Introduction to designing for scalability with Erlang/OTP
Erlang/OTP is unique among programming languages and frameworks in the breadth, depth, and consistency of the features it provides for scalable, fault-tolerant systems with requirements for high availability.
 Pressure (source: Fernando50 via Pixabay)
Pressure (source: Fernando50 via Pixabay)
Introduction
You need to implement a fault-tolerant, scalable, soft real-time
system with requirements for high availability. It has to be event-driven
and react to external stimuli, load, and failure. It must always be
responsive. You have heard, rightfully so, of many success stories telling
you Erlang is the right tool for the job. And indeed it is—but while Erlang
is a powerful programming language, it’s not enough on its own to group
these features all together and build complex reactive systems. To get the
job done correctly, quickly, and efficiently, you also need middleware,
reusable libraries, tools, design principles, and a programming model that
tells you how to architect and distribute your system.
Our goal with this book is to explore multiple facets of availability
and scalability, as well as related topics such as concurrency,
distribution, and fault tolerance, in the context of the Erlang programming
language and its OTP framework. Erlang/OTP was created when the team at the Ericsson Computer Science Laboratory (CS Lab) set
out to investigate how they could efficiently develop the next generation of
telecommunications systems in an industry where time to market was becoming
critical. This was before the Web, before tablets and smartphones, massively
multiuser online gaming, messaging, and the Internet of Things.

Learn faster. Dig deeper. See farther.
At that time, the only systems that required the levels of scalability
and fault tolerance we take for granted today were boring phone switches.
They had to handle massive traffic spikes on New Year’s Eve, fulfill
regulatory obligations for the availability of calls to emergency services,
and avoid the painfully expensive contractual penalties forced on
infrastructure suppliers whose equipment caused outages. In layman’s terms,
if you picked up the phone and did not hear the dial tone on the other end,
you could be sure of two things: top-level management would get into serious
trouble and the outage would make the front page news in the papers. No
matter what, those switches were not allowed to fail. Even when components
and infrastructure around them were failing, requests had to be handled.
Today, regulators and fines have been replaced with impatient users with no
loyalty who will not hesitate to switch suppliers, and front-page newspaper
articles have been replaced by mass hysteria on social media. But the core
problems of availability and scalability remain.
As a result, telecoms switches and modern systems alike have to react
to failure as much as they have to react to load and internal events. So
while the folks at the Ericsson Computer Science Lab did not set out to
invent a programming language, the solution to the problem they were out to
solve happened to be one. It’s a great example of inventing a language and
programming model that facilitates the task of solving a specific,
well-defined problem.
Defining the Problem
As we show throughout this book, Erlang/OTP is unique among programming languages and
frameworks in the breadth, depth, and consistency of the features it
provides for scalable, fault-tolerant systems with requirements for high
availability. Designing, implementing, operating, and maintaining these
systems is challenging. Teams that succeed in building and running them do
so by continuously iterating through those four phases, constantly using
feedback from production metrics and monitoring to help find areas they
can improve not only in their code, but also in their development and
operating processes. Successful teams also learn how to improve
scalability through other means, such as testing, experimentation, and
benchmarking, and they keep up on research and development relevant to
their system characteristics. Nontechnical issues such as organizational
values and culture can also play a significant part in determining whether
teams can meet or exceed their system requirements.
We used the terms distributed,
fault-tolerant, scalable,
soft real-time, and highly
available to describe the systems we plan on building with OTP.
But what do these words actually mean?
Scalable refers to how well a computing system can adapt to changes in load or
available resources. Scalable websites, for example, are able to smoothly
handle traffic spikes without dropping any client requests, even when
hardware fails. A scalable chat system might be able to accommodate
thousands of new users per day without disruption of the service it
provides to its current users.
Distributed refers to how systems are clustered together and interact with each
other. Clusters can be architected to scale horizontally by adding
commodity (or regular) hardware, or on a single machine, where additional
instances of standalone nodes are deployed to better utilize the available
cores. Single machines can also be virtualized, so that instances of an
operating system run on other operating systems or share the bare-metal
resources. Adding more processing power to a database cluster could enable
it to scale in terms of the amount of data it can store or how many
requests per second it can handle. Scaling downward is often equally as
important; for example, a web application built on cloud services might
want to deploy extra capacity at peak times and release unused computing
instances as soon as usage drops.
Systems that are fault tolerant
continue to operate predictably when things in their environment are
failing. Fault tolerance has to be designed into a system from the start;
don’t even consider adding it as an afterthought. What if there is a bug
in your code or your state gets corrupted? Or what if you experience a
network outage or hardware failure? If a user sending a message causes a
process to crash, the user is notified of whether the message was
delivered or not and can be assured that the notification received is
correct.
By soft real-time, we mean the predictability of response and latency, handling a
constant throughput, and guaranteeing a response within an acceptable time
frame. This throughput has to remain constant regardless of traffic spikes
and number of concurrent requests. No matter how many simultaneous
requests are going through the system, throughput must not degrade under
heavy loads. Response time, also known as latency, has to be relative to
the number of simultaneous requests, avoiding large variances in requests
caused by “stop the world” garbage collectors or other sequential
bottlenecks. If your system throughput is a million messages per second
and a million simultaneous requests happen to be processed, it should take
1 second to process and deliver a request to its recipient. But if during
a spike, two million requests are sent, there should be no degradation in
the throughput; not some, but all of the requests should be handled within
2 seconds.
High availability minimizes or
completely eliminates downtime as a result of bugs, outages,
upgrades, or other operational activities. What if a process crashes? What
if the power supply to your data center is cut off? Do you have a
redundant supply or battery backup that gives you enough time to migrate
your cluster and cleanly shut down the affected servers? Or network and
hardware redundancy? Have you dimensioned your system ensuring that, even
after losing part of your cluster, the remaining hardware has enough CPU
capacity to handle peak loads? It does not matter if you lose part of your
infrastructure, if your cloud provider is experiencing an embarrassing
outage, or if you are doing maintenance work; a user sending a chat
message wants to be reassured that it reaches its intended recipient. The
system’s users expect it to just work. This is in contrast to fault tolerance, where the user is told it did
not work, but the system itself is unaffected and continues to run.
Erlang’s ability to do software upgrades during runtime helps. But if you
start thinking of what is involved when dealing with database schema
changes, or upgrades to non–backward-compatible protocols in potentially
distributed environments handling requests during the upgrade, simplicity
fades very quickly. When doing your online banking on weekends or at
night, you want to be sure you will not be met with an embarrassing
“closed for routine maintenance” sign posted on the website.
Erlang indeed facilitates solving many of these problems. But at the
end of the day, it is still just a programming language. For the complex
systems you are going to implement, you need ready-built applications and
libraries you can use out of the box. You also need design principles and
patterns that inform the architecture of your system with an aim to create
distributed, reliable clusters. You need guidelines on how to design your
system, together with tools to implement, deploy, monitor, operate, and
maintain it. In this book we cover libraries and tools that allow you to
isolate failure on a node level, and create and distribute multiple nodes
for scalability and availability.
You need to think hard about your requirements and properties,
making certain you pick the right libraries and design patterns that
ensure the final system behaves the way you want it to and does what you
originally intended. In your quest, you will have to make tradeoffs that
are mutually dependent—tradeoffs on time, resources, and features and
tradeoffs on availability, scalability, and reliability. No ready-made
library can help you if you do not know what you want to get out of your
system. In this book, we guide you through the steps in understanding
these requirements, and walk you through the steps involved in making
design choices and the tradeoffs needed to achieve them.
OTP
OTP is a domain-independent set of frameworks, principles, and
patterns that guide and support the structure, design, implementation, and
deployment of Erlang systems. Using OTP in your projects will help you
avoid accidental complexity: things that are difficult because you picked
inadequate tools. But other problems remain difficult, irrespective of the
programming tools and middleware you choose.
Ericsson realized this very early on. In 1993, alongside the development of the first Erlang
product, Ericsson started a project to tackle tools, middleware, and
design principles. The developers wanted to avoid accidental difficulties
that had already been solved, and instead focus their energy on the hard
problems. The result was BOS, the Basic Operating System. In 1995, BOS merged with
the development of Erlang, bringing everything under one roof to form
Erlang/OTP as we know it today. You might have heard the
dream team that supports Erlang being referred to as the OTP team. This
group was a spinoff of this merge, when Erlang was moved out of a research
organization and a product group was formed to further develop and
maintain it.
Spreading knowledge of OTP can promote Erlang adoption in more
“tried and true” corporate IT environments. Just knowing there is a stable
and mature platform available for application development helps
technologists sell Erlang to management, a crucial step in making its
industrial adoption more widespread. Startups, on the other hand, just get
on with it, with Erlang/OTP allowing them to achieve speed to market and
reduce their development and operations costs.
OTP is said to consist of three building blocks (Figure 1-1) that, when used together, provide a solid
approach to designing and developing systems in the problem domain we’ve
just described. They are Erlang itself, tools and libraries, and a set of
design principles. We’ll look at each in turn.
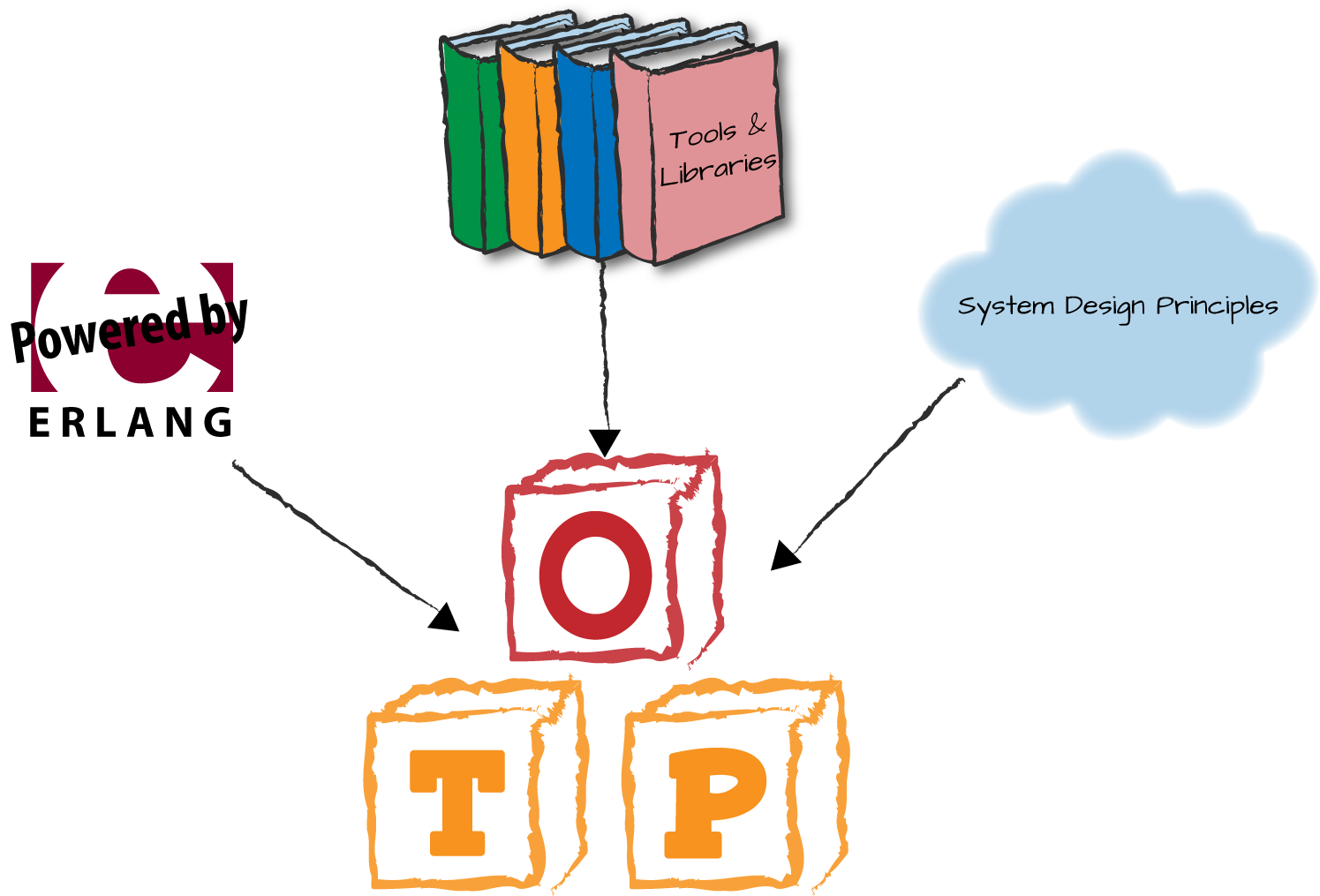
Erlang
The first building block is Erlang itself, which includes the
semantics of the language and its underlying virtual machine. Key
language features such as lightweight processes, lack of shared memory,
and asynchronous message passing will bring you a step closer to your
goal. Just as important are links and monitors between processes, and
dedicated channels for the propagation of the error signals. The
monitors and error reporting allow you to build, with relative ease,
complex supervision hierarchies with built-in fault recovery. Because
message passing and error propagation are asynchronous, the semantics and
logic of a system that was developed to run in a single Erlang node can be easily distributed without having to
change any of the code base.
One significant difference between running on a single node and
running in a distributed environment is the latency with which messages
and errors are delivered. But in soft real-time systems, you have to
consider latency regardless of whether the system is distributed or
under heavy load. So if you have solved one facet of the problem, you
have solved both.
Erlang lets you run all your code on top of a virtual machine
highly optimized for concurrency, with a per-process garbage collector,
yielding predictable and simple system behavior. Other programming
environments do not have this luxury because they need an extra layer to
emulate Erlang’s concurrency model and error semantics. To quote
Joe Armstrong, coinventor of Erlang, “You can emulate the
logic of Erlang, but if it is not running on the Erlang virtual machine,
you cannot emulate the semantics.” The only languages that today get
away with this are built on the BEAM emulator, the prevailing Erlang virtual machine.
There is a whole ecosystem of them, with the Elixir and Lisp Flavored
Erlang languages being the ones gaining most traction at the time of
writing. What we write in this book about Erlang also applies to
them.
Tools and Libraries
The second building block, which came about before open source became
the widespread norm for software projects, includes applications that
ship as part of the standard Erlang/OTP distribution. You can view each
application as a way of packaging resources in OTP, where applications
may have dependencies on other applications. The applications include
tools, libraries, interfaces toward other languages and programming
environments, databases and database drivers, standard components, and
protocol stacks. The OTP documentation does a fine job of separating
them into the following subsets:
-
The basic applications include the following:
They provide the tools and basic building blocks needed to
architect, create, start, and upgrade your system. We cover the
basic applications in detail throughout this book. Together with
the compiler, these are the minimal subset of applications
necessary in any system written in Erlang/OTP to do anything
meaningful. -
The database applications include mnesia,
Erlang’s distributed database, and odbc, an interface used to communicate with relational SQL
databases. Mnesia is a popular choice because it is fast, runs and
stores its data in the same memory space as your applications, and
is easy to use, as it is accessed through an Erlang API. -
The operations and maintenance applications include os_mon,
an application that allows you to monitor the underlying operating
system; snmp, a Simple Network Management Protocol agent and client;
and otp_mibs,
management information bases that allow you to manage Erlang
systems using SNMP. -
The collection of interface and communication applications
provide protocol stacks and interfaces to work with other
programming languages, including an ASN.1 (asn1)
compiler and runtime support, direct hooks into C (ei and erl_interface) and Java (jinterface) programs, along with an XML parser (xmerl). There are security applications
for SSL/TLS, SSH, cryptography, and public key infrastructure.
Graphics packages include a port of wxWidgets (wx),
together with an easy-to-use interface. The eldap application provides a client interface toward the Lightweight
Directory Access Protocol (LDAP). And for telecom aficionados, there is a Diameter stack (as defined in RFC 6733), used for
policy control and authorization, alongside authentication and
accounting. Dig even deeper and you will find the Megaco stack. Megaco/H.248 is a protocol for
controlling elements of a physically decomposed multimedia
gateway, separating the media conversion from the call control. If
you have ever used a smartphone, you have very likely indirectly
taken the Erlang diameter and
megaco applications for a
spin. -
The collection of tools applications facilitate the
development, deployment, and management of your Erlang system. We
cover only the most relevant ones in this book, but outline them
all here so you are aware of their existence:-
The debugger is a
graphical tool that allows you to step through your code
while influencing the state of the functions. -
The observer
integrates the application monitor and the process
manager, alongside basic tools to monitor your Erlang
systems as they are being developed and in
production. -
The dialyzer is a
static analysis tool that finds type discrepancies,
dead code, and other issues. -
The event tracer (et) uses ports to collect trace events in distributed
environments, and percept
allows you to locate bottlenecks in your system by tracing
and visualizing concurrency-related activities. -
Erlang Syntax Tools (syntax_tools) contains modules for handling Erlang syntax trees in a
way that is compatible with other language-related tools. It
also includes a module merger allowing you to merge Erlang
modules, together with a renamer, solving the issue of
clashes in a nonhierarchical module space. -
The parsetools
application contains the parse generator (yecc) and a
lexical analyzer generator for Erlang
(leex). -
Reltool is a
release management tool that provides a graphical
front end together with back-end hooks that can be used by
more generic build systems. -
Runtime_tools is a
collection of utilities including DTrace and SystemTap probes,
and dbg, a user-friendly
wrapper around the trace built-in functions (BIFs). -
Finally, the tools
application is a collection of profilers, code coverage
tools, and module cross-reference analysis tools, as well as
the Erlang mode for the emacs editor.
-
-
The test applications provide tools for unit testing (eunit), system testing, and black-box
testing. The Test Server (packaged in the test_server application) is a framework
that can be used as the engine of a higher-level test tool
application. Chances are that you will not be using it, because
OTP provides one of these higher-level test tools in the
form of common_test, an application suited for
black-box testing. Common_test
supports automated execution of Erlang-based test cases toward
most target systems irrespective of programming language. -
We need to mention the Object Request Brokers (ORBs) and interface
definition language (IDL) applications for nostalgic reasons,
reminding one of the coauthors of his past sins. They include a
broker called orber, an IDL compiler called ic, and a
few other CORBA Common Object Services no longer used by
anyone.
We cover and refer to some of these applications and
tools in this book. Some of the tools we do not cover are described in
Erlang Programming (O’Reilly), and
those that aren’t are covered by the set of reference manual pages and
the user’s guide that comes as part of the standard Erlang/OTP
documentation.
These applications are not the full extent of tool support for
Erlang; they are enhanced by thousands of other applications implemented
and supported by the community and available as open source. We cover
some of the prevailing applications in the latter half of the book,
where we focus on distributed architectures, availability, scalability,
and monitoring. They include the Riak
Core and Scalable Distributed
(SD) Erlang frameworks; load regulation applications such as jobs and safetyvalve; and monitoring and logging applications such as elarm, folsom, exometer, and lager. Once you’ve read this book and before
starting your project, review the standard and open source Erlang/OTP
reference manuals and user’s guides, because you never know when they
will come in handy.
System Design Principles
The third building block of OTP consists of a set of abstract principles,
design rules, and generic behaviors. The abstract principles describe
the software architecture of an Erlang system, using processes in the
form of generic behaviors as basic ingredients. Design rules keep the
tools you use compatible with the system you are developing. Using this
approach provides a standard way of solving problems, making code easier
to understand and maintain, as well as providing a common language and
vocabulary among the teams.
OTP generic behaviors can be seen as formalizations of concurrent
design patterns. Behaviors are packaged into library modules containing
generic code that solves a common problem. They have built-in support
for debugging, software upgrade, generic error handling, and built-in
functionality for upgrades.
Behaviors can be worker processes, which
do all of the hard work, and supervisor
processes, whose only tasks are to start, stop, and monitor
workers or other supervisors. Because supervisors can monitor other
supervisors, the functionality within an application can be chained so
that it can be more easily developed in a modular fashion. The processes
monitored by a supervisor are called its children.
OTP provides predefined libraries for workers and supervisors,
allowing you to focus on the business logic of the system. We structure
processes into hierarchical supervision trees,
yielding fault-tolerant structures that isolate failure and facilitate
recovery. OTP allows you to package a supervision tree into an
application, as seen in Figure 1-2, where circles
with double rings are supervisors and the other processes are
workers.
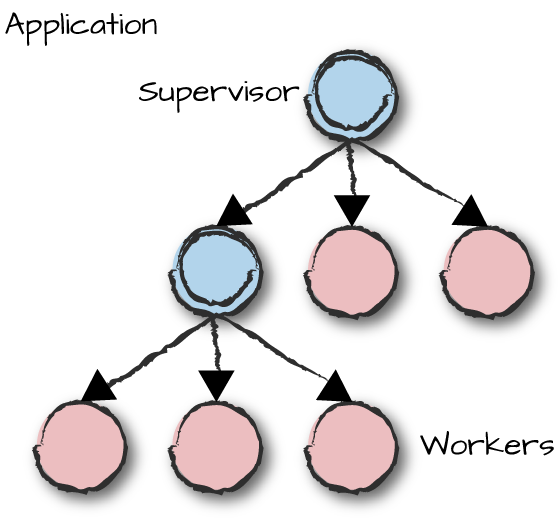
Generic behaviors that come as part of the OTP middleware include:
-
Generic finite state machines, allowing you to implement
FSMs -
Event handlers and managers, allowing you to generically
deal with event streams -
Supervisors, monitoring other worker and supervision processes
-
Applications, allowing you to package resources, including
supervision trees
We cover them all in detail in this book, as well as explaining
how to implement your own. We use behaviors to create supervision trees,
which are packaged into applications. We then group applications
together to form a release. A release
describes what runs in a node.
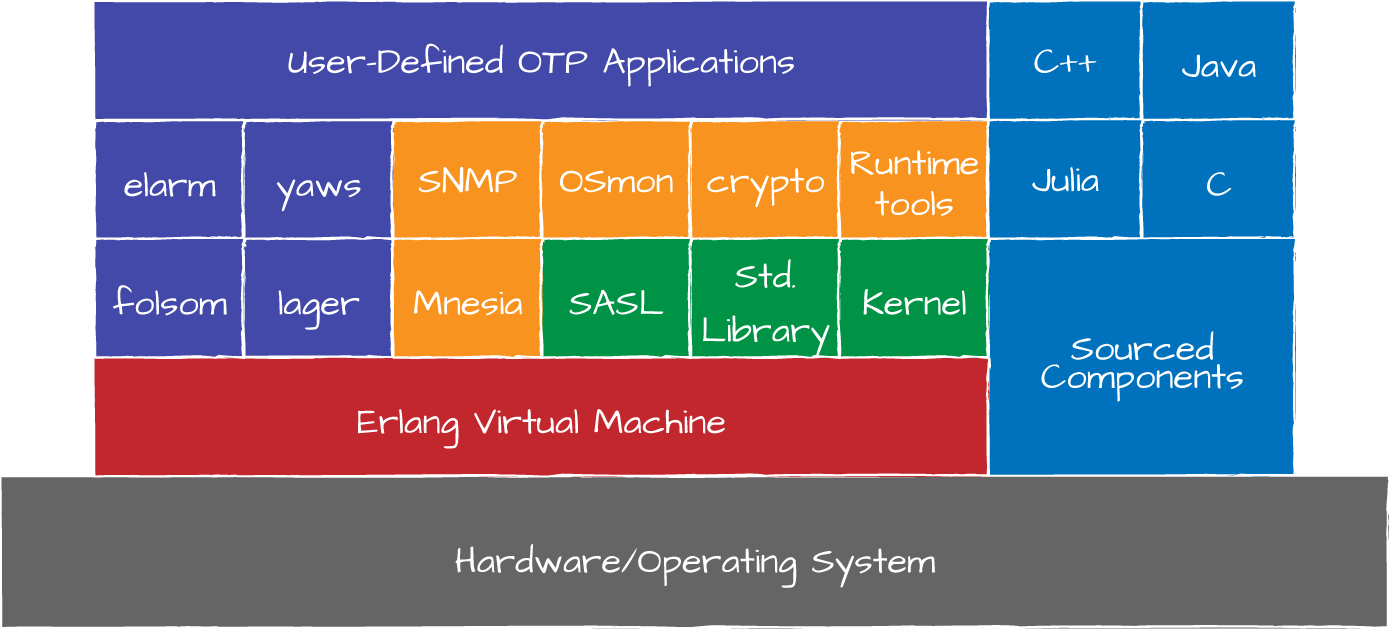
Erlang Nodes
An Erlang node consists of several loosely coupled applications, which
might be comprised of some of the applications described in Tools and Libraries combined with other third-party
applications and applications you write specifically for the system you
are trying to implement. These applications could be independent of each
other or rely on the services and APIs of other applications. Figure 1-3 illustrates a typical release of an Erlang node with
the virtual machine (VM) dependent on the hardware and operating system,
and Erlang applications running on top of the VM interfacing with
non-Erlang components that are OS and hardware dependent.
Group together a cluster of Erlang nodes—potentially pairing them
up with nodes written in other programming languages—and you have a
distributed system. You can now scale your system by adding nodes until
you hit certain physical limits. These may be dictated by how you shared
your data, by hardware or network constraints, or by external
dependencies that act as bottlenecks.
Distribution, Infrastructure, and Multicore
Fault tolerance—one of Erlang’s fundamental requirements from its telecom roots—has
distribution as its mainspring. Without distribution, the reliability and
availability of an application running on just a single host would depend
heavily on the reliability of the hardware and software comprising that
host. Any problems with the host’s CPU, memory, persistent storage,
peripherals, power supply, or backplane could easily take down the entire
machine and the application along with it. Similarly, problems in the
host’s operating system or support libraries could bring down the
application or otherwise render it unavailable. Achieving fault tolerance
requires multiple computers with some degree of coordination between them,
and distribution provides the avenue for that coordination.
For decades, the computing industry has explored how programming
languages can support distribution. Designing general-purpose languages is
difficult enough; designing them to support distribution significantly
adds to that difficulty. Because of this, a common approach is to add
distribution support to nondistributed programming languages through
optional libraries. This approach has the benefit of allowing distribution
support to evolve separately from the language itself, but it often
suffers from an impedance mismatch with the language, feeling to
developers as if it were “bolted on.” Since most languages use function
calls as the primary means of transferring control and data from one part
of an application to another, add-on distribution libraries often model
exchanges between distributed parts of an application as function calls as
well. While convenient, this approach is fundamentally broken because the
semantics of local and remote function calls, especially their failure
modes, are markedly different.
In Erlang, processes communicate via asynchronous message passing. This works even if a process
is on a remote node because the Erlang virtual machine supports passing
messages from one node to another. When one node joins another, it also
becomes aware of any nodes already known to the other. In this manner, all
the nodes in a cluster form a mesh, enabling any process to send a message
to another process on any other node in the cluster. Each node in the
cluster also automatically tracks liveness of other nodes in order to
become aware of nonresponsive nodes. The advantages of asynchronous
message passing in systems running on a node is extended to systems
running in clusters, as replies can be received alongside errors and
timeouts.
Erlang’s message passing and clustering primitives can serve as the
basis for a wide variety of distributed system architectures. For example,
service-oriented architecture (SOA), especially in its more modern variant, microservices, is a
natural fit for Erlang given the ease of developing and deploying
server-like processes. Clients treat such processes as services,
communicating with them by exchanging messages. As another example,
consider that Erlang clusters do not require master or leader nodes, which
means that using them for peer-to-peer systems of replicas works well.
Clients can send service request messages to any peer node in the cluster,
and the peer can either handle the request itself or route it to another
peer. The concept of standalone clusters, known as groups that communicate with each other through
gateway nodes that can go up and down or lose connectivity exists in a
framework called SD Erlang. Another
popular distributed framework, inspired by the Amazon Dynamo paper published in 2007, is
Riak Core, offering consistent hashing to schedule jobs, recovery from
partitioned networks and failed nodes through consistent hashing, eventual
consistency, and virtual nodes dividing state and the data into small,
manageable entities that can be replicated and moved across nodes.
With distributed systems, you can also achieve scalability. In fact, availability, consistency, and
scalability go hand in hand, each affecting the others. It starts with the
concurrency model and the concept of message passing within the node,
which we extend across the network to use for clustering nodes. Erlang’s
virtual machine takes advantage of today’s multicore systems by allowing processes to execute with true
concurrency, running simultaneously on different cores. Because of the
symmetric multiprocessing (SMP) capabilities of the Erlang virtual machine, Erlang is
already prepared to help applications scale vertically as the number of
cores per CPU continues to increase. And because adding new nodes to a
cluster is easy—all it takes is to have that node contact just one other
node to join the mesh—horizontal scaling is also well within easy reach.
This, in turn, allows you to focus on the real challenge when dealing with
distributed systems: namely, distributing your data and state across hosts
and networks that are unreliable.
Summing Up
To make design, implementation, operation, and maintainability
easier and more robust, your programming language and middleware have to
be compact, their behavior in runtime predictable, and the resulting code
base maintainable. We keep talking about fault-tolerant, scalable, soft
real-time systems with requirements for high availability. The problems
you have to solve do not have to be complicated in order to benefit from
the advantages Erlang/OTP brings to the table. Advantages will be evident
if you are developing solutions targeted for embedded hardware platforms
such as the Parallela board, the BeagleBoard, or the Raspberry Pi. You
will find Erlang/OTP ideal for the orchestration code in embedded devices,
for server-side development where concurrency comes in naturally, and all
the way up to scalable and distributed multicore architectures and
supercomputers. It eases the development of the harder software problems
while making simpler programs even easier to implement.
What You’ll Learn in This Book
This book is divided into two sections. The first part, from Chapter 3 to Chapter 10,
deals with the design and implementation of a single node. You should read
these chapters sequentially, because their examples and explanations build
on prior ones. The second half of the book, from Chapter 11 to Chapter 16,
focuses on tools, techniques, and architectures used for deployment,
monitoring, and operations, while explaining the theoretical approaches
needed to tackle issues such as reliability, scalability, and high
availability. The second half builds in part on the examples covered in
the first half of the book, but can be read independently of it.
We begin with an overview of Erlang in Chapter 2, intended not to teach you the language but
rather as a refresher course. If you do not yet know Erlang, we recommend
that you first consult one or more of the excellent books designed to help
you learn the language, such as Simon St. Laurent’s Introducing
Erlang, Erlang Programming
by Francesco Cesarini and Simon Thompson, or any of the other books we
mention in Chapter 2. Our overview touches on the
major elements of the language, such as lists, functions, processes and
messages, and the Erlang shell, as well as those features that make Erlang
unique among languages, such as process linking and monitoring, live
upgrades, and distribution.
Following the Erlang overview, Chapter 3
dives into process structures. Erlang processes can handle a wide variety
of tasks, yet regardless of the particular tasks or their problem domains,
similar code structures and process lifecycles surface, akin to the common
design patterns that have been observed and documented for popular
object-oriented languages like Java and C++. OTP captures and formalizes
these common process-oriented structures and lifecycles into behaviors, which serve as the base elements of
OTP’s reusable frameworks.
In Chapter 4 we explore in detail our first
worker process. It is the most popular and frequently used OTP behavior,
the gen_server. As its name implies, it supports generic client-server structures,
with the server governing particular computing resources—perhaps just a
simple Erlang Term Storage (ETS) instance, or a pool of network
connections to a remote non-Erlang server—and granting clients access to
them. Clients communicate with generic servers synchronously in a
call-response fashion, asynchronously via a one-way message called a
cast, or via regular Erlang messaging
primitives. Full consideration of these modes of communication requires us
to scrutinize various aspects of the processes involved, such as what
happens if the client or server dies in the middle of a message exchange,
how timeouts apply, and what might happen if a server receives a message
it does not understand. By addressing these and other common issues, the
gen_server handles a lot of details independently of the
problem domain, allowing developers to focus more of their time and energy
on their applications. The gen_server behavior is so useful
that it not only appears in most nontrivial Erlang applications but is
used throughout OTP itself as well.
Prior to examining more OTP behaviors, we follow our discussion of
gen_server with a look at some of the control and observation
points the OTP behaviors provide (Chapter 5). These features reflect
another aspect of Erlang/OTP that sets it apart from other languages and
frameworks: built-in observability. If you want to know what your
gen_server process is doing, you can simply enable debug
tracing for that process, either at compile time or at runtime from an
Erlang shell. Enabling traces causes it to emit information that indicates
what messages it is receiving and what actions it is taking to handle
them. Erlang/OTP also provides functions for peering into running
processes to see their backtraces, process dictionaries, parent processes,
linked processes, and other details. There are also OTP functions for
examining status and internal state specifically for behaviors and other
system processes. Because of these debug-oriented features, Erlang
programmers often forego the use of traditional debuggers and instead rely
on tracing to help them diagnose errant programs, as it is typically both
faster to set up and more informative.
We then examine another OTP behavior, gen_fsm (Chapter 6), which supports a generic FSM pattern. As you may already know, an FSM is a system that has a finite
number of states, and incoming messages can advance the system from one
state to another, with side effects potentially occurring as part of the
transitions. For example, you might consider your television set-top box
as being an FSM where the current state represents the selected channel
and whether any on-screen display is shown. Pressing buttons on your
remote causes the set-top box to change state, perhaps selecting a
different channel, or changing its on-screen display to show the channel
guide or list any on-demand shows that might be available for purchase.
FSMs are applicable to a wide variety of problem domains because they
allow developers to more easily reason about and implement the potential
states and state transitions of their applications. Knowing when and how
to use gen_fsm can save you from trying to implement your own
ad hoc state machines, which often quickly devolve into spaghetti code
that is hard to maintain and extend.
Logging and monitoring are critical parts of any scalability success
story, since they allow you to glean important information about your
running systems that can help pinpoint bottlenecks and problematic areas
that require further investigation. The Erlang/OTP gen_event behavior (Chapter 7) provides support for subsystems that
emit and manage event streams reflecting changes in system state that can
impact operational characteristics, such as sustained increases in CPU
load, queues that appear to grow without bound, or the inability of one
node in a distributed cluster to reach another. These streams do not have
to stop with your system events. They could handle your
application-specific events originating from user interaction, sensor
networks, or third-party applications. In addition to exploring the
gen_event behavior, we also take a look at the OTP system
architecture support libraries (SASL) error-logging event handlers, which provide flexibility for
managing supervisor reports, crash reports, and progress reports.
Event handlers and error handlers are staples of numerous
programming languages, and they are incredibly useful in Erlang/OTP as
well, but do not let their presence here fool you: dealing with errors in
Erlang/OTP is strikingly different from the approaches to which most
programmers are accustomed.
After gen_event, the next behavior we study is
the supervisor (Chapter 8),
which manages worker processes. In Erlang/OTP, supervisor processes start
workers and then keep an eye on them while they carry out application
tasks. Should one or more workers die unexpectedly, the supervisor can
deal with the problem in one of several ways that we explain later in the
book. This form of handling errors, known as “let it crash,” differs
significantly from the defensive programming tactics that most programmers
employ. “Let it crash” and supervision, together a critical cornerstone of
Erlang/OTP, are highly effective in practice.
We then look into the final fundamental OTP behavior, the application (Chapter 9),
which serves as the primary point of integration between the Erlang/OTP
runtime and your code. OTP applications have configuration files that
specify their names, versions, modules, the applications upon which they
depend, and other details. When started by the Erlang/OTP runtime, your
application instance in turn starts a top-level supervisor that brings up
the rest of the application. Structuring modules of code into applications
also lets you perform code upgrades on live systems. A release of an
Erlang/OTP package typically comprises a number of applications, some of
which are part of the Erlang/OTP open source distribution and others that
you provide.
Having examined the standard behaviors, we next turn our attention
to explaining how to write your own behaviors and special processes (Chapter 10). Special processes are processes that follow certain design rules, allowing them to
be added to OTP supervision trees. Knowing these design rules can not only
help you understand implementation details of the standard behaviors, but
also inform you of their tradeoffs and allow you to better decide when to
use them and when to write your own instead.
Chapter 11 describes how OTP applications
in a single node are coupled together and started as a whole. You will
have to create your own release files, referred to in the Erlang world as
rel files. The rel file lists the
versions of the applications and the runtime system that are used by the
systools module to bundle up the software into a standalone
release directory that includes the virtual machine. This release
directory, once configured and packaged, is ready to be deployed and run
on target hosts. We cover the community-contributed tools rebar3 and relx, the best way to build your code and your
releases.
The Erlang virtual machine has configurable system limits and
settings you need to be aware of when deploying your systems. There are
many, ranging from limits regulating the maximum number of ETS tables or
processes to included code search paths and modes used for loading
modules. Modules in Erlang can be loaded at startup, or when they are
first called. In systems with strict revision control, you will have to
run them in embedded mode, loading modules at startup and crashing if modules do not
exist, or in interactive mode, where
if a module is not available, an attempt to load it is made
before terminating the process. An external monitoring heart process
monitors the Erlang virtual machine by sending heartbeats and invoking a
script that allows you to react when these heartbeats are not
acknowledged. You implement the script yourself, allowing you to decide
whether restarting the node is enough or whether—based on a history of
previous restarts—you want to escalate the crash and terminate the virtual
instance or reboot the whole machine.
Although Erlang’s dynamic typing allows you to upgrade your module
at runtime while retaining the process state, it does not coordinate
dependencies among modules, changes in process state, or
non–backward-compatible protocols. OTP has the tools to support system
upgrades on a system level, including not only the applications, but also
the runtime system. The principles and supporting libraries are presented
in Chapter 12, from defining your own
application-upgrade scripts to writing scripts that support release
upgrades. Approaches and strategies for handling changes to your database
schema are provided, as are guidelines for upgrades in distributed
environments and non–backward-compatible protocols. For major upgrades in
distributed environments where bugs are fixed, protocols improved, and
database schema changed, runtime upgrades are not for the faint of heart.
But they are incredibly powerful, allowing automated upgrades and nonstop
operations. Finding your online banking is unavailable because of
maintenance should now be a thing of the past. If it isn’t, send a copy of
this book to your bank’s IT department.
Operating and maintaining any system requires visibility into what
is going on. Scaling clusters require strategies for how you share your
data and state. And fault tolerance requires an approach to how you
replicate and persist it. In doing so, you have to deal with unreliable
networks, failure, and recovery strategies. While each of these subjects
merits a book of its own, the final chapters of this book will provide you
with the theoretical background needed when distributing your systems and
making them reliable and scalable. We provide this theory by describing
the steps needed to design a scalable, highly available architecture in
Erlang/OTP.
Chapter 13 will give you an overview of
the approaches needed when designing your distributed architecture,
breaking up your functionality into standalone nodes. In doing so, each
standalone node type will be assigned a
specific purpose, such as acting as a client gateway managing TCP/IP
connection pools or providing a service such as authentication or
payments. For each node type, we define an approach to specifying
interfaces and defining the state and data each node needs. We conclude
the chapter by describing the most common distributed architectural
patterns and the different network protocols that can be used to connect
them.
When you have your distributed architecture in place, you need to
make design choices that will impact fault tolerance, resilience,
reliability, and availability. You know what data and state you need in
your node types, but how are you going to distribute it and keep it
consistent? Are you going for the share-everything, share-something, or
share-nothing approach, and what are the tradeoffs you need to make when
choosing strong, causal, or eventual consistency? In Chapter 14, we describe the different approaches
you can take, introducing the retry strategies you need to be aware of in
case a request times out as the result of process, node, or network
failure or the mere fact that the network or your servers are running over
capacity.
It is easy to say that you are going to add hardware to make your
system scale horizontally, but alas, the design choices introduced in
Chapter 14 will have an impact on your
system’s scalability. In Chapter 15, we describe the impacts resulting from
your data-sharing strategy, consistency model, and retry strategy. We
cover capacity planning, including the load, peak, and stress tests you
need to subject your system to to guarantee it behaves in a predictable
way under heavy load even when the hardware, software, and infrastructure
around it are failing.
Once you’ve designed your scalability and availability strategies, you need to tackle monitoring. If
you want to achieve five-nines uptime, you need to not only know what is
going on, but also be able to quickly determine what happened, and why. We
conclude the book with Chapter 16, looking at
how monitoring is used for preemptive support and postmortem
debugging.
Monitoring focuses on metrics, alarms, and logs. This chapter
discusses the importance of system and business metrics. Examples of system metrics
include the amount of memory your node is using, process message queue
length, and hard-disk utilization. Combining these with business metrics,
such as the number of failed and successful login attempts, message
throughput per second, and session duration, yields full visibility of how
your business logic is affecting your system resources.
Complementing metrics is alarming, where you detect and report anomalies, allowing the system to take
action to try to resolve them or to alert an operator when human
intervention is required. Alarms could include a system running out of
disk space (resulting in the automatic invocation of scripts for
compressing or deleting logs) or a large number of failed message
submissions (requiring human intervention to troubleshoot connectivity
problems). Preemptive support at its best, detecting and resolving issues
before they escalate, is a must when dealing with high availability. If
you do not have a real-time view of what is going on, resolving issues
before they escalate becomes extremely difficult and cumbersome.
And finally, logging of
major events in the system helps you troubleshoot your
system after a crash where you lost its state, so you can retrieve the
call flow of a particular request among millions of others to handle a
customer services query, or just provide data records for billing
purposes.
With your monitoring in place, you will be ready to architect
systems that are not only scalable, but also resilient and highly
available. Happy reading! We hope you enjoy the book as much as we enjoyed
writing it.