Reevaluating administrative processes for apps in the cloud
Ask yourself if you really need administrative processes, or if a simple change in architecture could obviate them.
 Clock face (source: khfalk via Pixabay)
Clock face (source: khfalk via Pixabay)
In Beyond the Twelve-Factor App, I present a new set of guidelines that builds on Heroku’s original 12 factors and reflects today’s best practices for building cloud-native applications. I have changed the order of some to indicate a deliberate sense of priority, and added factors such as telemetry, security, and the concept of “API first” that should be considerations for any application that will be running in the cloud. These new 15-factor guidelines are:
- One codebase, one application
- API first
- Dependency management
- Design, build, release, and run
- Configuration, credentials, and code
- Logs
- Disposability
- Backing services
- Environment parity
- Administrative processes
- Port binding
- Stateless processes
- Concurrency
- Telemetry
- Authentication and authorization
The 12th and final factor originally stated, “Run admin/management tasks as one-off processes.” I feel that this factor can be misleading. There is nothing inherently wrong with the notion of an administrative process, but there are a number of reasons why you should not use them.

Learn faster. Dig deeper. See farther.
The problem with the original 12-factor recommendation is that it was written in an opinionated way with a bias toward interpreted languages like Ruby that support and encourage an interactive programming shell. Such shells are referred to as REPLs, which is an acronym for read-eval-print loop. Administrative processes were a feature the authors wanted customers to utilize.
I contend that, in certain situations, the use of administrative processes is actually a bad idea, and you should always be asking yourself whether an administrative process is what you want, or whether a different design or architecture would suit your needs better. Examples of administrative processes that should probably be refactored into something else include:
- Database migrations
- Interactive programming consoles (REPLs)
- Running timed scripts, such as a nightly batch job or hourly import
- Running a one-off job that executes custom code only once
First, let’s take a look at the issue of timers (usually managed with applications like Autosys or Cron). One thought might be to just internalize the timer and have your application wake itself up every n hours to perform its batch operations. On the surface, this looks like a good fix, but what happens when there are 20 instances of your application running in one availability zone, and another 15 running in the other zone? If they’re all performing the same batch operation on a timer, you’re basically inciting chaos at this point, and corrupt or duplicate data is going to be just one of the many terrible things that arise from this pattern.
Interactive shells are also problematic for a number of reasons, but the largest of those is that even if it were possible to reach that shell, you’d only be interacting with the temporary memory of a single instance. If the application had been built properly as a stateless process, then I would argue that there is little to no value in exposing a REPL for in-process introspection. The Telemetry chapter of this book actually covers more aspects of application monitoring that even further negate the need for interactive access to a cloud process.
Next, let’s take a look at the mechanics of triggering a timed or batch administrative process. This usually happens with the execution of a shell script by some external timer stimulus like Cron or Autosys. In the cloud, you can’t count on being able to invoke these commands, so you need to find some other way to trigger ad hoc activity in your application.
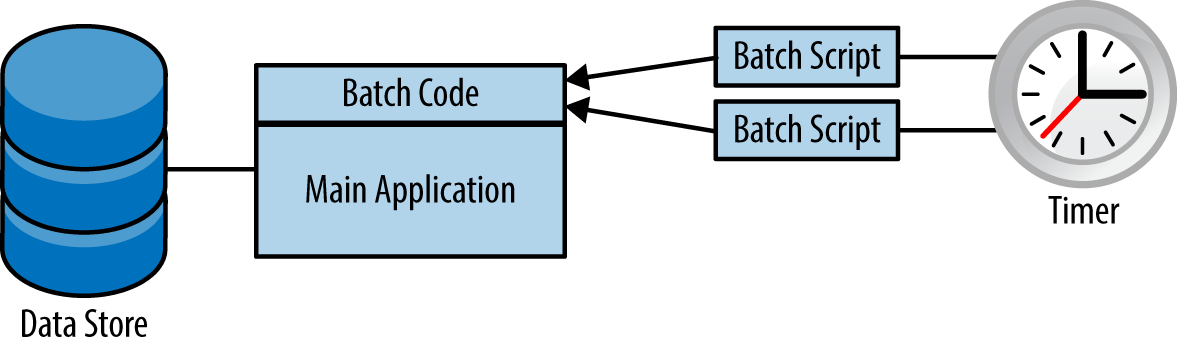
In figure 1, you can see a classic enterprise architecture of an application that has its regular duties and supports batch or timed operation via the execution of shell scripts. This is clearly not going to work in the cloud.
There are several solutions to this problem, but the one that I have found to be most appealing, especially when migrating the rest of the application to be cloud native, is to expose a RESTful endpoint that can be used to invoke ad hoc functionality, as shown in figure 2.
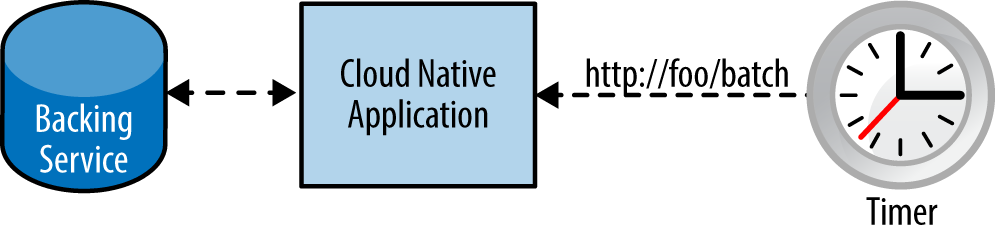
Another alternative might be to extract the batch-related code from the main application and create a separate microservice, which would also resemble the architecture in the preceding diagram.
This still allows at-will invocation of timed functionality, but it moves the stimulus for this action outside the application. Moreover, this method also solves the at most once execution problem that you would have from internal timers on dynamically scaled instances. Your batch operation is handled once, by one of your application instances, and you might then interact with other backing services to complete the task. It should also be fairly straightforward to secure the batch endpoint so that it can only be operated by authorized personnel. Even more useful is that your batch operation can now scale elastically and take advantage of all the other cloud benefits.
Even with the preceding solution, there are several application architecture options that might make it completely unnecessary to even expose batch or ad hoc functionality within your application.
If you still feel you need to make use of administrative processes, then you should make sure you’re doing so in a way that is in line with the features offered by your cloud provider. In other words, don’t use your favorite programming language to spawn a new process to run your job; use something designed to run one-off tasks in a cloud-native manner. In a situation like this, you could use a solution like Amazon Web Services Lambdas, which are functions that get invoked on-demand and do not require you to leave provisioned servers up and running like you would in the preceding microservice example.
When you look at your applications, whether they are green field or brown field, just make sure you ask yourself if you really need administrative processes, or if a simple change in architecture could obviate them.