 White picket fence. (source: PublicDomainPictures.net)
White picket fence. (source: PublicDomainPictures.net) One of the most important goals of any data science team is the ability to create machine learning models, evaluate them offline, and get them safely to production. The faster this process can be performed, the more effective most teams will be. In most organizations, the team responsible for scoring a model and the team responsible for training a model are separate. Because of this, a clear separation of concerns is necessary for these two teams to operate at whatever speed suits them best. This post will cover how to make this work: implementing your ML algorithms in such a way that they can be tested, improved, and updated without causing problems downstream or requiring changes upstream in the data pipeline.
We can get clarity about the requirements for the data and production teams by breaking the data-driven application down into its constituent parts. In building and deploying a real-time data application, the goal of the data science team is to produce a function that reliably and in real-time ingests each data point and returns a prediction. For instance, if the business concern is modeling churn, we might ingest the data about a user and return a predicted probability of churn. The fact that we have to featurize that user and then send them through a random forest, for instance, is not the concern of the scoring team and should not be exposed to them.

The above illustration shows a perfect world for the scoring team. They have some data type A that they can analyze—the set of features that your software has observed. A can be a JSON message describing a user, or A can be a Protocol Buffer describing a transaction, or an Avro message describing an item. They then have a model that performs some task—churn prediction, chargeback probability, etc. They then get a result that they use to continue processing.
In order to achieve this goal, the data science team has to have tooling that does at least two things at score time:
- Create a model that can ingest and return the expected native data type
- Be able to supply an external representation of a model
In order to address the first issue, we have to realize that the act of featurization must be embedded in the model. Not only does that make the scoring team’s job easier, it also removes a potential source of error, namely feature functions that are different at train and score time. For instance, if the data science team works in R and takes data from a database to make a model, but the scoring team works in Java, then R feature functions will have to be reimplemented at score time in Java. The below training diagram shows what a supervised training architecture might look like using generic types.
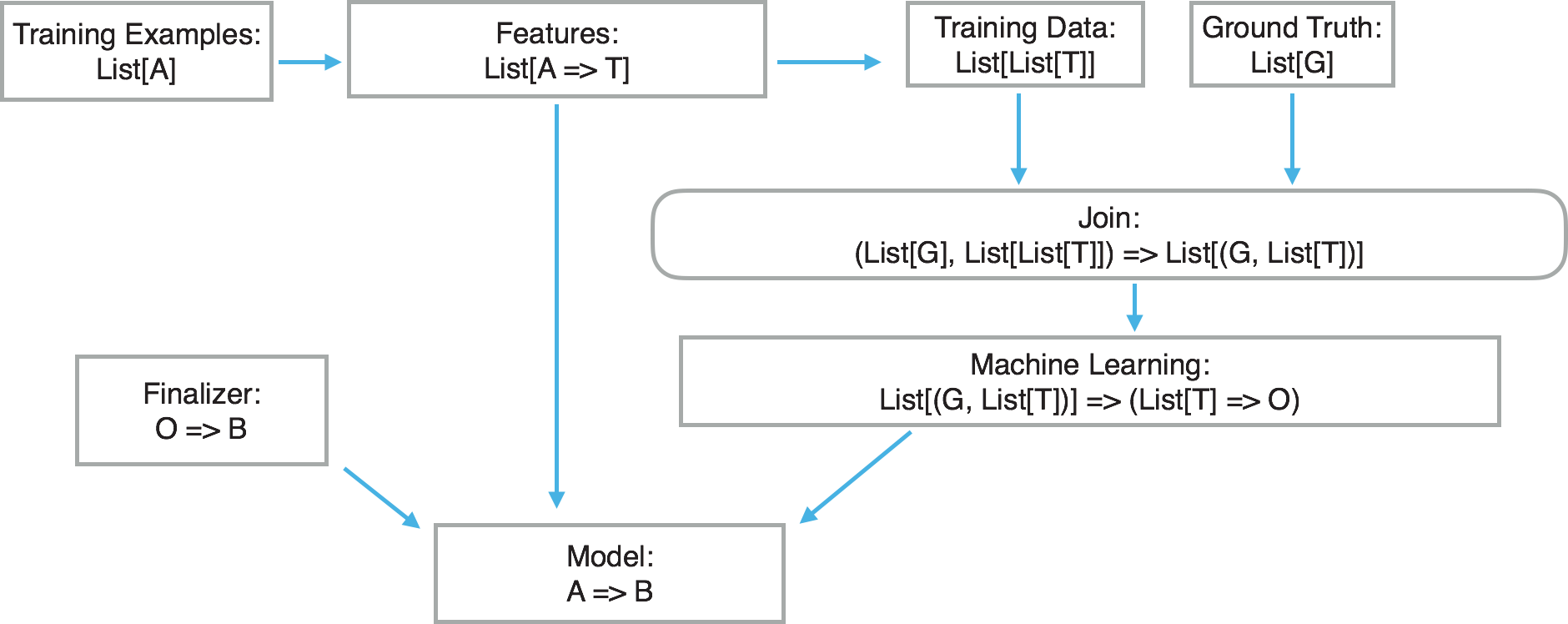
While this looks complicated, it should seem pretty familiar to most data scientists after breaking it down. First, we start with training data of some type we’ll call A. This is historical data, such as users at specific times. As a side note, it is incredibly important to make sure that the historical data is time-bounded to avoid information leak. We then take those training examples and featurize them through feature functions we have constructed. These functions all convert a single data type A into a single data type T. Type T is frequently either a scalar value forming a CSV file or a sequence of values for input formats such as LibSVM or Vowpal Wabbit. In both cases, a single List[T] is natively understandable by a machine learning library as one row of featurized data. We will then have a separate list List[G] of observations of ground truth G that we have to join to the featurized training data List[List[T]]. The result is input data that is legible to our machine learning library, whose format per row is (G, List[T]).
Once we have a List[(G, List[T])], we can use any supervised learning framework to train a model. The output of this is a machine learning model, a function defined as List[T] => O. O is the native output type of the model used, which may or may not be the desired output type of the whole model—the output defined by your business needs. A good example of this would be a segmentation model where we desire to classify users as either highly likely to churn, somewhat likely to churn, or unlikely to churn. The output type desired by the calling code is an enum, but the model itself may output a float. We will then use a finalizer to convert that float into an enum through simple segmentation. In the case where the output type of the native model is the same as the type desired, the identity function may be used as the finalizer.
One important caveat to note is that the machine learning model List[T] => O is in the native format of the library used to learn it, such as a Vowpal Wabbit model or H2O. These dependencies are now needed by the whole model. Traditionally, this is a pain point for most machine learning systems in production, as it locks in a specific learning framework that is then difficult to change in the future. In our formulation, however, the types needed by the framework-specific model are not exposed to the calling code. Because of this, the framework-specific model can be swapped out at any time without changing the type contract guaranteed at score time. This is accomplished through the use of function composition. This is a huge win for both the data science team as well as the scoring team. It allows the data science team to be flexible and use the library that best solves each individual problem. It also allows easy version upgrades of specific libraries without fear of breaking models. It makes life easier for the scoring team, too, as they don’t have to fret over understanding any of the machine learning frameworks and can instead focus on scale and reliability.
This work is so important to me that I led a team that has open-sourced these ideas as a project called Aloha. Aloha is an implementation of many of these ideas within a Scala DSL. Aloha is supported by a community of production data scientists, lead by Ryan Deak, the main author of the project. This project has received commercial support from both eHarmony and ZEFR, and is currently under active development. Aloha has streamlined the model deployment process and reduced production error rates in multiple deployment environments to date.
A nice benefit to controlling the featurization layer is that we can place a QA engine within the model itself. In the future, we plan to be able to add arbitrary QA tests to model inputs and take an action (such as an email) if such conditions are not satisfied. For instance, if we observe a feature is present in 90% of examples at train time and then through the use of a sliding window see that it is only present in 10% of examples at score time, then the model may perform very poorly through no fault of its own, but rather because of a data preparation issue. This information can be encoded in an Aloha model, and an action can be associated with it to trigger notification if the data drifts at score time.
Having a quick and safe path to production should be a top priority for all engineering teams, and data science is no exception. While I have seen many approaches to productionalizing data science, any of them that don’t put machine learned models directly from the data scientist’s code to production fall short of realizing their full potential.