

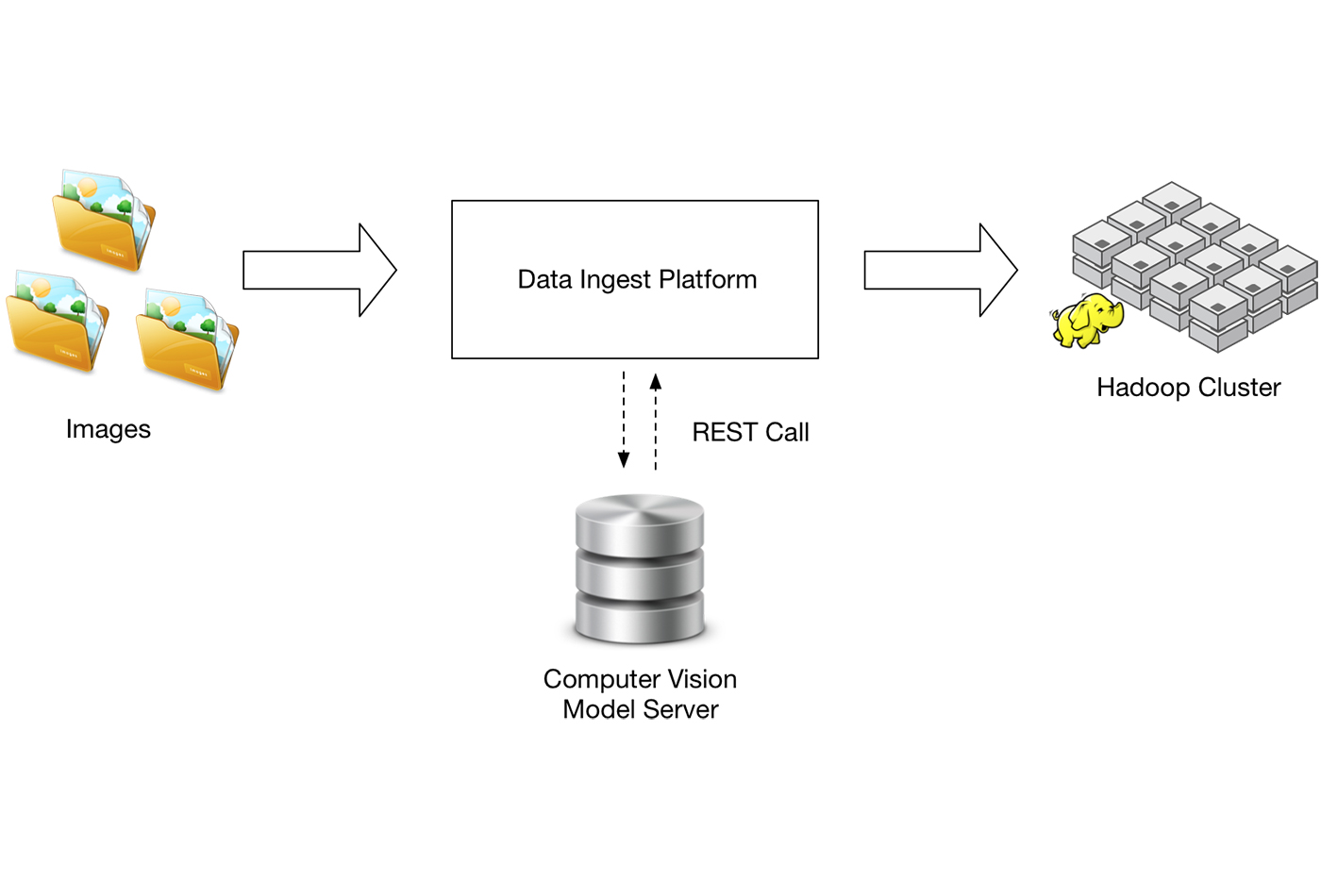
 Building out a production-grade real-time image classification system (source: Josh Patterson and Kirit Basu, used with permission)
Building out a production-grade real-time image classification system (source: Josh Patterson and Kirit Basu, used with permission) Integrating neural networks and convolutional neural networks into a production-ready enterprise application can be a challenge in itself, separate from the modelling task. In addition to the infrastructure aspects mentioned in our higher-level post “Solving real-world business problems with computer vision,” we need to consider a number of tasks:
- What kind of convolutional architecture do we want to use for this computer vision problem?
- Where will we train the model?
- What data does the model need and what type of security constraints do we have on the training data?
- Where does the model live once it’s trained so the applications can query the model for predictions?
- How do we account for new versions of the model over time and ensure we have the right model providing predictions to the application?
- How do we account for the above items when we have 20 different machine learning models serving multiple applications?
Deep learning has different major architectures of networks, such as convolutional neural networks for image data and recurrent neural networks for sequence data. Inside these major architectures, we find many variants in how the layers and artificial neurons are composed. Some popular convolutional neural network architectures (which are summarized here) include:
- LeNet (developed by Yann Lecun)
- One of the earliest successful architectures of CNNs
- AlexNet (developed by Krizhevsky, Sutskever, Hinton, 2012)
- Helped popularize CNNs in computer vision
- Won ILSVRC 2012
- ZF Net (developed by Zeiler, Fergus)
- Won ILSVRC 2013
- GoogLeNet (developed by Szegedy, Google, also called the “Inception” network)
- Won ILSVRC 2014
- VGGNet
- Runner up: ILSVRC 2014
- ResNet
- Won ILSVRC 2015
A common practice for a new computer vision project is to find a network from the above list and try it as a starting place for layer architecture with the specific image data set. Another angle is to use what is called “transfer learning” to build up a base set of image features and then continue training the network architecture on the domain specific data set. Transfer learning can be helpful when we don’t have a lot of training images for our domain, so we leverage data from another relevant domain to help build up our model.
Often, early versions of model integration involve simply copying the model file to the local machine where the application is running and letting the code load it into memory directly. This may work for a one-off application for the desktop, but most F500 IT departments may take pause at this setup. Most enterprise IT folk are trained to consider the above constraints in terms of thinking about application and model deployment from a manageability standpoint, and nice ideas have died a quick enterprise death because they were not “deployable.”
If we had 20 different machine learning workflows, each producing a new model once a month over the course of a year, we would have (12 x 20) 240 different versions of model files lying around on hard drives, and this quickly becomes a file management problem. How do we track each workflow’s group of files and keep the latest one as the production integrated version? What if we wanted to roll back to a previous version because there was an issue discovered with the training data in the latest build of a model? How do we share one or many of the models across multiple applications while making sure each application was using the “right” version of each model? While these issues are present from the beginning of modelling, they progressively become tougher to deal with as we bring more models online in an enterprise. The market is predicting that every enterprise will bring many models online soon, so this is a real problem for nearly every company that manages data in the world.
The nice thing here is that we’ve seen this happen before, back in the ‘80s and ‘90s when data tended to lie around on hard drives in flat files and (these files) were managed much like machine learning model files today. Over time, these files got organized into RDBMS tables and centralized in a server, and this is the pattern we’re seeing at Skymind today with many organizations. They need a central model server to manage models (similar to a RDBMS table) and allow access to query the model via a REST call—somewhat similar to a SQL query over a JDBC interface today.
Models are becoming the new RDBMS table, in effect, and model servers are the new database servers.
So, to summarize our ideas on integration, we need to:
- Select a CNN architecture that models data similar to the data we want to model so we know it is adept at modeling those types of features.
- Have a system that allows us to build and deploy the model under the constraints of data storage and security.
- Manage deployment and access to the right version of each model across potentially many different applications.
Let’s now review the ideas presented above by pulling the full architecture together to classify images streaming into an enterprise.
Putting it all together
To build out a production-grade real-time image classification system, we need something like the diagram in Figure 1 illustrates.
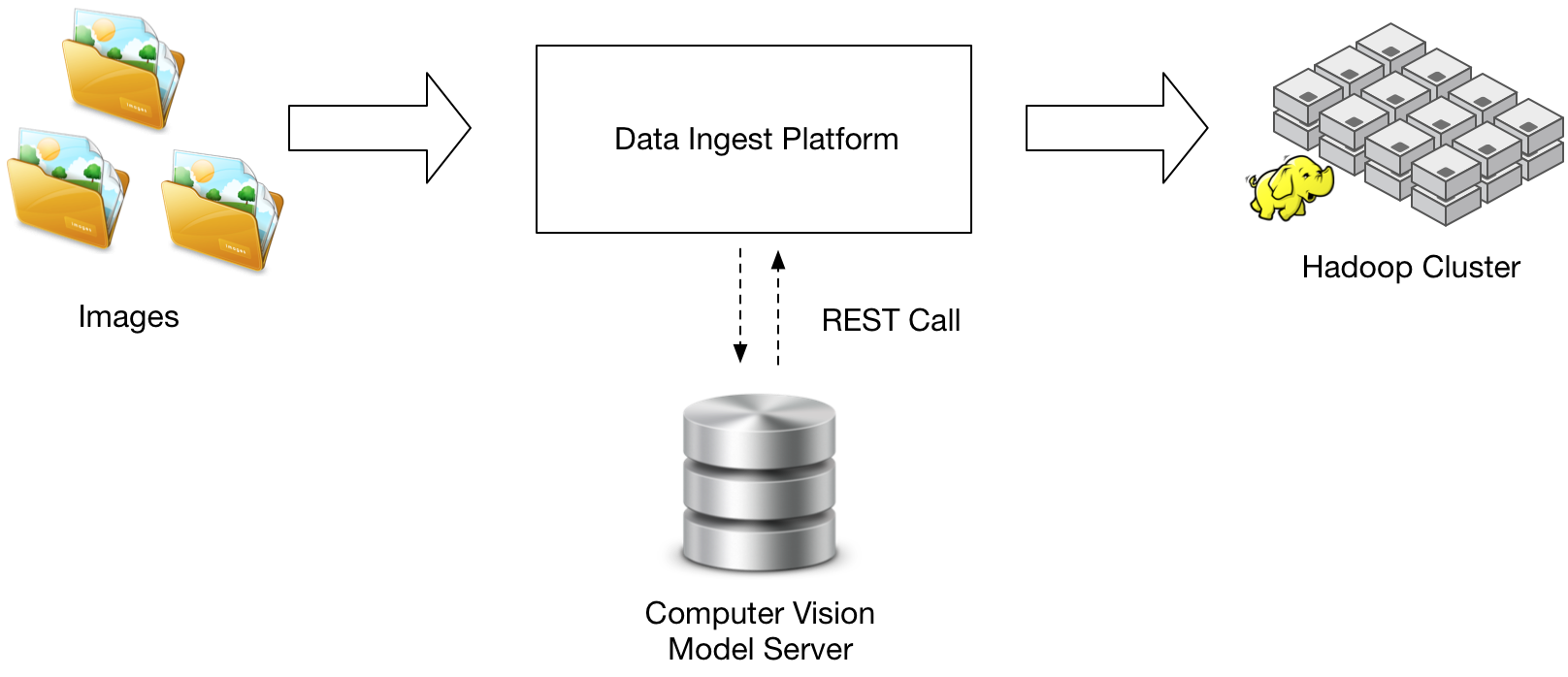
Typically, we have multiple sources of data in the organization that we’re ingesting into a storage system, such as an Apache Hadoop cluster (e.g., HDFS for storage). In a streaming computer vision system, we need:
- a way to get the images + associated metadata from the sources into some sort of data ingest system
- a data ingest system
- a model server to serve predictions from the convolutional model
- a place to store the images and the classifications of the images
Of course, real-world applications have many other moving parts. In addition to classifying objects in the image, you may have to look up other metadata from APIs or databases. You may have to deal with unexpected conditions such as bad files or missing data. Or you may have to not only write image files to the terminal destination, but also update databases or search indexes with the image metadata and inform users of the newly ingested files. And, of course, you have to do this at scale, hopefully without having to write any code.
In the diagram below, we show a more specific system based on technology products from both Skymind and StreamSets (disclosure: the authors of this post are employed at each of the companies, Patterson at Skymind and Basu at StreamSets).
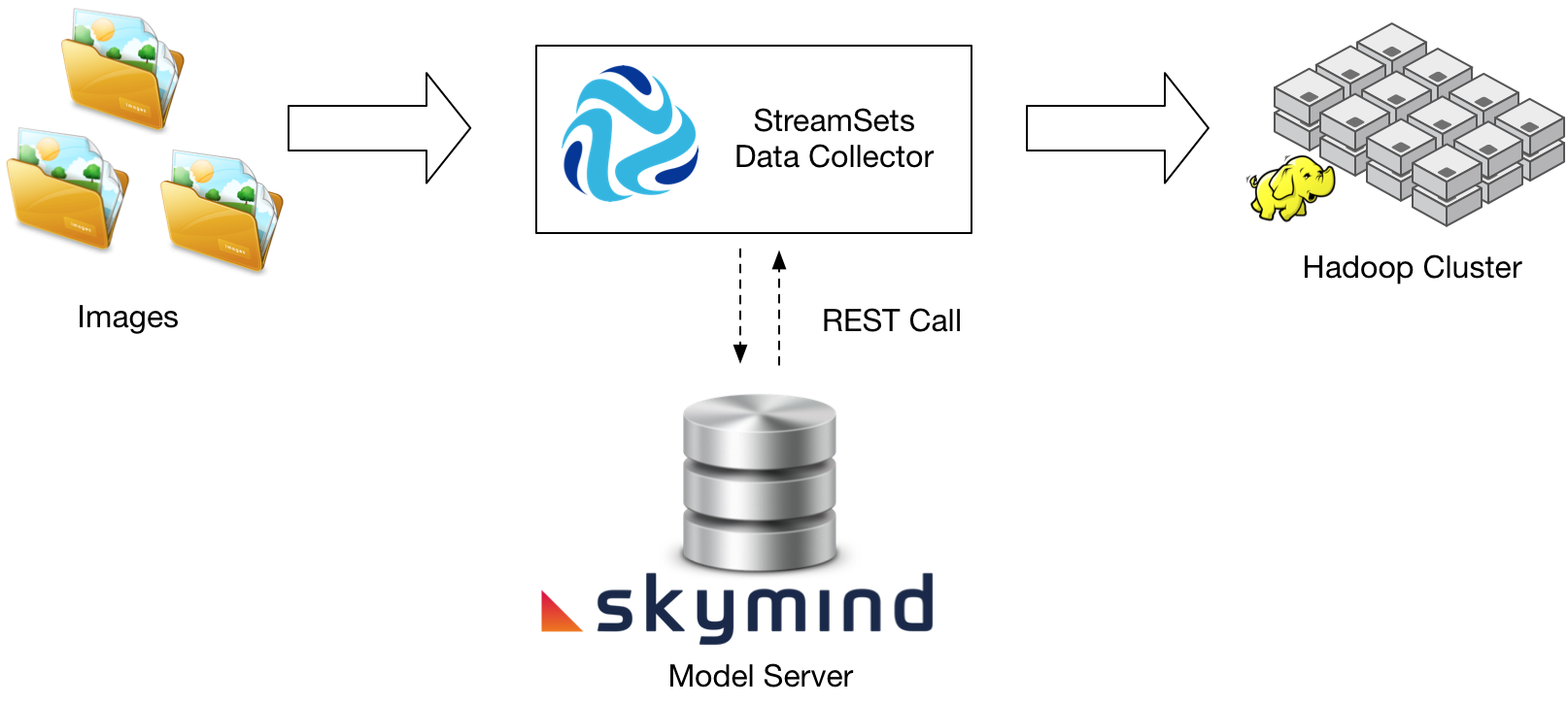
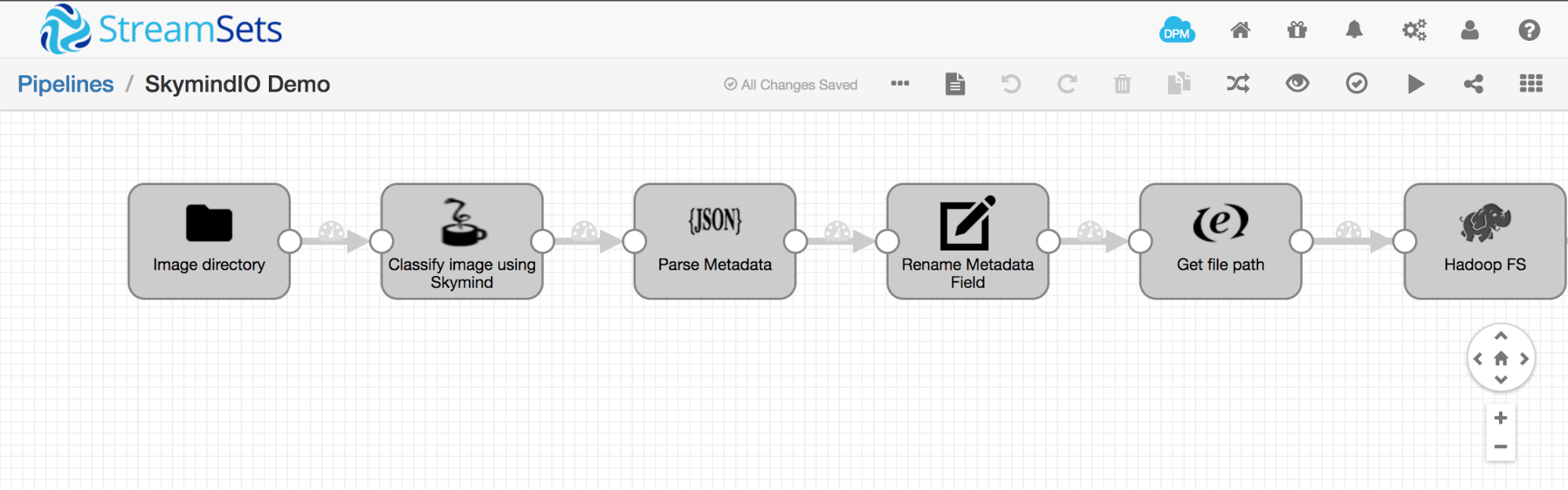
Figure 3 is an example of a simple StreamSets pipeline that reads images from a file directory, calls the Skymind model server to recognize objects in the image, and writes the image and associated metadata to HDFS.
In this article we’ve discussed how to make streaming image recognition a reality in an enterprise today. The combination of streaming technology and model prediction serving can be applied to build many types of applications, such as fraud detection and anomaly detection systems. To hear more about applied machine learning in the context of streaming data infrastructure, attend our session Real-time image classification: Using convolutional neural networks on real-time streaming data at the Strata Data Conference in New York City, Sept. 25-28, 2017.
For more information on the technologies mentioned in this article, email Josh (josh@skymind.io) or Kirit (kirit@streamsets.com).