Strata Santa Clara 2013 is a wrap, and I had a great time speaking and interacting with all of the amazing attendees. I’d like to recap the talk that Tim Palko and I gave, entitled “Large-Scale Data Collection and Real-Time Analytics Using Redis”, and maybe even answer a few questions we were asked following our time on stage.
Our talk centered around a system we designed to collect environmental sensor data from remote sensors located in various places across the country and provide real-time visualization, monitoring, and event detection. Our primary challenge for the initial phase of development proved to be scaling the system to collect data from thousands of nodes, each of which sent sensor readings roughly once per second, which maintaining the ability to query the data in real time for event detection. While each data record was only ~300kb, our expected maximum sensor load indicated a collection rate of about 27 million records, or 8GB, per hour. However, our primary issue was not data size, but data rate. A large number of inserts had to happen each second, and we were unable to buffer inserts into batches or transactions without incurring a delay in the real-time data stream.
When designing network applications, one must consider the two canonical I/O bottlenecks: Network I/O, and Filesystem I/O. For our use case, we had little influence over network I/O speeds. We had no control over the locations where our remote sensors would be deployed, or in the bandwidth or network infrastructure of said facilities. With network latency as a known variant, we focused on addressing the bottleneck we could control: Filesystem I/O. For the immediate collection problem, this means we evaluated databases to insert the data into as it was collected. While we initially attempted to collect the data in a relational database (PostgreSQL), we soon discovered that while PostgreSQL could potentially handle the number of inserts per second, it was unable to respond to read queries simultaneously. Simply put, we were unable to read data while we were collecting it, preventing us from doing any real-time analysis (or any analysis at all, for that matter, unless we stopped data collection).
The easiest way to avoid slowdowns due to filesystem operations is to avoid the filesystem altogether, a feat we achieved by leveraging Redis, an open-source in-memory NoSQL datastore. Redis stores all data in RAM, allowing lightning fast reads and writes. With Redis, we were easily able to insert all of our collected data as it was transmitted from the sensor nodes, and query the data simultaneously for event detection and analytics. In fact, were were also able to leverage Pub/Sub functionality on the same Redis server to publish notifications of detected events for transmission to SMTP workers, without any performance issues.
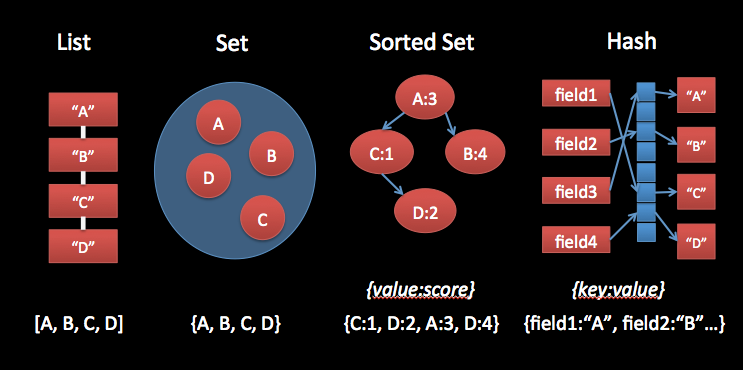
In addition to speed, Redis features advanced data structures, including Lists, Sets, Hashes, and Sorted Sets, rather than the somewhat limiting key/value pair consistent with many NoSQL stores. Sorted Sets proved to be an excellent data structure to model timeseries data, by setting the score to the timestamp of a given datapoint. This automatically ordered our timeseries’, even when data was inserted out of order, and allowed querying by timestamp, timestamp range, or by “most recent #” of records (which is merely the last # values of the set).
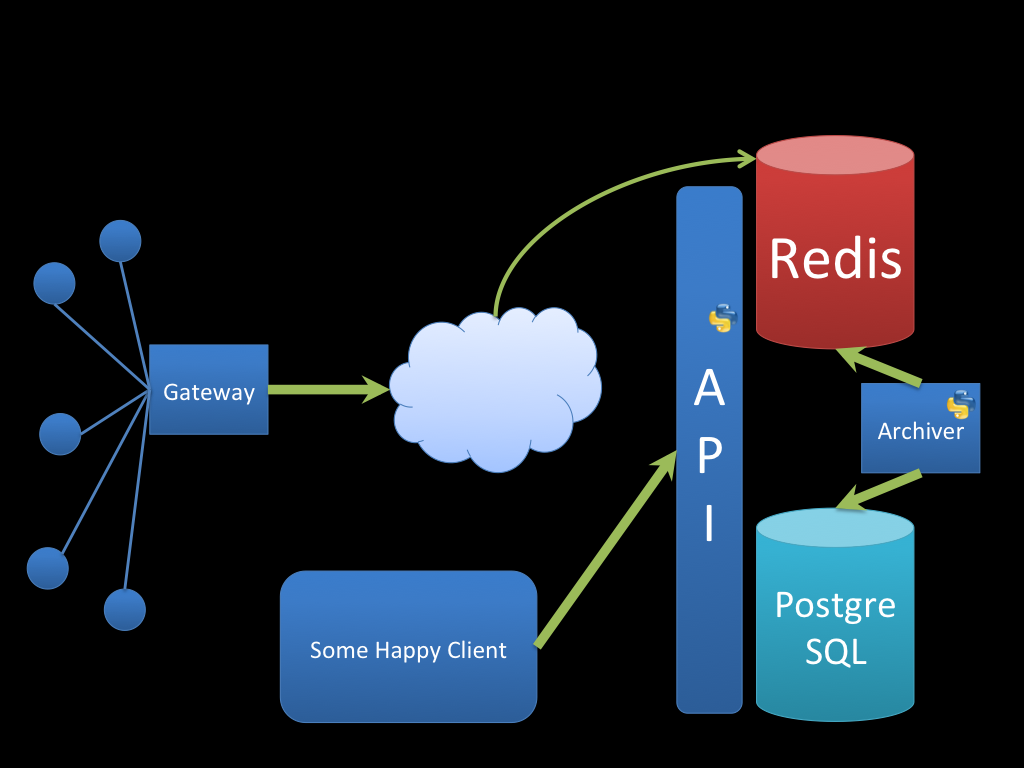
Of course, nothing is perfect, and our solution was no exception. Our use case requires us to archive our data permanently, for post-analysis, rather than throwing away stale datapoints as is common in other real-time applications. Since Redis keeps all data in RAM, our Redis datastore was only able to hold as much data as the server had RAM. Our data, inserted at a rate of 8GB/hour, quickly outgrew this limitation. To scale this solution and archive our data for future analysis, we set up an automated migration script to push the oldest data in our Redis datastore to a PostgreSQL database with more storage scalability. Writing a REST API as an interface to our two datastores allowed client applications a unified query interface, without having to worry about which datastore a particular piece of data resided in.
With the collection architecture described in place, generating automated event detection and real-time notifications was made easy, again through the use of Redis. Since Redis also offers Pub/Sub functionality, we were able to monitor incoming data in Redis using a small service, and push noteworthy events to a notification channel on the same Redis server, from which subscribed SMTP workers could send out notifications in real-time.
Our experiences show Redis to be a powerful tool for Big Data applications, specifically for high-throughput data collection. The benefits of Redis as a collection mechanism, coupled with data migration to a deep analytics platform, such as relational databases or even Hadoop’s HDFS, yields a powerful and versatile architecture suitable for many Big Data applications.
Want to learn more? Follow @AaronCois on Twitter, and check out the Digital Intelligence and Investigation team at the Carnegie Mellon University SEI.