
 Goe Platz der Synagoge Detail (source: Daniel Schwen on Wikimedia Commons)
Goe Platz der Synagoge Detail (source: Daniel Schwen on Wikimedia Commons) Many workflows that utilize TensorFlow need GPUs to efficiently train models on image or video data. Yet, these same workflows typically also involve multi-stage data pre-processing and post-processing, which might not need to run on GPUs. This mix of processing stages, illustrated in Figure 1, results in data science teams running things requiring CPUs in one system while trying to manage GPUs resources separately by yelling across the office: “Hey is anyone using the GPU machine?” A unified methodology is desperately needed for scheduling multi-stage workflows, managing data, and offloading certain portions of the workflows to GPUs.
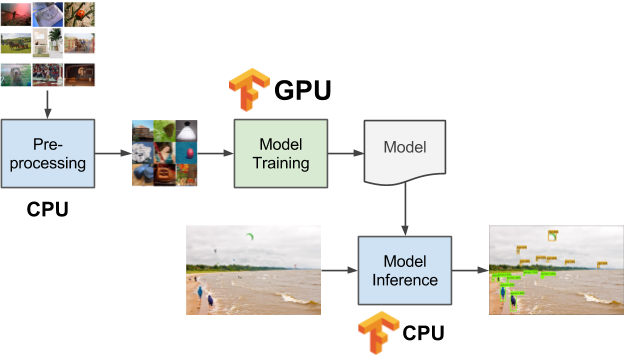
Pairing Kubernetes with TensorFlow enables a very elegant and easy-to-manage solution for these types of workflows. For example, Figure 1 shows three different data pipeline stages. Pre-processing runs on CPUs, model training on GPUs, and model inference again on CPUs. One would need to deploy and maintain each of these stages on a potentially shared set of computational resources (e.g., cloud instances), and that’s what Kubernetes does best. Each of the stages can be containerized via Docker and declaratively deployed on a cluster of machines via Kubernetes (see Figure 2).
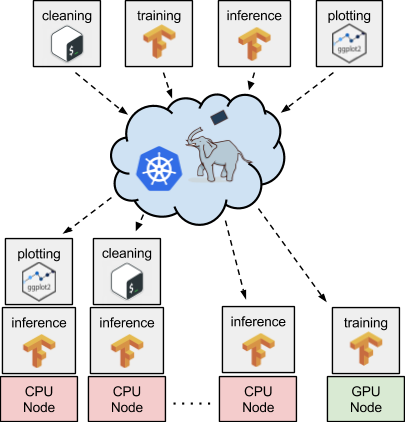
Along with this scheduling and deployment, you can utilize other open source tooling in the Kubernetes ecosystem, such as Pachyderm, to make sure you get the right data to the right TensorFlow code on the right type of nodes (i.e., CPU or GPU nodes). Pachyderm serves as a containerized data pipelining layer on top of Kubernetes. With this tool, you can subscribe your TensorFlow processing stages to particular versioned collections of data (backed by an object store) and automatically gather output, which can be fed to other stages running on the same or different nodes. Moreover, sending certain stages of our workflow, such as model training, to a GPU is as simple as telling Pachyderm via a JSON specification that a stage needs a GPU. Pachyderm will then work with Kubernetes under the hood to schedule that stage on an instance having a GPU.
Sound good? Well then, get yourself up and running with TensorFlow + GPUs on Kubernetes as follows:
- Deploy Kubernetes to the cloud of your choice or on premise. Certain cloud providers, such as Google Cloud Platform, even have one-click Kubernetes deploys with tools like Google Kubernetes Engine (GKE).
- Add one or more GPU instances to your Kubernetes cluster. This may involve creating a new node pool if you are using GKE or a new instance group if you are using kops. In any event, you will need to update your cluster and then install GPU drivers on those GPU nodes. By way of example, you could add a new node pool to your alpha GKE cluster (which takes advantage of the latest GPU features) via
gcloud:
$ gcloud alpha container node-pools create gpu-pool --accelerator type=nvidia-tesla-k80,count=1 --machine-type <your-chosen-machine-type> --num-nodes 1 --zone us-east1-c --image-type UBUNTU --cluster <your-gke-cluster-name>
Then you could ssh into that cluster and add nvidia GPU drivers:
$ curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb $ sudo -s $ dpkg -i cuda-repo-ubuntu1604_8.0.61-1_amd64.deb $ apt-get update && apt-get install cuda -y
- Deploy Pachyderm on your Kubernetes cluster to manage data pipelining and your collections of input/output data.
- Docker-ize the various stages of your workflow.
- Deploy your data pipeline by referencing your Docker images and the commands in JSON specifications. If you need a GPU, just utilize the resource requests and limits provided by Kubernetes to grab one. Note, you may need to add the path to your GPU drivers to the LD_LIBRARY_PATH environmental variable in the container as further discussed here.
If you have questions or need more information:
- Check out the docs on scheduling GPUs with Kubernetes.
- Check out the Pachyderm docs.
- Get help with you deploy by joining the public Pachyderm Slack and/or Kubernetes Slack.
- Run a Tensorflow + Kubernetes example.
This post is part of a collaboration between O’Reilly and TensorFlow. See our statement of editorial independence.