 City walls (source: Pixabay)
City walls (source: Pixabay) As Site Reliability Engineers (SREs) at Google running a service in a shared production environment, we usually configure the service to create multiple instances of the program (for redundancy, availability, and throughput), which are then scheduled into a subset of machines in the data center. The service owner decides how many replicas, or tasks, to run, and how many CPU/RAM resources to provision for each task. These decisions determine how much load is processed for each task and how many computing resources the job needs to serve it.
We found that running jobs with fewer, bigger tasks could significantly improve our efficiency (by 25% for the example described in this article), which prompted us to explore and employ vertical scaling to improve the efficiency of our fleet of computing infrastructure. In this article we describe the technique we used and share what we learned. While this technique can be highly effective, especially in cloud-based and shared computing environments, there are some caveats and trade-offs we’ll also share so you can assess the viability of this technique for fine tuning the efficiency of your services.
Why Can Bigger Replicas Be More Efficient?
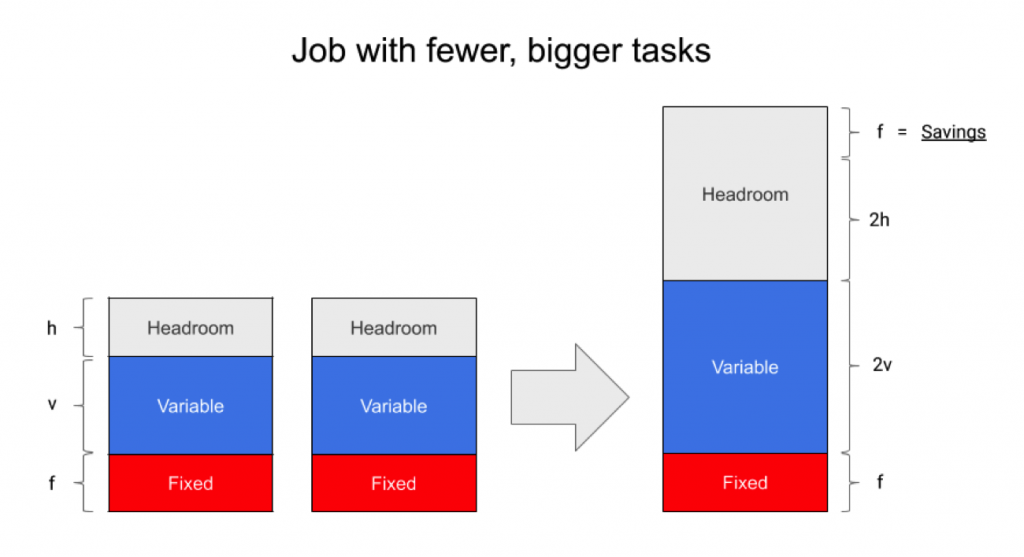
The idea behind this optimization is to run scheduled jobs with fewer, bigger tasks. To see how this helps with efficiency, consider the following classification of task costs:

Block “v” in the middle indicates the portion of resources that are proportional, or at least correlated, with the amount of work being processed (e.g., network requests). Block “f” at the bottom represents the cost that a developer pays to run a scheduled task. It is “fixed” on a per-replica basis and does not vary depending on the load. Examples of “fixed“ costs are static variables in the program, binary text, monitoring, logging, and keeping frontend/backend connections open.
Reducing the task count therefore reduces the total amount of fixed costs consumed by the job. An additional effect of this change is an increase of the “headroom” portion (block “h”). You can reclaim and use the extra capacity for other purposes, such as running other jobs!
Several data points and observations suggest that evaluating the fleet through the eyes of this technique could result in significant resource savings. For example:
- Machines are getting bigger. The average amount of CPU cores per chip (and per machine) are increasing, and that trend is expected to continue. On the other hand, task shapes (that is, the amount of CPU/RAM provisioned for a single task) haven’t grown as much during the same time period. Having proportionally bigger tasks would allow for a reduction in task counts.
- There is a preference for horizontal scaling. Service owners have historically preferred horizontal scalability (number of instances) over vertical scalability (resources of each instance) because of management simplicity and increased task redundancy. Although this approach may righteously prioritize service availability, its effects on reduced efficiency can be sometimes overlooked. A careful investigation of vertical scaling can result in efficiency gains without sacrificing the management simplicity and redundancy that comes with horizontal scaling.
- Resource configurations become out-of-date over time. Jobs change. Software in general is constantly changing and so are its scalability characteristics. It is reasonable to assume that many jobs will eventually drift away from optimal efficiency.
- High utilization does not mean high efficiency. If the analysis for sizing a job is indeed outdated, then there’s a chance that the size limits are set far lower than the jobs’ current scaling capabilities. Service owners might be tempted to believe that a job is efficient only because its utilization is high, when in fact they can greatly improve the status quo for those jobs.
- Reshaping can (nonetheless) improve utilization. Headroom capacity on every task is designed, among other things, to handle bursts of load. With bigger tasks, the bursts of traffic are smaller in proportion to the total task size, which means that on average, the headroom can be proportionally smaller. The increased parallelism also allows for higher utilization without detrimental impact on tail latency. The side effect of this is improved load balancing, since more “shards” of load can fit into bigger buckets and task overloading can be avoided.
So You Want to Reshape Your Job?
To reshape a job, apply an iterative process where you evaluate the job through different sizes. The steps for that are:
- Identify and monitor the relevant SLO and efficiency metrics. The SLO metrics are often the error ratio and the 99th-quantile response time of a certain service, but vary depending on the scope and responsibilities of the job. We cover the efficiency metrics in more detail in the next section, “Selecting appropriate metrics.”
- Choose the tasks to experiment with. From a reliability standpoint, it makes sense to try out the settings on a subset of tasks within a job before replicating the optimal settings to the rest of the tasks. For example, use a region or data center, or a subset of tasks in a region. Note that it’s important to select an experiment set representative of a typical workload. Also, make sure that the experiment runs long enough to experience peak load.
- Resize the job at a suitable pace. Using an exponential approach can be effective to quickly find the optimal size—e.g., halving the number of tasks and adding twice as many CPU/RAM resources to each one. Changes can be made at lower rates (e.g., linear) if the job is particularly sensitive.
- Evaluate the collected efficiency metrics to ensure that there’s an efficiency win, while still meeting the SLO criteria for the job. It’s important to know not just which metrics are important, but also how much improvement is worth the reshaping effort. A 1% efficiency gain may easily pay for itself if your job pool is big enough.
- If the metrics analysis indicates that the job benefited from the resizing, repeat steps 3 and 4. Once the benefits are negligible or nonexistent, replicate the settings to other tasks in the job. Perform experiments one region at a time to avoid tripping on region-specific differences in behavior.
Selecting appropriate metrics
To determine whether the task is increasing in productivity, it is necessary to identify appropriate metrics that measure efficiency. Efficiency metrics are often represented as QPS/CPU (queries-per-second-per-CPU) or service productivity. The latter can be particularly useful since it is user-defined and abstracts the actual work being performed.
To ensure that the jobs remain healthy as their individual workload increases, it is important to look out for regressions in:
- Network requests tail latency, as seen by clients;
- Network requests throughput;
- Disproportional increases in mutex wait times and lock contention;
- Garbage collection or queuing, such as thread pool queuing times in C++; and
- Any other relevant “horizontal” metrics (e.g., memory bandwidth, scheduling delays, etc.).
The idea is that these metrics are allowed to degrade, as long as the overall efficiency improves and SLOs continue to be met.
Note that you should collect and analyze metrics during periods of peak load. Depending on the job, that might not happen for hours or days, which might determine the speed and length of the overall exercise.
Finally, this step might require making adjustments to some of the flags or tunables in the job (for example, increase the number of threads to avoid thread pool starvation and bring throughput back up). Even if productivity does not improve after a resize, it’s worth understanding and localizing the bottlenecks involved so you can assess whether the task has indeed reached its scalability limits.
Analyzing a Specific Case Study
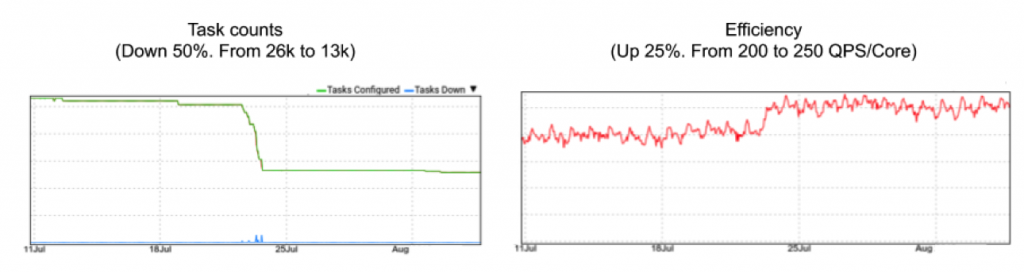
Let’s look at a specific instance of how this played out at Google, when we reshaped a job that analyses video statistics and makes them available to clients. This exercise involved changing a job that had 26,000 tasks of 1.9 cores each, to 13,000 of 3.8 cores each. This resulted in an increase in efficiency of almost 25%, from 200 queries-per-second-per-core to 250 queries-per-second-per-core.
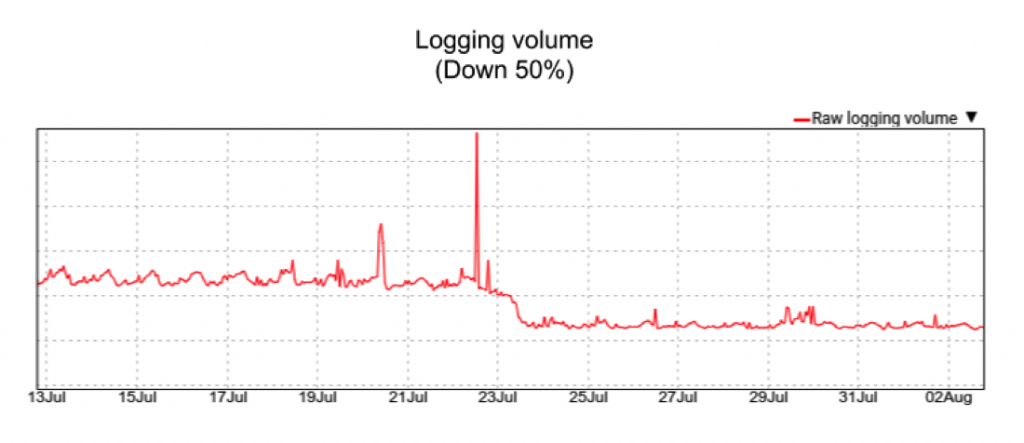
Some other fixed costs, such as the amount of debug logging being performed across all tasks, was reduced by almost half:
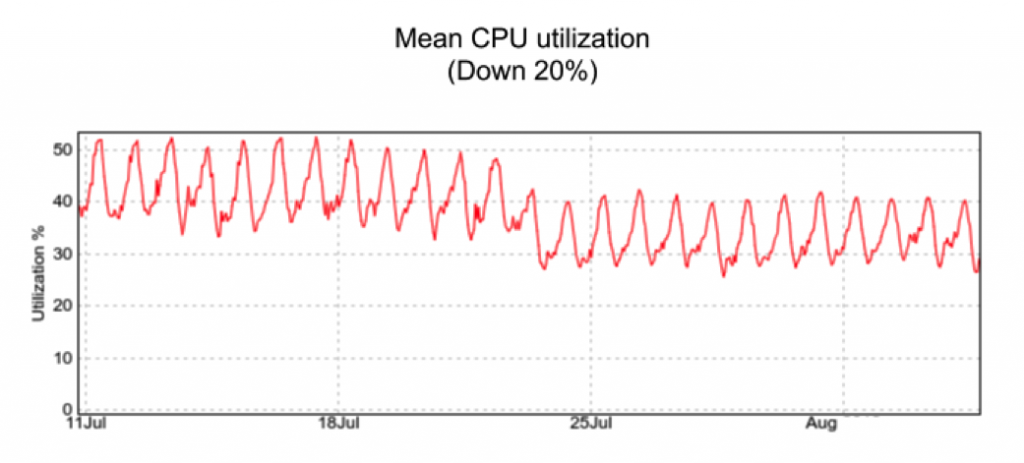
Finally, as the job used fewer resources to do the same amount of work, its utilization dropped:
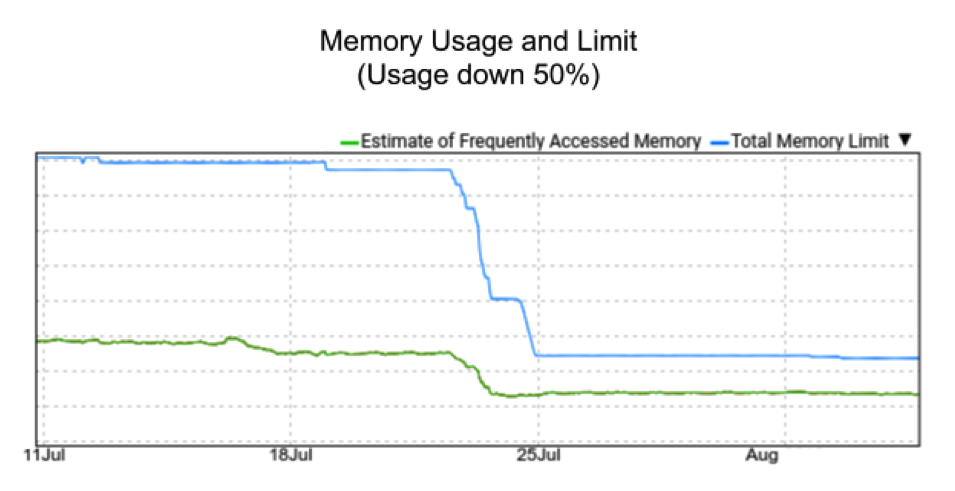
This meant that the user could reclaim part of the CPU and RAM resources to bring utilization back up. In the case of memory, service owners were able to reclaim two thirds of the memory capacity of the job:
What Can Go Wrong? Risks and Caveats
We have found that, as tasks become bigger and start processing a higher amount of load, different types of phenomena may start happening that hamper their ability to continue scaling—even jeopardizing the stability of the service in some extreme scenarios. For instance, contention in multi-threaded applications may increase. This can have a negative effect on network latency as perceived by clients, or in the overall productivity of the service. Similarly to contention, tasks that are too large could potentially saturate the memory bandwidth of the machine or CPU socket they run in; the same could happen for network bandwidth or disk/IO storage bandwidth. Also, bigger tasks will reduce the amount of spare capacity that the machine can use to run other tasks. Consequently, the cluster scheduler may have a more difficult time bin-packing services and finding a suitable machine in the data center to run in. Such scheduler delays could affect startup times and ultimately service availability. With all this having been said, our view is that the potential for major resource savings are an incentive to reshape jobs even in the presence of these risks and caveats.
Trading off Latency for Efficiency
Our experience with this so far has further shown us that reshaping services in the data center can reap benefits to resource usage and efficiency. These resource savings are traded off by a degradation of the latency seen by the clients of such services. This project’s primary motive is to enable us to assign a “resource cost equivalent” to the latency/performance offered by a service. For instance, taking non-critical services to the extreme of efficiency at the expense of higher latency, while provisioning mission-critical services with additional resources for high performance. The ultimate goal is for your scheduling system (or the data center administrator) to be able to grasp, monitor, and control such trade-offs so it can offer improved fairness when allocating resources across services.
Conclusion
Technology is seeing an upward trend in machine sizes. This, with other factors, makes a compelling case for using vertical scalability, which can reduce fixed costs from jobs and improve software efficiency. Google has taken notice and is actively revising the shape of its jobs in order to reduce the footprint of its computing infrastructure, thereby resulting in actual monetary savings. Organizations can apply this technique regardless of their scale, and in Google’s case, this allows our products to support a larger number of users.
This post is part of a collaboration between O’Reilly and Google. See our statement of editorial independence.