Multitenancy on Hadoop: Is your cluster half full?
Over-allocated but underutilized clusters require more than best practice solutions.
 Olafur Eliasson's glass front. (source: Tristan Ferne on Flickr)
Olafur Eliasson's glass front. (source: Tristan Ferne on Flickr)
Initial deployments of Hadoop focused on single batch-oriented workloads. If you needed to run multiple workloads at the same time, you were forced to split your clusters. With Hadoop 2 and YARN, new scheduling algorithms allow multiple workloads on the same cluster, accessing a common data pool along with hardware and software resources. Cluster management tools like Cloudera Navigator and Apache Ambari help make provisioning and operating clusters much easier. Problem solved, right? Not exactly…
In practice, Hadoop administrators have discovered that they have little visibility under the hood to understand what is going on with resource utilization in the cluster. They see the symptoms—for instance, jobs running very slowly—but have no ability to diagnose the root cause of the issue. Is this because they have compute-intensive jobs, or is it because they are I/O bound? As more jobs run on the cluster, YARN schedules all available memory, but containers running these jobs may only use a fraction of their allocated memory, resulting in a backlog of jobs and further slow-down. This article sheds light on the problem of the over-allocated but underutilized cluster, and why best practices such as cluster tuning are a band-aid fix for a much larger performance problem.

Learn faster. Dig deeper. See farther.
Over-allocated but underutilized clusters
The problem of the over-allocated but underutilized cluster stems from the way that YARN allocates memory across the cluster to execute jobs in its queues. I’ll present a simplified view of the scheduling done by YARN in order to illustrate the problem. Readers who would like to learn more about YARN scheduling and containers can find abundant information online or directly visit the Apache YARN site.
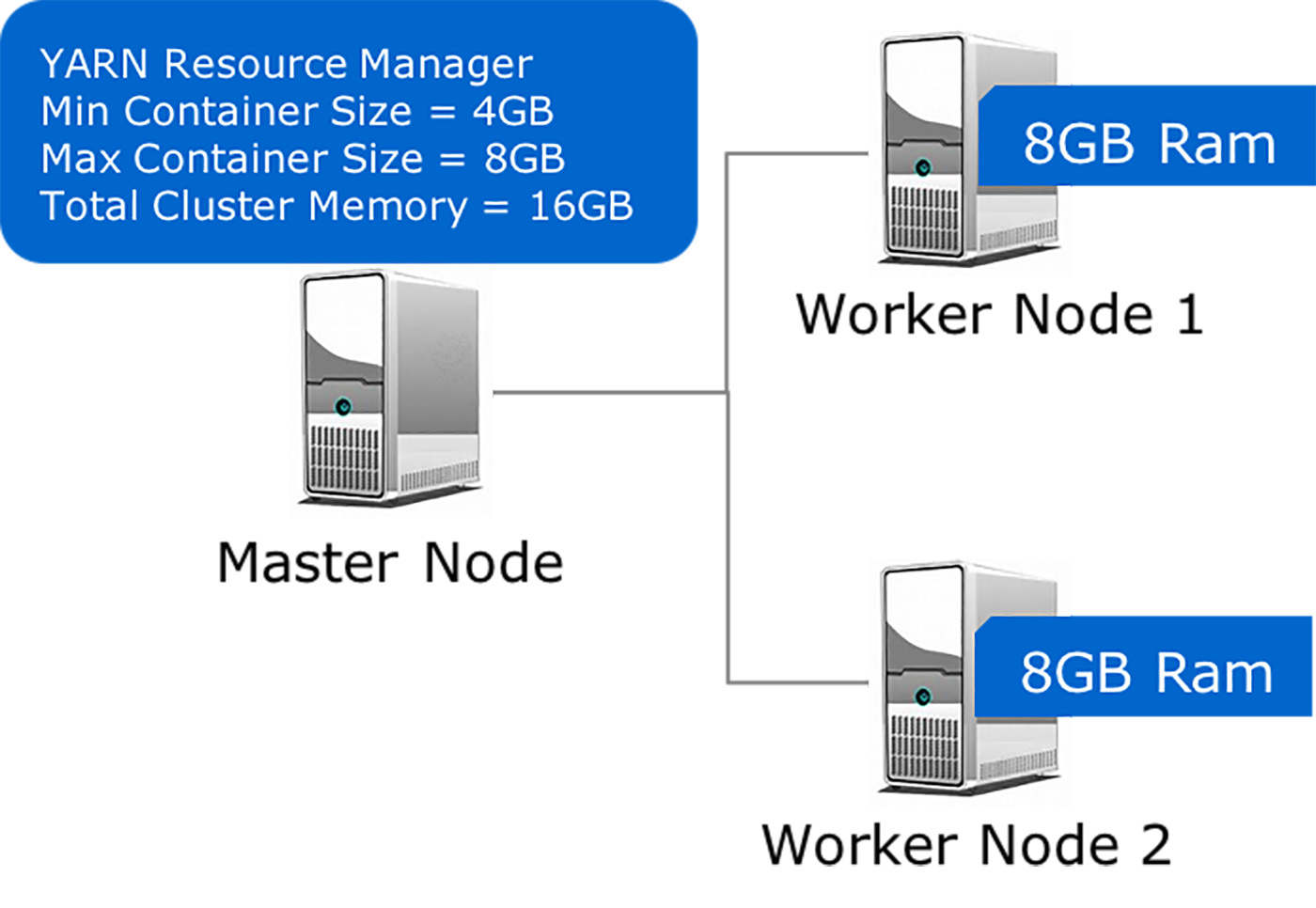
Figure 1 illustrates a three-node cluster with one Master Node that runs the Hadoop services, including the YARN Resource Manager (RM) and two worker nodes that run the Node Manager (NM) and Application Manager (AM) services. At cluster start, the NMs on Worker Nodes 1 and 2 report to RM that they each have 8GB of memory. The RM is configured to have a minimum container size of 4GB and has a computed maximum cluster memory of 16GB.

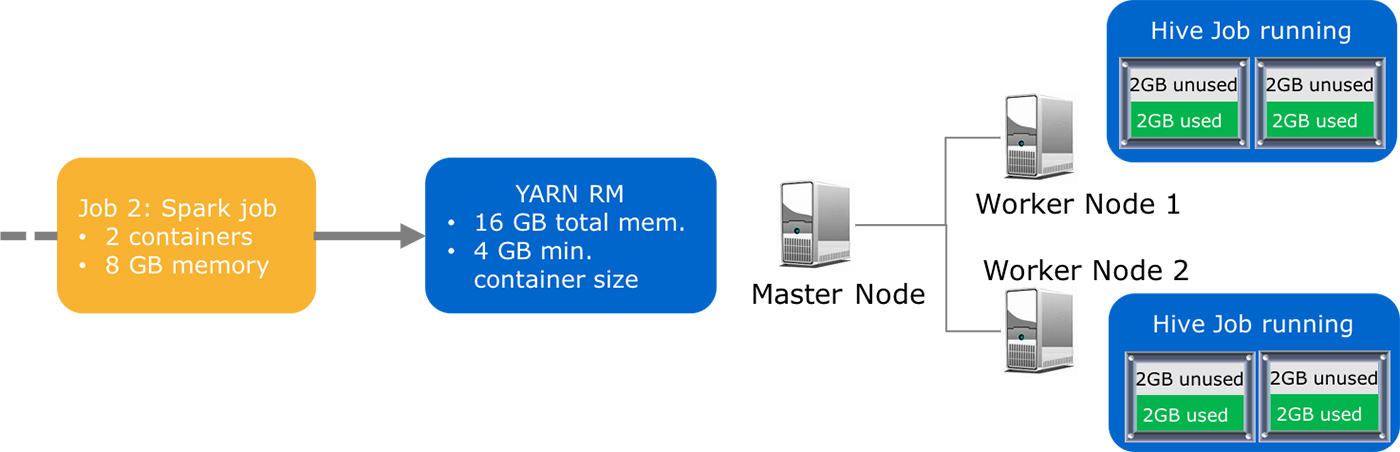
Now, let’s add some workload on this cluster. See Figure 2. There is only one queue and YARN looks at the memory requirements of the first job in its queue, a Hive job. It allocates four containers as requested by the job, with two containers each on Worker Nodes 1 and 2. YARN allocates containers based on the configured minimum container size, and in this case, even though the Hive job requires only 2GB of actual physical memory per container, it will receive 4GB-sized container allocations.
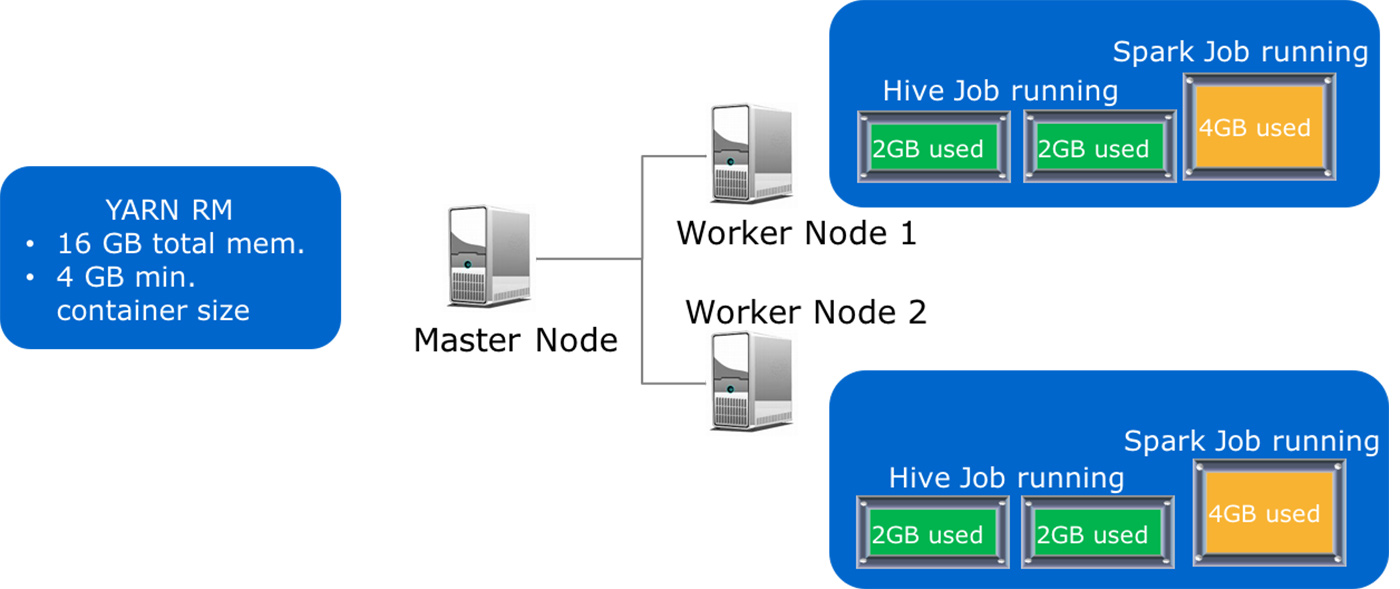
Since the minimum container size for this cluster is 4GB, once YARN allocates four containers to the Hive Job, from its point of view the cluster is now at capacity and cannot accept any new jobs. See Figure 3. The result of this decision is that the Spark job is left waiting for the Hive job to free up one or more containers. However, as we can see, there is enough memory available on each node to accommodate the memory needs of the Spark job. This is the classic example of an over-allocated but underutilized cluster. What options does a Hadoop administrator have to ensure effective utilization?
Adaptive, automatic tuning overcomes inefficient cluster utilization
The traditional option available to Hadoop administrators when combating inefficient cluster utilization is limited to static tuning of Hadoop via configuration files. This is effective when all the applications that run on a cluster are homogeneous and exhibit similar resource consumption profiles. However, for multi-tenant clusters running multiple workloads of different resource consumption profiles, this is not very effective. This is evident even in the simple example presented above. What is needed is an adaptive and automatic tuning of the cluster based on the real-time resource utilization of the cluster.
Companies have solved this problem in different ways. For instance, the Cloudbreak solution from SequenceIQ adds nodes on the fly to handle new workloads. This does not address the problem of underutilization, but it ensures that the Spark and Hive jobs can run simultaneously, provided you have available cloud resources. Another potential solution to the problem of dynamic scaling of YARN resources is Apache Myriad from MapR and Mesosphere, covered in a previous blog post from O’Reilly.
Companies like Pepperdata are also intrigued by this problem and have developed a solution that does not rely on static activities like tuning the configuration files and queues, which may be effective in some, but not all, situations. Pepperdata instruments real-time, second-by-second monitoring in the cluster for an accurate view of the hardware resources consumed by each task running on every node. Using this information, Pepperdata can algorithmically build a global view of the RAM, CPU, disk, and network availability and utilization of the cluster at the current moment. It can then construct a model of predicted utilization over the next roughly 30 seconds to understand how much more work can fit. This model is constantly re-evaluated in order to make the best real-time decision of the workload that can be accommodated in the cluster. If we apply this solution to the example presented earlier, the result is that we can free up the 4GB unused on each Worker Node so YARN allocates two 4GB containers needed to run the Spark job at the same time as the Hive job—see Figure 4:
The example presented above has been artificially constrained in multiple dimensions to illustrate the problem where a Hadoop cluster is allocated to capacity and can yet be underutilized. Let’s now examine a real-world example where this solution has resulted in significant cluster capacity utilization for an enterprise customer.
Use case of adaptive, automatic tuning in the enterprise
In this use case, the customer is a large communications company using Hadoop to get a 360-degree view of their own customers. They had a cluster running YARN in a multi-tenant environment that runs multiple workloads, but they did not have insight into resource utilization of the clusters. They decided to explore Pepperdata’s Dynamic Capacity Allocation (DCA) algorithm to try to improve cluster utilization. Prior to turning on DCA, the real-time monitoring revealed that while the cluster was at capacity from a job scheduling perspective, it had unused hardware resources.
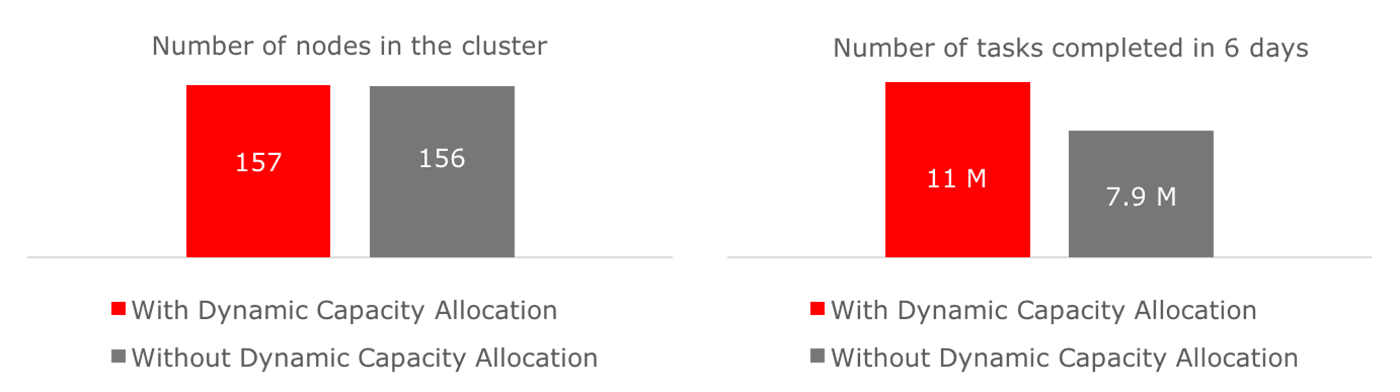
Figure 5 illustrates a test conducted on the customer’s production cluster over a six-day period, with roughly half of the nodes in the cluster running Pepperdata’s DCA algorithm. At the end of the test, the nodes that ran with Pepperdata’s DCA algorithm completed 11M tasks compared to the other half, which only completed 7.9M tasks. The measured throughput gain during busy periods in the cluster was 43%.
Conclusion
YARN is a key technological innovation that helped Hadoop evolve from batch-oriented MapReduce to a data processing platform capable of running multiple workloads in a multi-tenant environment. It enables enterprises to simplify their data center environment and reduce costs significantly. However, to maximize cost savings and cluster efficiency, you need to consider complementary technologies that rely on the real-time availability of the hardware resources in the cluster, not just a static view of resources at rest.
This post is a collaboration between O’Reilly and Pepperdata. See our statement of editorial independence.