
You have the choice of several job schedulers for MapReduce. Fair Scheduler, developed by Facebook, provides for faster response times for small jobs and quality of service for production jobs. It is an upgrade from the first-in, first out (FIFO) scheduler that is set as the default by Hadoop MapReduce. With Fair Scheduler, jobs are grouped into pools, and you can assign pools a minimum number of map slots and reduce slots, and a limit on the number of running jobs. There is no option to cap maximum share for map slots or reduce slots (for example if you are worried about a poorly written job taking up too much cluster capacity), but one option to get around this is giving each pool enough of a guaranteed minimum share that they will hold off the avalanche of an out-of-control job.
With Capacity Scheduler, developed by Yahoo, you can assign priority levels to jobs, which are submitted to queues. Within a queue, when resources become available, they are assigned to the highest priority job. Note that there is no preemption once a job is running to take back capacity that has already been allocated.
Yahoo developed Oozie for workflow management. It is an extensible, scalable and data-aware service to orchestrate dependencies between jobs running on Hadoop, including HDFS, Pig and MapReduce.
Azkaban provides a batch scheduler for constructing and running Hadoop jobs or other offline processes. At LinkedIn, they use a combination of Hadoop to process massive batch workloads, Project Voldemort for a NoSQL key/value storage engine, and the Azkaban open-source workflow system to empower large-scale data computations of more than 100 billion relationships a day and low-latency site serving. LinkedIn is supporting Azkaban as an open source project, and supplies code at the Azkaban github.
For organizations that use Eclipse as an integrated development environment (IDE), you can set up a Hadoop development environment under an Eclipse IDE. With the Hadoop Eclipse Plug in, you can create Mapper, Reducer and Driver classes; submit MapReduce jobs; and monitor job execution.
Karmasphere Studio provides a graphical environment to develop, debug, deploy and optimize MapReduce jobs. Karmasphere supports a free community edition and license-based professional edition.
You can query large data sets using Apache Pig, or with R using the R and Hadoop Integrated Processing Environment (RHIPE). With Apache Hive, you can enable SQL-like queries on large data sets as well as a columnar storage layout using RCFile.
Tableau and Cloudera partnered for a Tableau-to-HDFS direct connector that provides a SQL interface to Hadoop available from Tableau Desktop beginning with version 7. It includes supports for XML objects stored in HDFS. Within Tableau Desktop, you can tune the connectors to set workload parameters for MapReduce jobs. You can also export from HDFS into Tableau when you need faster analytics using Tableau’s in-memory data engine.
The MicroStrategy 9 Platform allows application developers and data analysts to submit queries using HiveQL and view Hadoop data in MicroStrategy dashboards, for on-premise Hadoop clusters or cloud offerings such as Amazon Elastic MapReduce. Groupon adopted MicroStrategy to analyze Groupon’s daily deals, obtain a deeper understanding of customer behavior, and evaluate advertising effectiveness. Groupon staff can use MicroStrategy-based reports and dashboards for analysis of their data in Hadoop and HP Vertica.
SAS announced plans in February 2012 to support HDFS, including a hardware-ready software package designed to run on blade servers with lots of RAM to power in-memory analytics.
Jaspersoft supports three primary modes of access to data in Hadoop. First, directly though Hive, to accept SQL-like queries through HiveQL. This approach can suit IT staff or developers who want to run batched reports, but current-generation Hive can be a rather slow interface, so it’s not ideal for use cases that require a low-latency response.
Second, Jaspersoft provides connectivity directly to HBase. Jaspersoft feeds this data into its in-memory engine through an HBase connector. This approach can work well for a business analyst to explore data stored in Hadoop without the need to write MapReduce tasks.
HBase has no native query language, so there’s no filtering language. But there are filtering APIs. Jaspersoft’s HBase connector supports various Hadoop filters from simple ones such as StartRow and EndRow to more complex ones such as RowFilter, FamilyFilter, ValueFilter, or SkipValueFilter. The Jaspersoft HBase query can specify the ColumnFamilies and/or Qualifiers that are returned; some HBase users have very wide tables, so this can be important for performance and usability. The Jaspersoft HBase connector ships with a deserialization engine (SerDe) framework for data entered via HBase’s shell and for data using Java default serialization; users can plug in their existing deserialization .jars so the connector will automatically convert from HBase’s raw bytes into meaningful data types.
Third, you can use a data integration process through Informatica or other ETL providers into a relational database that Jaspersoft software can then report on directly or perform analysis on through Jaspersoft’s in-memory database or OLAP engine.
To enable applications outside of the cluster to access the file system, the Java API works well for Java programs. For example, you can use a java.net.url object to open a stream. You can use the Thrift API to connect to programs written in C++, Perl, PHP, Python, Ruby or other programming languages.
Strengthen security
There are some ease-of-use advantages to running password-less Secure Shell (SSH) — for example you can start and stop all of the cluster nodes with simple commands — but your organization may have security policies that prevent use of password-less SSH. In general, the start-all.sh and stop-all.sh commands are useful for running a Hadoop evaluation or test cluster, but you probably do not need or want to use them for a production cluster.
Earlier versions of HDFS did not provide robust security for user authentication. A user with a correct password could access the cluster. Beyond the password, there was no authentication to verify that users are who they claim to be. To enable user authentication for HDFS, you can use a Kerberos network authentication protocol. This provides a Simple Authentication and Security Layer (SASL), via a Generic Services Application Program Interface (GSS-API). This setup uses a Remote Procedure Call (RPC) digest scheme with tokens for Delegation, Job and Block Access. Each of these tokens is similar in structure and based on HMAC-SHA1. Yahoo offers an explanation for how to set up the Oozie workflow manager for Hadoop Kerberos authentication.
After the three-step Kerberos ticket exchange, Hadoop uses delegation tokens to continue to allow authenticated access without having to go back each time to contact the Kerberos key distribution center (KDC).
Kerberos authentication is a welcome addition, but by itself does not enable Hadoop to reach enterprise-grade security. As noted by Andrew Becherer in a presentation and white paper for the BlackHat USA 2010 security conference, “Hadoop Security Design: Just add Kerberos? Really?,” remaining security weak points include:
- Symmetric cryptographic keys are widely distributed.
- Some web tools for Job Tracker, Task Tracker, nodes and Oozie rely on pluggable web user interface (UI) with static user authentication. There is a jira (HADOOP-7119), which is patch-available, that adds a SPNEGO-based web authentication plugin.
- Some implementations use proxy IP addresses and a database of roles to authorize access for bulk data transfer to provide a HTTP front-end for HDFS.
Given the limited security within Hadoop itself, even if your Hadoop cluster will be operating in a local- or wide-area network behind an enterprise firewall, you may want to consider a cluster-specific firewall to more fully protect non-public data that may reside in the cluster. In this deployment model, think of the Hadoop cluster as an island within your IT infrastructure — for every bridge to that island you should consider an edge node for security.
In addition to a network firewall around your cluster, you could consider a database firewall or broader database activity monitoring product. These include AppSec DbProtect, Imperva SecureSphere and Oracle Database Firewall. A database firewall enables rules-based determination of whether to pass, log, alert, block or substitute access to the database. Database firewalls are a subset of the broader software category of database monitoring products. Note that most database firewall or activity monitoring products are not yet set up for out-of-the-box Hadoop support, so you may require help from the database firewall vendor or a systems integrator.
Other security steps may also be necessary to secure applications outside of the cluster that are authorized and authenticated to access the cluster. For example, if you choose to use the Oozie workflow manager, Oozie becomes an approved “super user” that can perform actions on behalf of any Hadoop user. Accordingly, if you decide to adopt Oozie, you should consider an additional authentication mechanism to plug into Oozie.
Some of the above security concerns you may be able to address using paid software, e.g. Cloudera Enterprise or Karmasphere Studio, such as the use of management applications in place of the web user interfaces that come with the Hadoop daemons. For example, Cloudera Enterprise 3.5 includes some tools to help simplify configuration of the security features available with current-generation Hadoop. Zettaset (previously GOTO Metrics) bundles security enhancements into its Hadoop Orchestrator, including user-level security and audit tracking, and plans to add encryption options for HDFS.
Add to your Hadoop toolbox
As noted by Mike Loukides in “What is Data Science?,” “If anything can be called a one-stop information platform, Hadoop is it.” The broad Hadoop ecosystem provides a variety of choices for tools and capabilities among Apache projects and sub-projects, other open source tools, and proprietary software offerings. These include the following:
- For serialization, Apache Avro is designed to enable native HDFS clients to be written in languages other than Java. Other possible options for serialization include Google Protocol Buffers (Protobuf) and Binary JSON (BSON).
- Cascading is an open-source, data-processing API that sits atop MapReduce, with commercial support from Concurrent. Cascading supports job and workflow management. According to Concurrent founder and CTO Chris Wensel, in a single library you receive Pig/Hive/Oozie functionality, without all the XML and text syntax. Nathan Marz wrote db-migrate, a Cascading-based JDBC tool for import/export onto HDFS. At BackType and previously Rapleaf, Nathan also authored Cascalog, a Hadoop/Cascading-based query language hosted in Clojure. Multitool allows you to “grep”, “sed”, or join large datasets on HDFS or Amazon S3 from a command line.
- Hadoop User Experience (HUE) provides “desktop-like” access to Hadoop via a browser. With HUE, you can browse the file system, create and manage user accounts, monitor cluster health, create MapReduce jobs, and enable a front end for Hive called Beeswax. Beeswax provides Wizards to help create Hive tables, load data, run and manage Hive queries, and download results in Excel format. Cloudera contributed HUE as an open source project.
- Pervasive TurboRush for Hive allows Hive to generate an execution plan using dataflow graphs as an alternative to MapReduce. It then executes these graphs using Pervasive DataRush distributed across the machines of the cluster.
- Pentaho offers a visual design environment for data integration, extract transform load (ETL), report design, analytics and dashboards that integrates with HDFS, MapReduce, Hive and HBase, plus Apache Cassandra and MongoDB. Pentaho open-sourced its Kettle ETL project under an Apache version 2.0 license.
- Karmasphere Analyst provides Visual SQL access to data in Hadoop, that can support visualizations in Tableau or Microsoft Excel. A second product, Karmasphere Studio, provides a graphical environment to develop, debug, deploy and optimize MapReduce jobs, and is available through a free community edition or license-based professional edition. In addition to supporting on-premise Hadoop implementations behind firewalls through SSH tunnels and SOCKS proxies, Karmasphere has integrated with Amazon Elastic MapReduce (EMR) and provides an EMR-friendly pricing option to pay-as-you-go as an alternative to an annual subscription.
- Datameer offers a spreadsheet-like interface for analysts to work with data in Hadoop as one part of their Datameer Analytics Solution. Additional features include a Wizard tool for loading and transforming large data sets, a dashboard widget to visualize data based on analytic workbooks, support for up to 32 decimal places for high-precision stats, and integration with external LDAP and Active Directory connections to authenticate groups of users. Note that DAS uses a “spreadsheet-like interface” instead of plugging directly into Microsoft Excel.
- Modeled after Google BigTable, Apache HBase is a distributed column-oriented database built on top of HDFS. With HBase, you can run real-time read and write random access to large data sets. You can use HBase as a back-end for materialized views; according to Facebook, this can support real-time analytics.
- HCatalog is a metadata tool for Hadoop, built on top of the Hive metastore. It provides read and write interfaces for Pig and MapReduce together with a command line interface for data definitions. HCatalog offers a shared schema and data model for Pig, Hive and MapReduce. HCatalog was promoted to an Apache project.
- The Hadoop Online Prototype (HOP) is a modified version of Hadoop MapReduce that allows data to be pipelined between tasks and between jobs. This can enable better cluster utilization and increased parallelism, and allows new functionality: online aggregation (approximate answers as a job runs), and stream processing (MapReduce jobs that run continuously, processing new data as it arrives). Note that HOP is a development prototype that is not production-ready at this stage.
- VMware extended its Spring development framework (from the SpringSource acquisition) with “Spring Hadoop” in February 2012, with support for MapReduce, Streaming, Hive, Pig, and Cascading jobs via a Spring container.
One of the benefits of Hadoop’s loosely coupled architecture is the ability to replace components such as HDFS or MapReduce. As a data-centric architecture with loose coupling, Hadoop supports modular components. As noted by Rajive Joshi in a March 2011 InformationWeek article, “The key to data-centric design is to separate data from behavior. The data and data-transfer constructs then become the primary organizing constructs.” That’s not to say that there is complete plug and play with no integration work needed among Hadoop components (the proposed Apache Bigtop project may help in this area), but there is no requirement for every organization to use the same monolithic stack.
Several startups have emerged recently with offerings that replace elements of the Hadoop stack with different approaches. These include the following:
- DataStax Brisk builds a modified version of Apache Hadoop MapReduce and Apache Hive to run on top of Cassandra in place of HDFS.
- The Appistry CloudIQ Storage Hadoop Edition replaces HDFS with CloudIQ Storage.
- Hadapt adds an adaptive query engine and replacements to HBase and Hive.
Given Hadoop’s increasing market penetration, it’s not surprising to begin to see more alternatives or competitors to Hadoop begin to emerge. These include Spark and LexisNexis HPCC.
Spark was developed in the UC Berkeley AMP Lab, and is used by several research groups at Berkeley for spam filtering, natural language processing and road traffic prediction. The AMP Lab developed Spark for machine learning iterative algorithms and interactive data mining. Online video analytic service provider Conviva uses Spark. Spark is open source under a BSD license. Spark runs on the Mesos cluster manager, which can also run Hadoop applications. Mesos adopters include Conviva, Twitter and UC Berkeley. Mesos joined the Apache Incubator in January 2011.
In June 2011, LexisNexis announced a high performance computing cluster (HPCC) alternative to Hadoop. HPCC Systems announced plans for a free community version along with an enterprise edition that comes with access to support, training and consulting. Sandia National Laboratories uses its precursor technology, the data analytics supercomputer (DAS) platform, to sort through petabytes of data to find correlations and generate hypotheses. According to LexisNexis, configurations by HPCC Systems require fewer nodes to provide the same processing performance as a Hadoop cluster, and are faster in some benchmark tests.
However, it’s unclear what types of semi-structured, unstructured or raw data analysis will perform faster and / or on fewer nodes with LexisNexis / HPCC Systems. LexisNexis may struggle to create as vibrant of an ecosystem of companies and contributors as what the Apache Hadoop community has achieved. And their HPCC technology uses the ECL programming language, which has not been widely adopted outside of LexisNexis or occasional use in government or academia.
To wrap up
Hadoop is maturing as an information platform to store, process and analyze huge volumes of varied semi-structured, unstructured and raw data from disparate sources. To get started:
- Evaluate one of the free distributions in stand-alone or pseudo-distributed mode.
- Refer to Tom White’s “Hadoop: The Definitive Guide, Second Edition” (with the Third Edition available as an Early Release) and consider taking one or more of the Hadoop courses from Cloudera, Hortonworks, or another of the service providers listed on the Apache Hadoop wiki support page.
- For an on-premise cluster, invest in separate enterprise-grade servers for the NameNode, SecondaryNameNode and MapReduce Resource Manager.
- Remember operation tips for rack awareness, file system checks and load balancing.
- Beef up security with user authentication, an edge node security firewall and other security measures.
What deployment tips, cautions or best practices would you like to add or comment on based on your own experience with Hadoop?
My thanks for comments on the draft article to Val Bercovici, Michele Chambers, Julianna DeLua, Glynn Durham, Jeff Hammerbacher, Sarah Sproehnle, M.C. Srivas, and Chris K. Wensel.
Related: