How network professionals deal with attacks and disruptions
A new survey highlights concerns from network and cloud administrators, and reveals their coping strategies.
 Compass (source: Pixabay)
Compass (source: Pixabay)
Reliability and response time are always pressing concerns for internet services. We’ve known for a long time that people on desktop or laptop computers have scant patience for slow websites, and the growing move to mobile devices makes the demands on internet services even worse.
O’Reilly Media and Oracle Dyn teamed up this year to survey network operators about where their resilience problems lie, what they’re doing to avoid these problems, and what it’s like to work in the field of network operations. The survey paid particular attention to issues of working in third-party cloud services, but covered a wide range of other problems in networking as well. Among the findings, we were surprised to hear the chief complaint of respondents in regard to resilience: their own ISP! We also uncovered a high concern over staff burnout, and disparities in the training of operators and in the handling of incidents.

Learn faster. Dig deeper. See farther.
This article starts with a brief description of the survey and who responded. Then we’ll get into the most interesting of the findings. We’ll end with some speculations about automation.
Who responded to the survey?
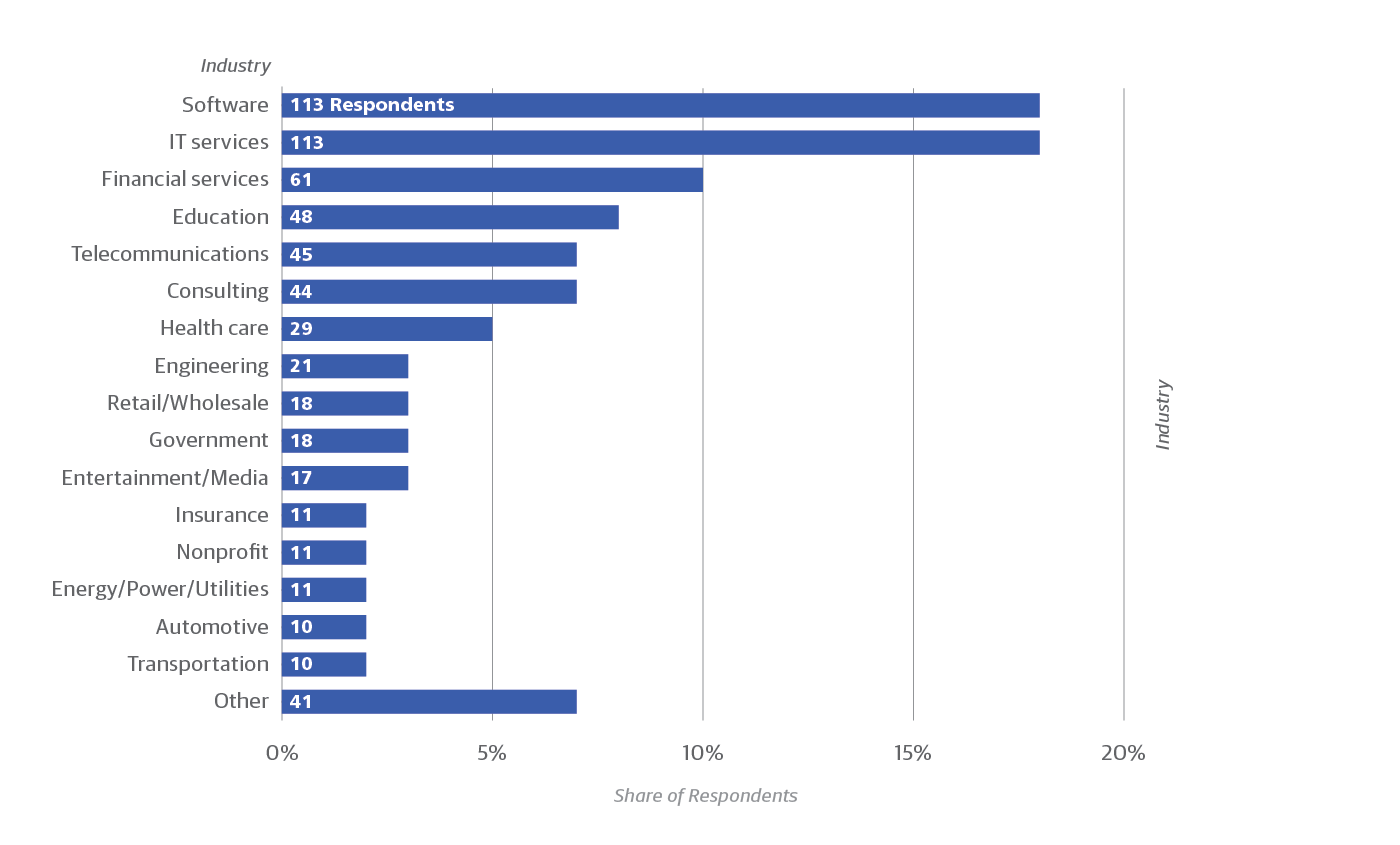
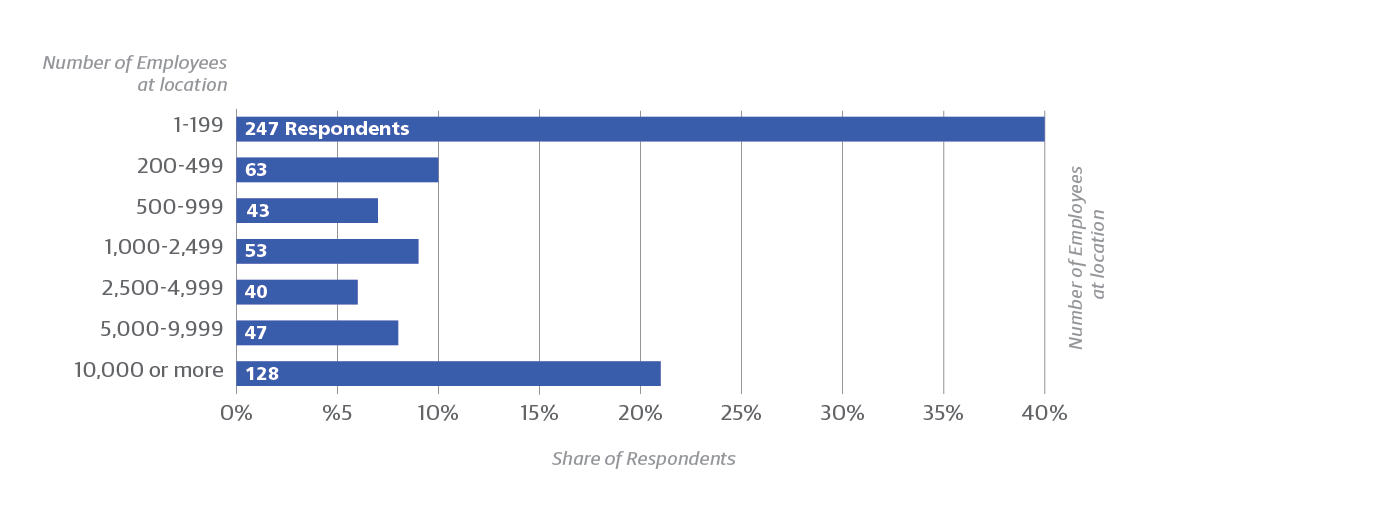
We collected answers to our survey from 621 network professionals with a variety of job descriptions (see Figure 1). Respondents work in many different industries, although IT services and software dominate. Organizational size was lopsided at the edges of the spectrum (Figure 2), with the largest fraction of respondents employing fewer than 200 people, and the next largest fraction having 10,000 or more. Small percentages represented in-between company sizes.
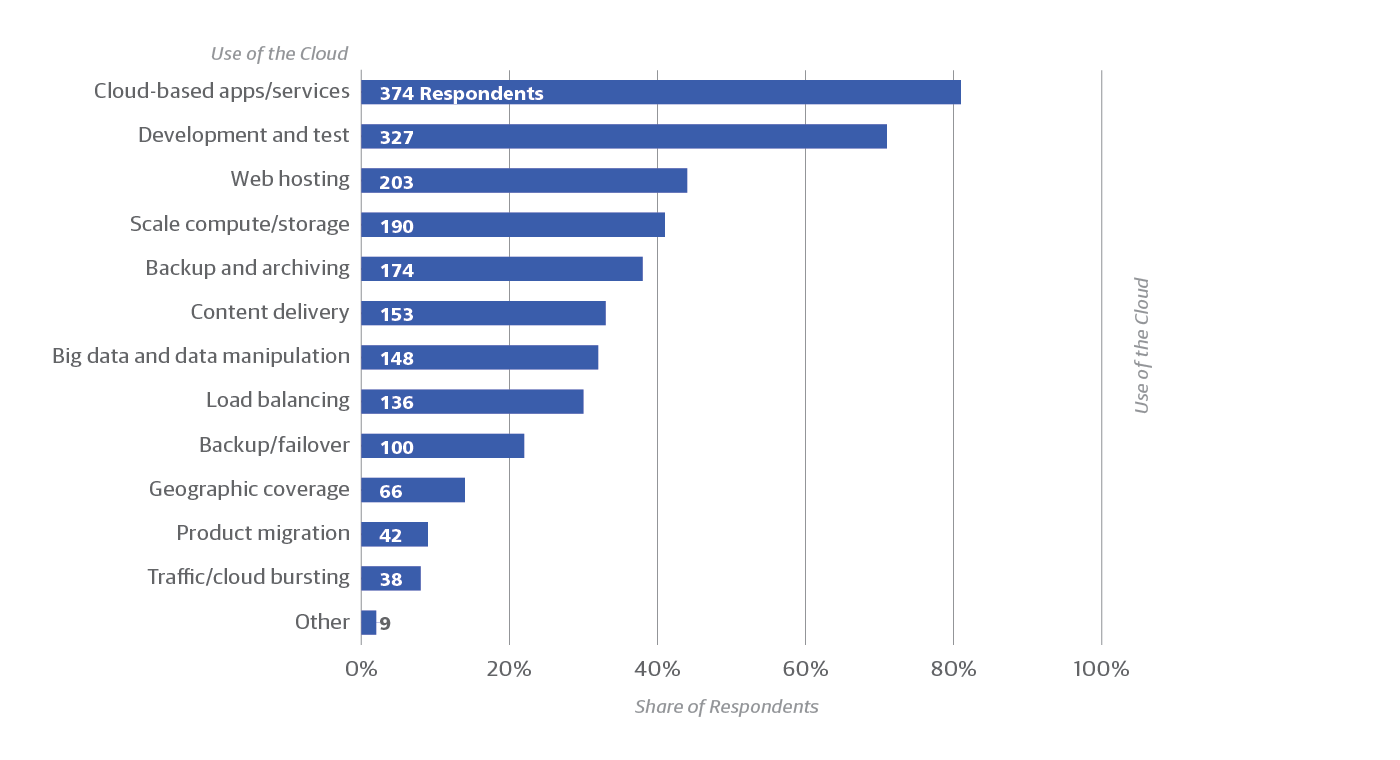
The majority of respondents taking the survey (459, or 74%) reported working in the cloud. These respondents were asked further questions about what resilience problems they experienced and what measures they took to deal with them (Figure 3). The most common use for the cloud was apps/services (81% of cloud users) and development/testing (71%). Historically, we know that many organizations started their cloud use with development and testing before taking the leap of putting their production systems there. As one might expect, the cloud is also popular for web hosting, scaling compute power or storage, and backups.
The biggest single problem: Your own ISP
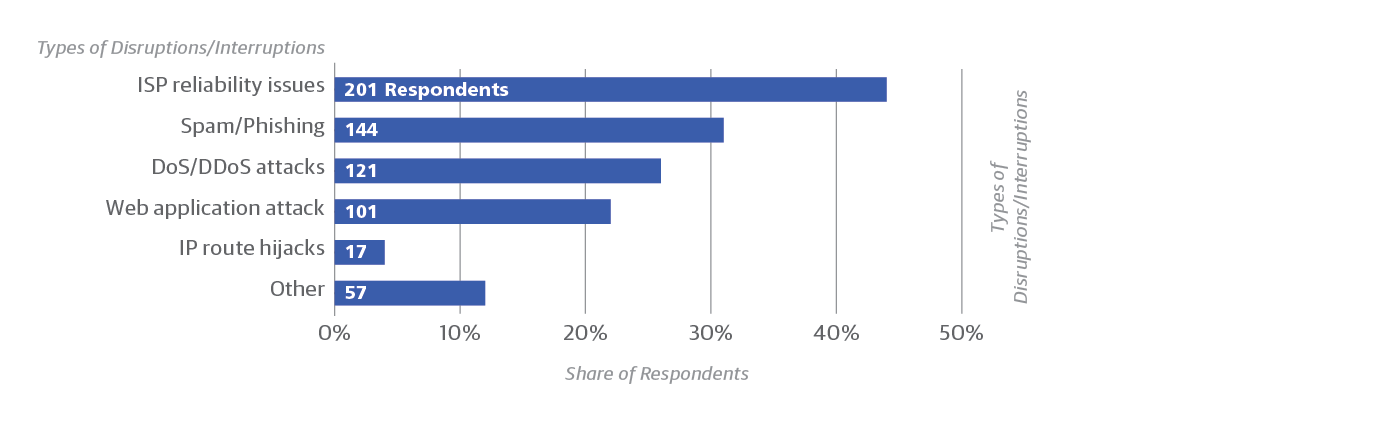
The most surprising result from our survey may be the answer to what respondents said was the leading cause of network disruptions: ISP reliability issues (Figure 4), cited by 44% of respondents. If you add up the various malicious attacks reported, they collectively surpass ISP problems. But given the prevalence of ISP problems, it makes sense that some kind of redundancy is the most popular way to ensure resilience: 39% of respondents use load balancing and 33% use multiple failover sites. Smaller but still significant numbers run a second DNS service, use multiple cloud providers, and use multiple ISPs (Figure 5).
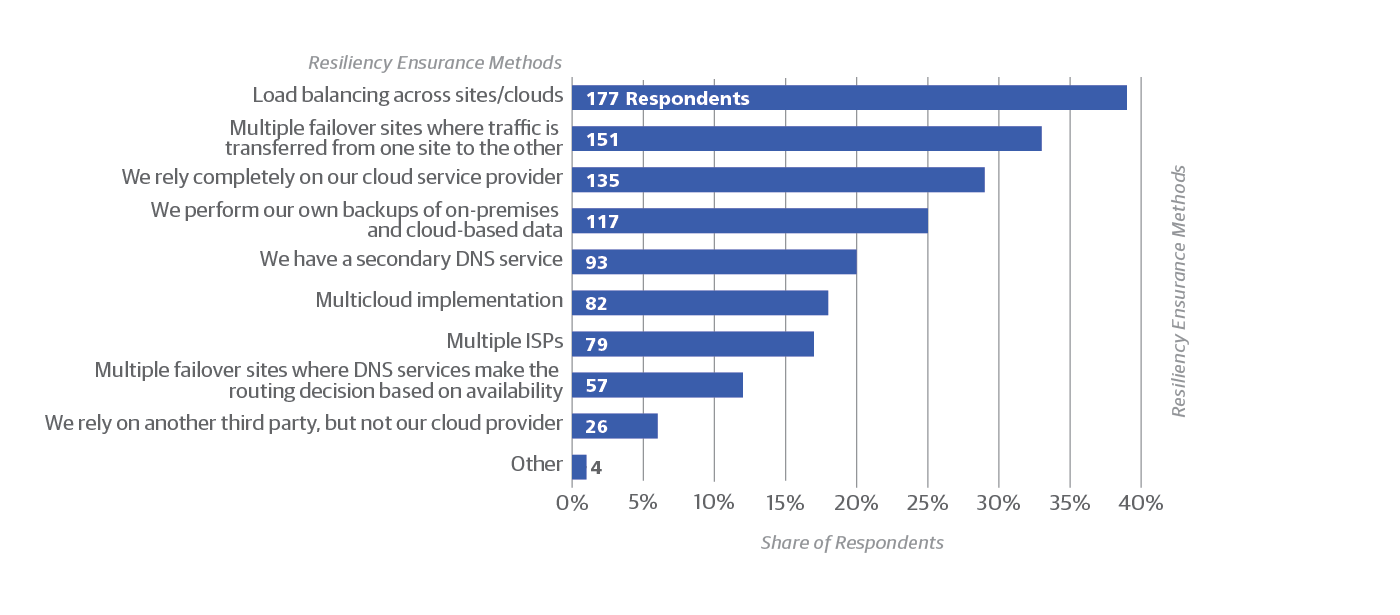
The cloud has not overtaken the landscape
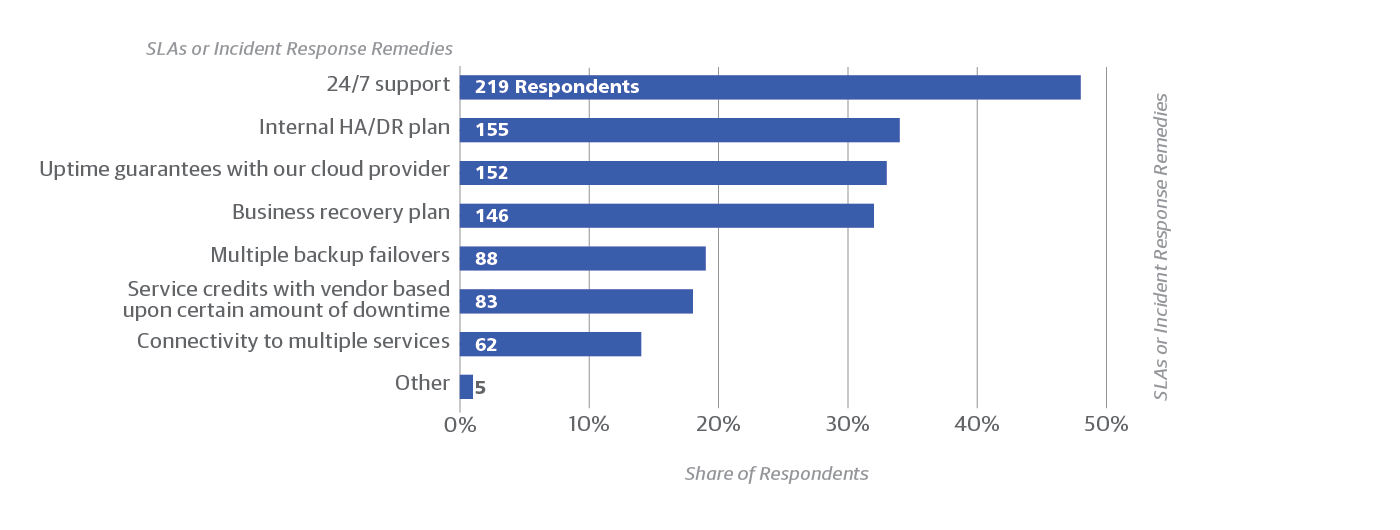
The large percentage of respondents who over-provision resources (19%) suggests that on-premises deployments are still common, even among sites using the cloud as well. Overprovisioning is a common practice in on-premises deployments, and is usually rendered unnecessary in the cloud by autoscaling. And it’s worth noting that 29% of respondents rely entirely on the cloud provider for resilience (Figure 5, above). A variety of SLAs and incident response remedies are in use (Figure 6).
You’re not paranoid
Or you might as well be, because they’re out to get you. Attack vectors suggest that sites taking preemptive steps to mitigate the impact of attacks are justified. For example, among responses indicating the use of DDoS mitigation tools, 51% (85 of 166 respondents, Figure 7) also indicated that their organization actually had a DoS/DDoS attack in the last 12 months. This is nearly twice that of the overall share reporting DoS/DDoS attacks had occurred overall (121 of 459 respondents).

A few other correlations turn up between the disruptions experienced and the measures taken for resilience:
- Using multiple failover sites that share traffic is a popular way to ensure resilience, but it is particularly popular among those who experience DoS attacks or IP route hijacks.
- Companies that experience those attacks (especially DoS attacks) are more likely to have a secondary DNS service. So are firms having problems with ISP reliability.
- Spam and phishing were cited as problems by a large number of sites in general (around one-third) but somewhat more by sites that perform black-holing or sink-holing.
Disruptions don’t happen often, but they have to be expected. Each organization was likely to experience just one or two disruptions, but as we explained at the beginning, even a single disruption can be a serious concern (just remember the famous Netflix Christmas outage). A lucky or highly disciplined 20% of respondents reported no disruptions or interruptions during the past year.
Neither organizational size nor industry type made a difference in the problems faced by organizations or the responses they implemented. Similarly, no particular worry dominated responses to the survey. Everything was considered important by a substantial fraction of respondents, although none of them were cited by a majority. And all cloud users employed similar techniques to ensure resilience, regardless of their purpose for using the cloud.
Solutions are at hand—but not in use
It is interesting how many organizations fail to use certain preemptive tools that one might think are universal (Figure 8). For instance, among respondents who oversee the use of cloud services at their organization, more than one-third (37%) said they don’t use firewalls. Even more (42%) fail to use health monitoring. Similarly, DDoS mitigation is used by only 36% of respondents using the cloud. Perhaps the others don’t expect DDoS mitigation to be effective, or anticipate that their services can just wait out a DDoS attack. Or perhaps these respondents rely on the cloud provider to run these services, so some of the services might, in fact, be in place despite the responses we received.
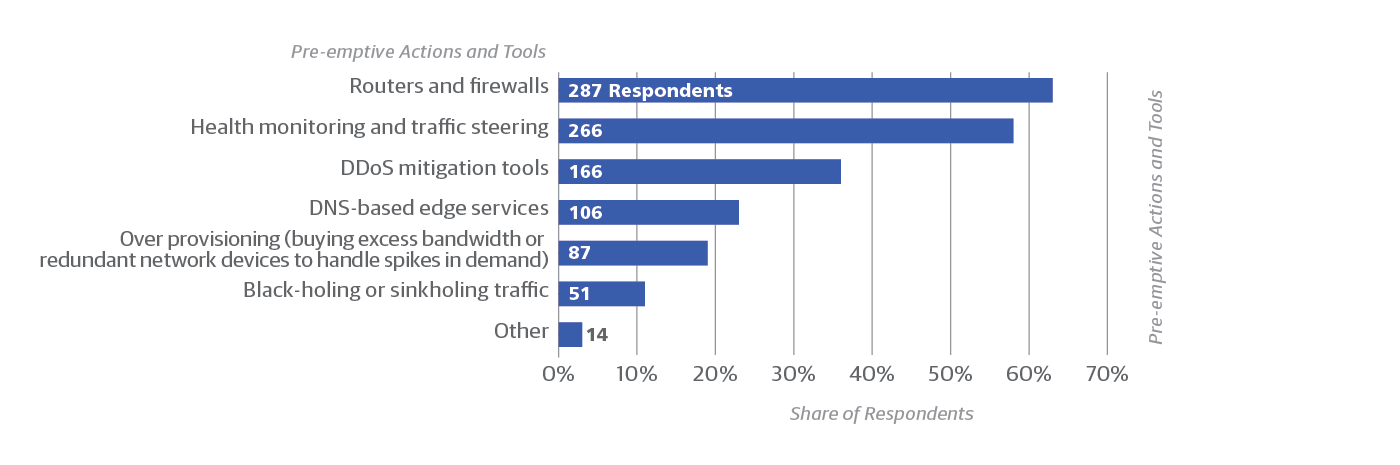
This section wraps up our findings about outages, attacks, and technologies. Now we turn to the human element of network monitoring. Are there enough educated staff in this field? How are companies educating their staffs, and how does that affect responses to network disruptions?
Good network operators are at a premium
In 2015, network engineering was listed as one of the best career choices in computing. The article making that claim does not explain its criteria, but it apparently counts just the demand for such positions: 105,000 openings that year. Job conditions are a different matter, and our survey responses suggest that not all is well in the working conditions for network operators.
Respondents to the survey tend to move around. Fewer than 35% had been in their current jobs for more than five years. We didn’t ask how long they had been working in total as network operators. But the greatest single concern respondents expressed about their staff was lack of experience (53%) and insufficient training (46%), both of which suggest that a lot of operators are fairly new to the field. Most organizations are willing to train new operators, either through formal training programs (38%) or informal mentoring (38%).
A substantial number of organizations (29%) hire only experienced people, a luxury that may elevate salaries throughout the field. One can expect people in this field to be highly employable, and therefore to move around a lot in search of more money or better work environments.
In this regard, it’s significant that burnout was a major concern among respondents (46%), along with turnover (37%). This should not be surprising because in most institutions, network operations involve constant pressure. And no one likes those 3 a.m. wake-up calls.
Overall, respondents were concerned less about losing employees (turnover) and more about ensuring current employees remained satisfied in their jobs (i.e., that gaps in experience or training are addressed and that employees don’t burn out).
Sites handle outages and attacks differently
Many common forms of analysis and recovery are performed after an attack (Figure 9). The methods organizations use to respond to attacks or to ensure resilience are sometimes correlated with their efforts at skills development, and perhaps even influence staff burnout.
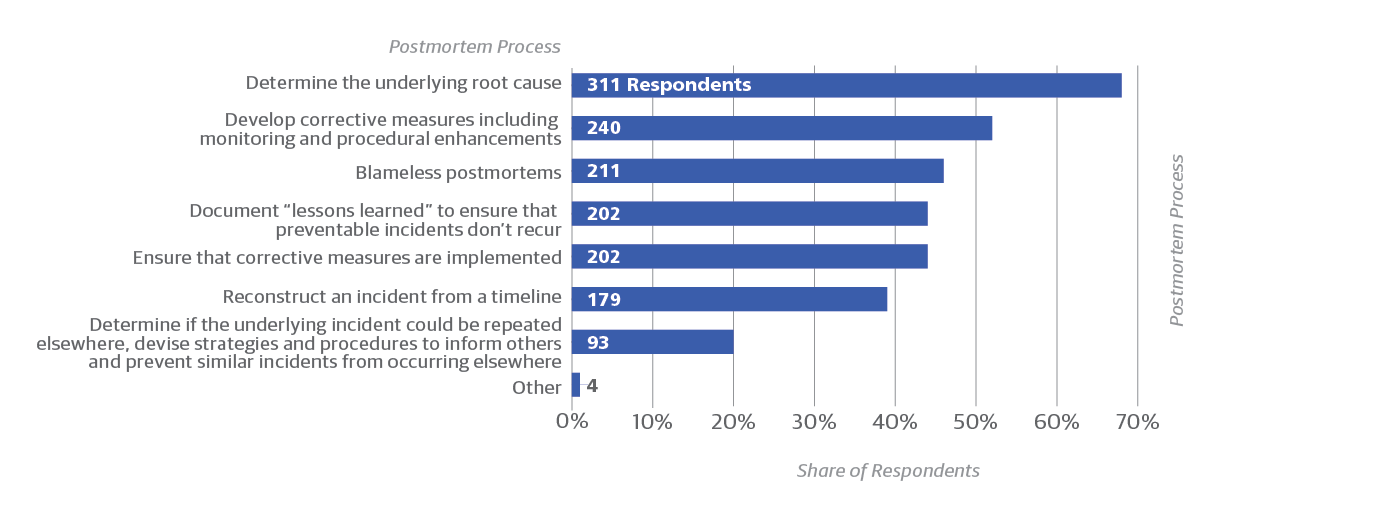
Some examples of different responses include:
- Among respondents who indicate that they rely completely on cloud service providers (135 respondents), only a little more than one-third indicated that their organization protects against burnout through either advanced training or career advancement opportunities (35% and 36%, respectively). These percentages are considerably lower than the use of training or other tools to prevent burnout by respondents who employ load balancing across sites or the use of multiple failover sites.
- The approach used for training network ops teams (Figure 10) may influence how incidents are handled in postmortems. For example, just 37% of those who only hire experienced people indicated they document “lessons learned” to ensure preventable incidents don’t occur.
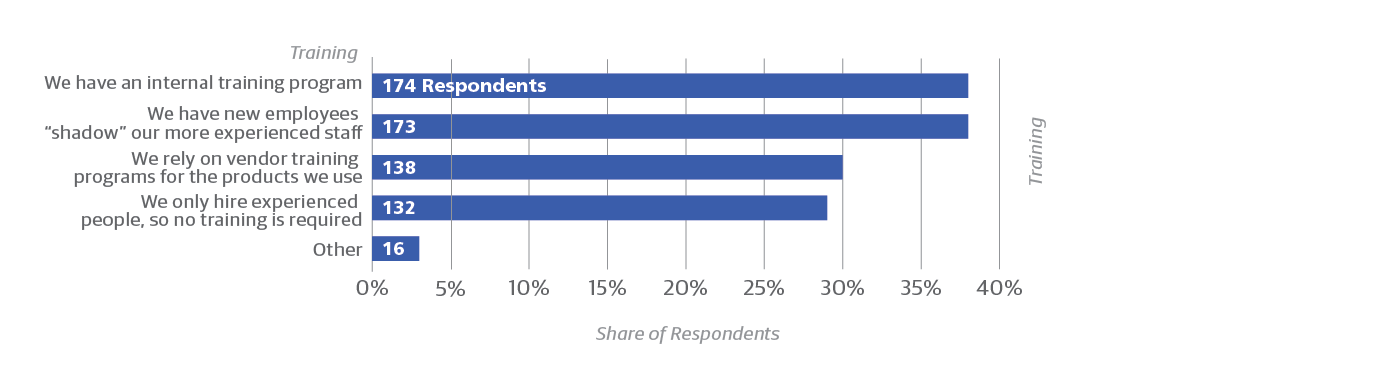
- Among those who train their staff through internal programs, reliance on vendors, or employee “shadowing,” around half also reported their postmortems documented lessons learned (48%, 52%, and 58%, respectively).
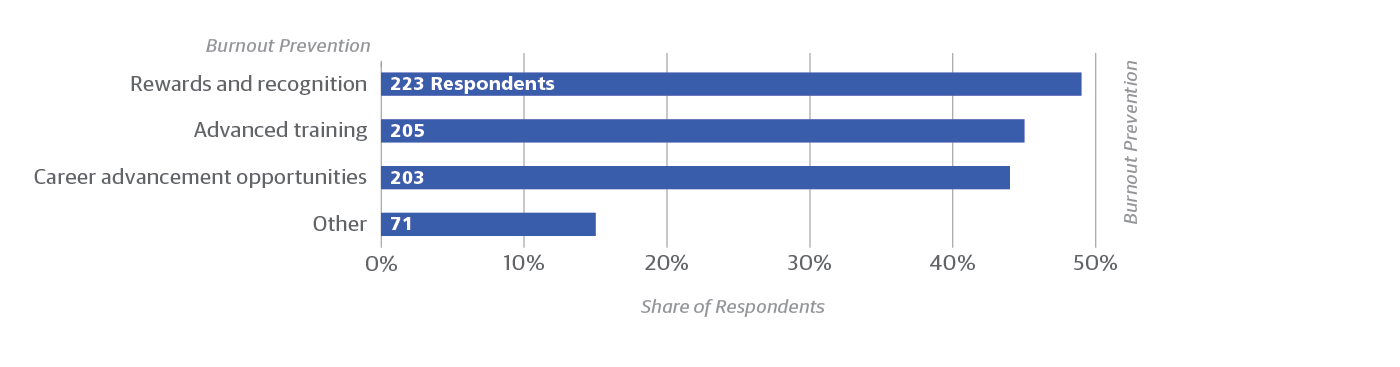
- Rewards and recognition are the slightly preferred approach to addressing burnout (Figure 11). Notably, though, this approach does not appear to be considered enough for the majority. Of the 223 respondents who selected rewards and recognition (49% of total respondents), nearly two-thirds (65%, 145 respondents) also selected career advancement opportunities or advanced training to protect operations staff against burnout.
Automation: Is there a better way?
The survey did not ask what forms of automation organizations use, but these are probably lacking. Despite the current enthusiasm for DevOps in development, the 2017 Puppet “State of DevOps Report” found that about 40% of survey respondents still do manual configuration management and deployment.
Thus, we can surmise that a large number of network operators have to suffer through repetitive recovery tasks under high pressure, along with being tied to their pagers. Even among the 60% of organizations that do some automation, it is probably incomplete. As tools become more widespread and better understood—and especially as cloud providers make them simple to deploy—we can look forward to less burnout and turnover. In summary, given how widespread burnout appears to be, organizations should perhaps make automation a priority.
Conclusion
Overall, our survey suggests that organizations are surviving network outages or reliability problems pretty well. Concerns about resilience, and the measures taken to address them, are fairly consistent across industries, organizational size, and the attacks or failures encountered.
ISP failures are a major concern, vying in importance with malicious attacks. In response to both concerns, sites employ many forms of redundancy, ranging from over-provisioning resources to using multiple cloud providers and DNS services. On the other hand, many respondents are happy sticking their services in the cloud and allowing the cloud provider to deal with reliability.
Warning flags crop up in the treatment of network operators and their job satisfaction. The pressure to hire and retain operators can be addressed by more training or by reducing the need for such staff through automation. Measures that seem to be put in place for the benefit of junior engineers, such as documenting incidents, may end up being healthy for the organization as a whole.
Perhaps this article will encourage more managers of network operations to take a closer look and expand their use of tools for preventing and mitigating problems. Currently, according to the results of the survey, such practices are not as widespread as one would think. We also suggest that operators put more effort and be more consistent in their postmortem handling of incidents, invest in training, and improve the jobs through modern automated practices to prevent burnout.
This post is a collaboration between O’Reilly and Oracle Dyn. See our statement of editorial independence.