Editor’s note: this post is a follow-up to a recent webcast, “Getting the Most Out of Your NoSQL DB,” by the post author, Alex Bordei.
As product manager for Bigstep’s Full Metal Cloud, I work with a lot of amazing technologies. Most of my work actually involves pushing applications to their limits. My mission is simple: make sure we get the highest performance possible out of each setup we test, then use that knowledge to constantly improve our services.
Here are some of the things I’ve learned along the way about how NoSQL databases scale vertically and horizontally, and what things you should consider when building a DB cluster. Some of these findings can be applied to RDBMS as well, so read on even if you’re still a devoted SQL fan. You might just get up to 60% more performance out of that database soon enough.
-
Never assume linearity in scaling
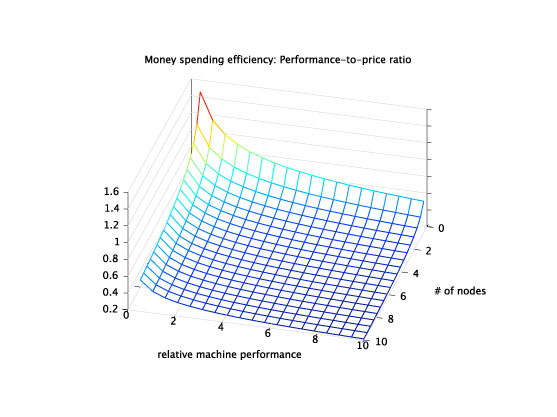
Money = Software (in)efficiency x hardware cost. Scaling distributed applications by making them parallel does not necessarily increase performance. Sometimes, it might actually hurt performance, as Amdahl’s law shows. Also, hardware prices grow exponentially as specs increase. A CPU with eight cores can be 10 times more expensive than one with four, as hardware prices can grow exponentially as specs increase.
This means there is usually a sweet spot between scaling horizontally and vertically — where the best performance per price is achieved for a certain setup. Depending on the design of each application and on the use case, that spot can vary.
-
Tests speak louder than specs
Though researching vendor documentation is useful, the best way to get an idea of how your particular software stack scales is to simply test it. Both virtualized and bare metal clouds will allow you to commission up to hundreds of machines for as little as a few hours, so there is really no excuse not to test.
-
Mind the details: Memory & CPU numbers matter
Dual in-line memory modules (DIMMs) and CPU cores are not created equal. I personally saw memory access speed vary by as much as 20% when going from 1333 MHz DIMMs to 1866 MHz. This can make a tremendous difference for in-memory databases like Redis, Couchbase, or Exasol. Don’t assume that RAM is just “fast enough,” and don’t underestimate the importance of the little things. It may be that the number at the end of the spec, the one you’ve never paid attention to before, can shave thousands off your budget.
The same thing goes for CPU frequencies and generations in situations where the application requires significant computing performance. Try turning Hyper Threading on/off in your CPU and look at performance before and after. If the setup doesn’t require virtualization, turn off Intel VT as well. We’ve seen setups generate 10% more performance after switching these off — that can be the difference between paying for nine or 10 servers at the end of the month. It’s not at all negligible.
-
Do not neglect network latency
Every distributed database will do a great deal of network traffic because it has to either gather or replicate data across the infrastructure in order to achieve either availability or performance. In both scenarios, network latency and throughput severely impact the performance of the overall setup. Paying for blazing fast in-memory DB technology and hosting it within a poor performance network is just a very difficult way to throw away money.
Considering this, do try to avoid software switching in distributed systems. Recent studies by VMware show that VMs will only get up to 30 Gbps connectivity, which is 10 Gbps less than what we have achieved with bare metal. Those tens of microseconds really add up when billions of files are being transferred. Even in the case of bare metal switching, favor cut-through over store-and-forward. In the case of the latter, the memory buffer can become a bottleneck.
-
Avoid virtualization with NoSQL databases
Virtualization can be great. It provides the flexibility to use a single machine for multiple purposes, with reasonable security for non-critical business data. Unfortunately, it also influences memory access speed, which is critical for some NoSQL databases. Depending on the hypervisor and the underlying hardware capabilities, it can add 20-200% penalty in accessing memory for NoSQL workloads. I have witnessed this in testing, and it is also documented by a number of industry benchmarks. Newer generation hardware helps with better support for hardware assisted memory management unit (MMU), but there is still a significant impact for workloads that generate a lot of Translation Lookaside Buffer (TLB) misses (as NoSQL databases are wont to do).
In the case of virtualized public clouds, the noisy neighbor effect as well as hardware overselling should also be key considerations. It’s not only because of the hypervisor that we’re seeing up to 400% performance gains from bare metal clouds compared to virtualized ones.
Most big data software vendors, such as Datastax and Splunk, already openly recommend bare metal in their documentation, but as the public cloud grows, this point is still worth stressing.
Conclusion
As you might have noticed, most of these findings could be summarized as “Don’t trust assumptions — just test, test, test!” We are all busy, and it’s easy to brush off live testing in favor of online research or documentation review. The truth is, though, that every setup is different, and until you get your hands dirty, it will be very hard to predict the actual throughput you’ll get from a system.
Also, don’t forget that no matter how fast and scalable the software, the quality of each and every component in your underlying hardware matters. You might invest in expensive SSD drives and then find your drive controller doesn’t have enough bandwidth to utilize that performance. You might be ready to increase your expense by 30% to get more compute power when you might just need to tweak the BIOS settings on your machines.
Try to view testing projects as an investment that will save you time in the long run, always challenge safe assumptions, and share what you learn with the rest of us whenever possible.
Cropped image on article and category pages by John Lester on Flickr, used under a Creative Commons license.
Related: