
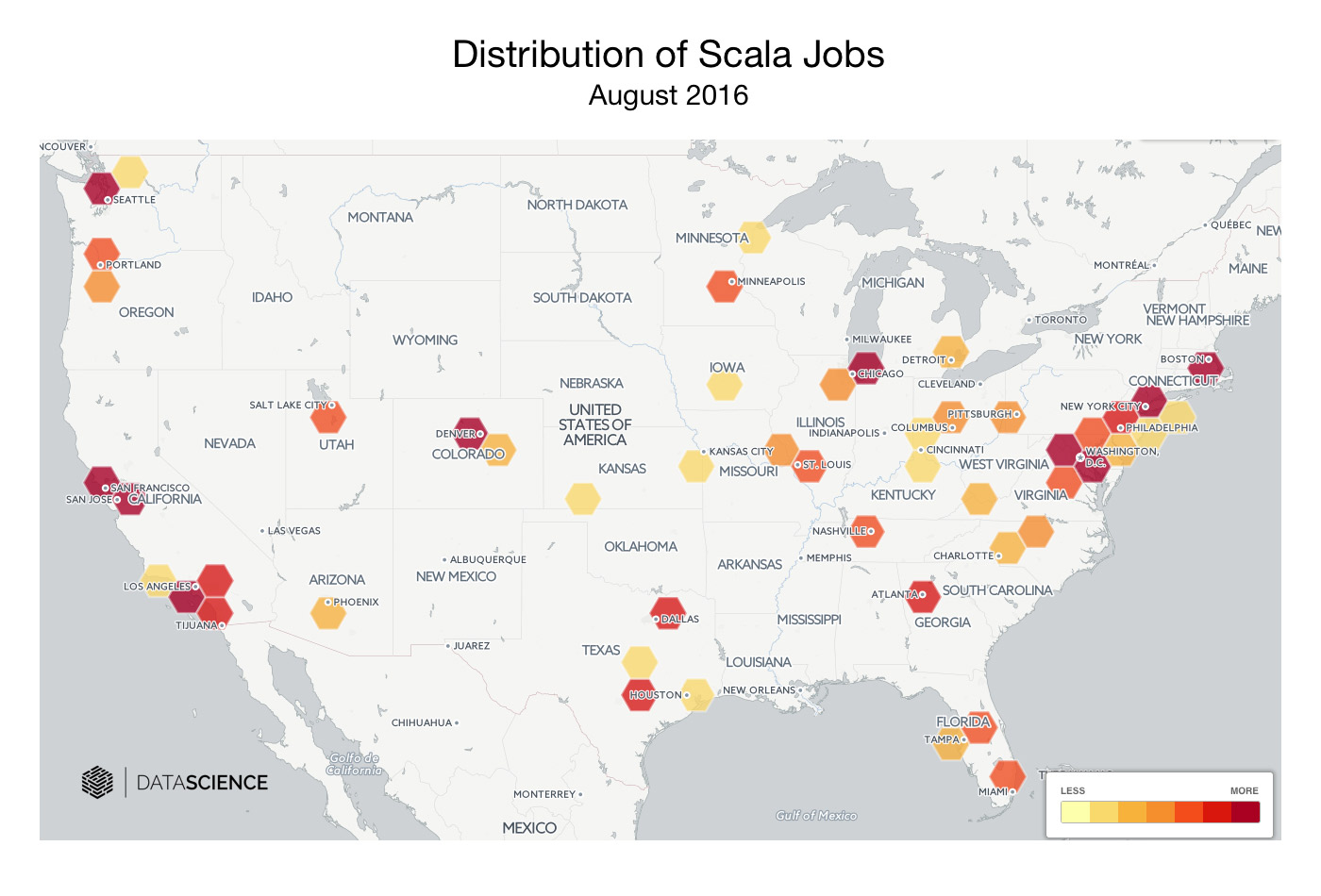
 Distribution of Scala jobs. (source: DataScience)
Distribution of Scala jobs. (source: DataScience) Earlier this year, I was building out a data engineering team and had to pick a programming language. Scala seemed like a good choice—we were going to be interacting with Spark quite a bit—but there were a few things that gave me pause. I read through a number of opinions on the subject and came away none the wiser. Everything I read was either obviously biased, five years old, or both. I’m writing this with the hope that it will help anyone in a similar position, clarify and evaluate the value of Scala for data science and engineering teams.
In this article, I’ll discuss the state of several major components of the Scala ecosystem from both a data, and people perspective. I pulled time series data from GitHub to help inform the analysis, and tried to address some of the common concerns I’ve seen. I also reached out to several of the leaders in the Scala community for comment, including Martin Odersky. They were all generous with their time and happy to share their views.
I’ve tried to present things fairly, but I should issue a disclaimer that this overview is from my personal perspective. I haven’t made any notable open source contributions to the ecosystem, and prior to Scala, I was writing mostly Haskell. I have recruited and trained a six-person team successfully using purely functional Scala at DataScience Inc., a Los Angeles-based data science platform company.
Proprietary Java and the rise of the SMACK stack
Scala is highly dependant on the Java ecosystem. And perhaps the single most important event of the past year for Java was Oracle’s lawsuit against Google. The Java ecosystem and the industry at large have been agog at the prospect that licenses might be required just to create a compatible implementation of an API. Despite Google’s win on fair-use grounds, the central issue has not been resolved due to the disappointing Federal Circuit court decision on API copyright.
The larger issue for Java is Oracle’s proprietary stranglehold on the language and the associated lack of stewardship. Java has evolved slowly over the past decade (there was a five-year gap between Java 6 and Java 7) to the point where there’s even a petition to Larry Ellison to “move forward Java EE as a critical part of the global IT industry.” As a result, Java has begun to lose market share to newer open source languages like Scala in certain application areas. According to aggregated data from Indeed.com, job postings for Scala have increased from 2012 to 2016 by more than 500%, while the postings for Java over the same period have decreased by 33%.
Early signs of this trend can perhaps be seen most clearly in the distributed data processing space with the emergence of the SMACK stack (Spark, Mesos, Akka, Cassandra, Kafka), most of which has been written in Scala. Scala emerged as the right language, at the right time, in which to write Spark—and Spark is now helping to drive adoption of Scala. Syntactically, Spark is almost identical to the Scala collections API, and using it feels like a force multiplier.
In addition to Scala, the growing importance of data-centric applications and composable concurrency primitives have driven interest in a wide range of functional programming languages such as Clojure, Erlang, and Haskell.
Streaming, microservices, and Scala
Scala’s importance in the broader trend of streaming data and microservices is clear as well: of the respondents to Lightbend’s recent survey of 2,151 global JVM developers, 50% more Scala devs were running microservices in production than Java devs. Of all developers running microservices in production, 35% used Akka Streams, 30% used Kafka, and 19% used Spark Streaming.
I compared Akka, Kafka, and Spark by pulling daily time series data from their respective GitHub repositories. I looked at three separate time series: total new watchers, pull requests (PRs) opened, and commits. In each case, the data are from the three-year span beginning 09/30/13 and ending 09/30/16. The time series are smoothed with a two-week moving average for readability. The queries for this article were conducted on the open source GitHub archive using Google’s BigQuery SQL interface. The source code for all of the queries in this post can be found here.
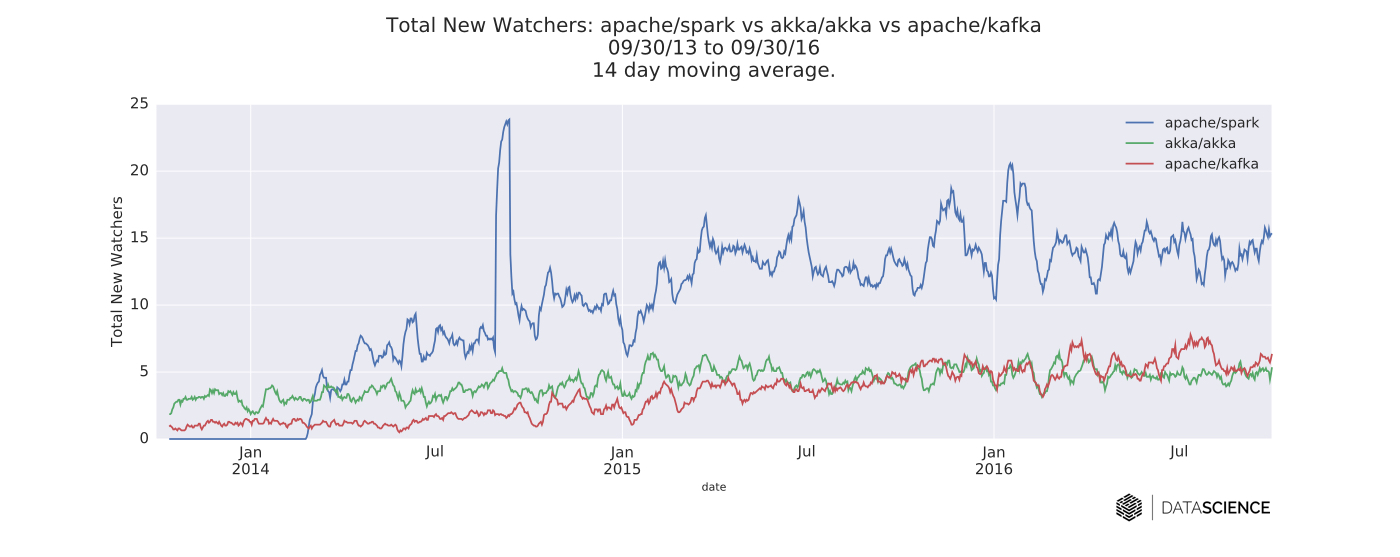
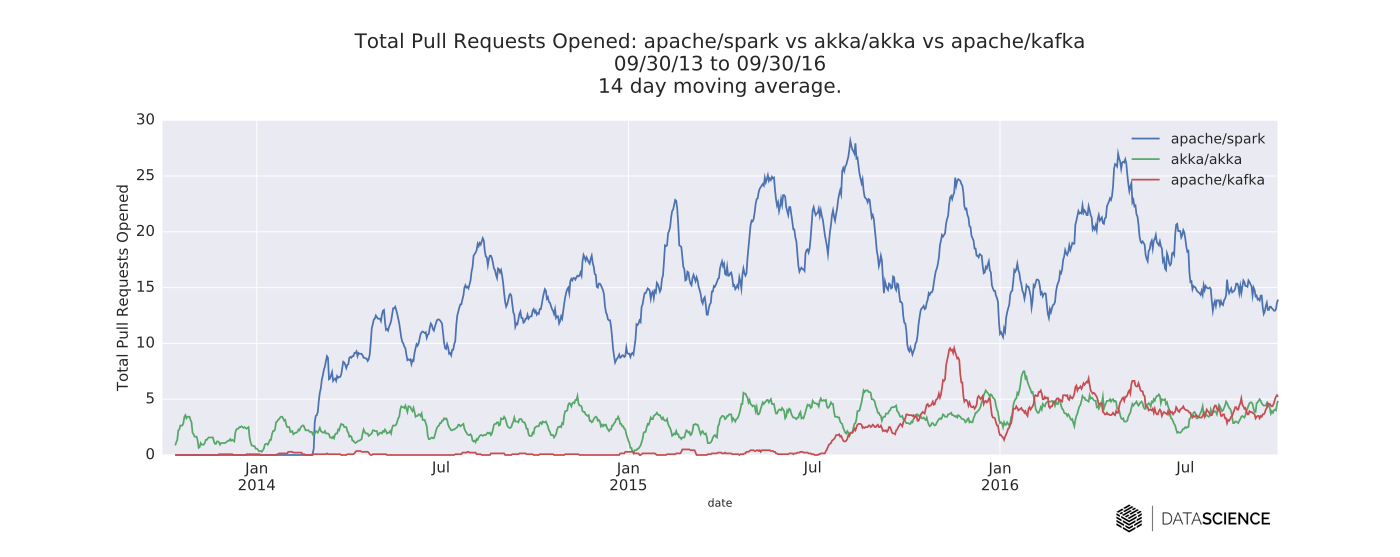
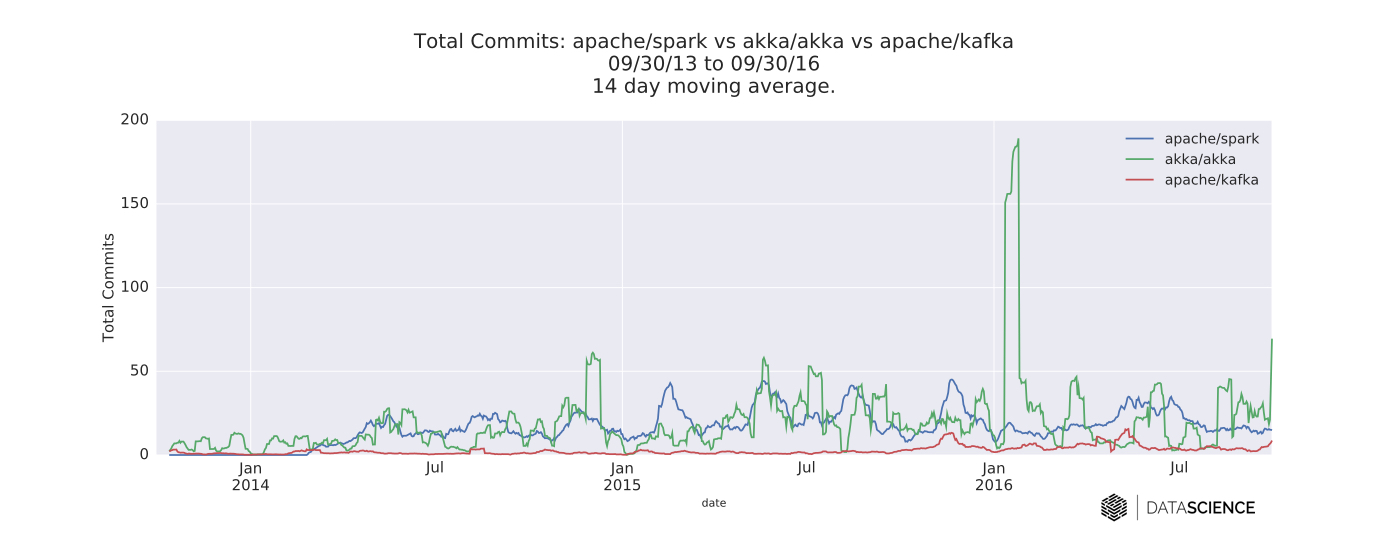
Spark and Kafka development
Spark is evidently the most active project in terms of watchers and PRs. This shouldn’t come as much of a surprise. It remains the most active open source project within the data community, with a 67% increase in the number of contributors to the code base from 2015 to 2016. Scala continues to be the language of choice for Spark, with Python a close second.
Kafka also appears to have caught up to Akka in terms of PRs. It’s also worth noting here that some development has shifted to Java as Confluent has taken over maintenance of Kafka. Kafka, in particular, is oriented around streaming data as a replacement for batch ETL systems.
In addition, Kafka allows you to build a distributed system with at-least or even exactly-once delivery guarantees out of the box. Moreover, you can send binary data that remains strongly typed (e.g., in Avro), and if you use a strongly typed language like Scala you will preserve all the guarantees that the type system gives you. This sharply contrasts with a JSON dump, which you would need to parse all over again. (Consuming and producing JSON data is a major source of boilerplate in batch ETL systems.)
It seems that many of the new adopters of Kafka are startups like DataScience, using it as scalable plumbing for microservices. Confluent’s thinking seems to mirror this, as explained by Jay Kreps in a blog post earlier this year.
Several other interesting points in this analysis:
Bumps in the number of pull requests opened per day for Spark correspond to the period before each release date.
There is a large spike in commits to Akka in January 2016 (2,008 commits in total). This looks like some major house cleaning—maintainers merging a lot of commits on Akka Streams and HTTP into the master branch.
This isn’t an apples-to-apples comparison, of course. All three libraries are multifaceted. Spark, in particular, is a cross-functional framework that, in addition to streaming, includes an in-memory distributed computation engine as well as data frame, graph computation, and machine learning libraries.
Dotty—a new industry standard?
Martin Odersky has been leading work on Dotty, a novel research compiler based on the Dependent Object Types (DOT) calculus (basically a simplified version of Scala) and ideas from the functional programming (FP) database community.
The team working on Dotty development has shown some remarkable improvements over the state of the art, most notably with respect to compilation times. I asked Odersky what he thought was novel about the Dotty architecture and would help end users. Here’s what he said:
Two things come to mind: first, it’s closely related to formal foundations, giving us better guidance on how to design a sound typesystem. This will lead to fewer surprises for users down the road. Second, it has an essentially functional architecture. This makes it easier to extend, easier to get correct, and will lead to more robust APIs where the compiler is used as a service for IDEs and meta programming.
Although Dotty opens up a number of interesting language possibilities (notably full-spectrum dependent types, a la Agda and Idris), Odersky has chosen to prioritize making it immediately useful to the community. Language differences are fairly small, and most of them are in order to either simplify the language (like removing procedure syntax) or fix bugs (unsound pattern matching) or both (early initializers).
It’s interesting to note that Odersky actually has a long history of building compilers that people use. Before he finished his Ph.D., he sold a Pascal compiler to Borland. He finished his Ph.D. under Niklaus Wirth (the creator of Pascal), did some post-doc work at IBM (on E-language, which was later commercialized), then caught the functional programming (FP) bug. He went on to write Pizza (with Philip Wadler of Haskell and Java Generics fame) and Funnel. Nobody uses those, but his work with Wadler led to the GJ compiler, which, of course, led to Java Generics. He’s also written multiple Scala compilers (Dotty is the fifth or sixth). I’m probably missing stuff here, but the point is that he’s pretty trustworthy.
Still, I couldn’t resist asking him if there is any chance of full-spectrum dependent types ending up in Scala at some point. Here is what he said:
Never say never :-). In fact, we are currently working with Viktor Kuncak on integrating the Leon program prover with Scala, which demands richer dependent types than we have now. But it’s currently strictly research, with a completely open outcome.
The Scala and Dotty teams are working closely toward convergence for Scala 2.x and Dotty, and they’ve indicated that they take continuity very seriously. Scala 2.12 and 2.13 have language flags that unlock features being incubated in Dotty (e.g., existential types), and the Dotty compiler has a Scala 2 compatibility mode. There’s even a migration tool.
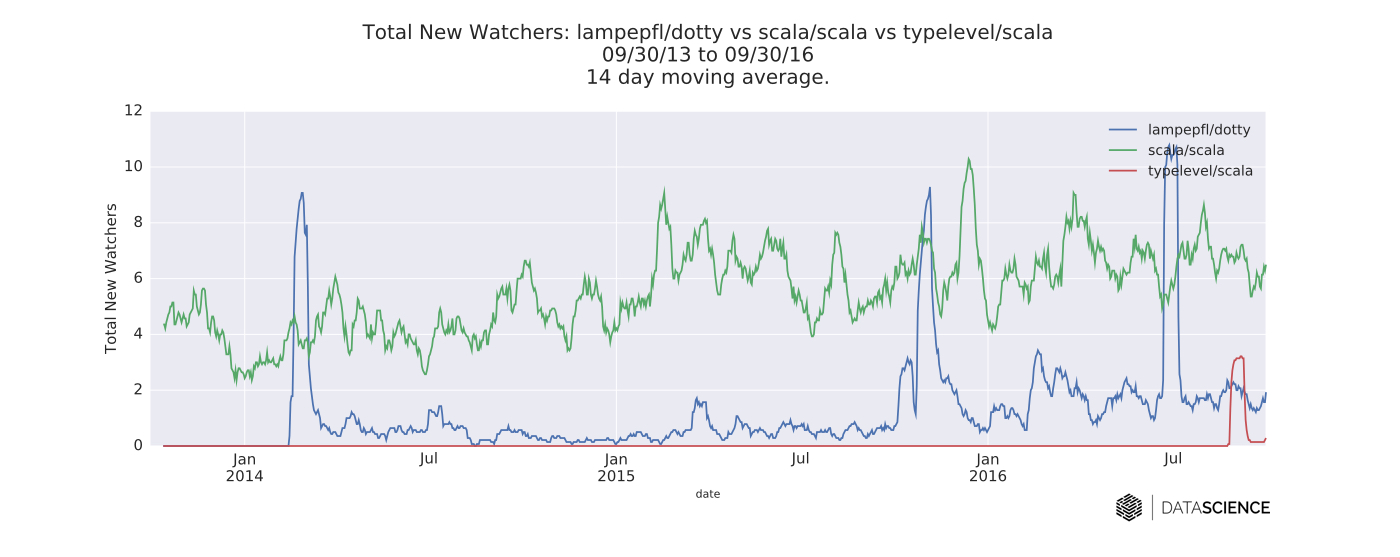
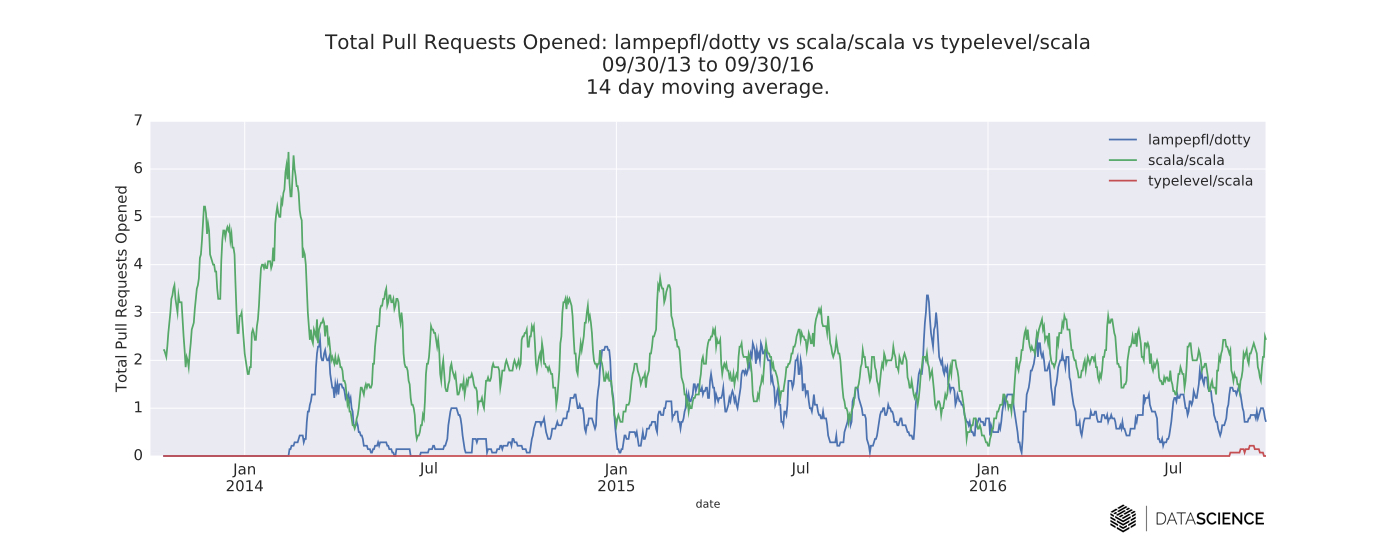
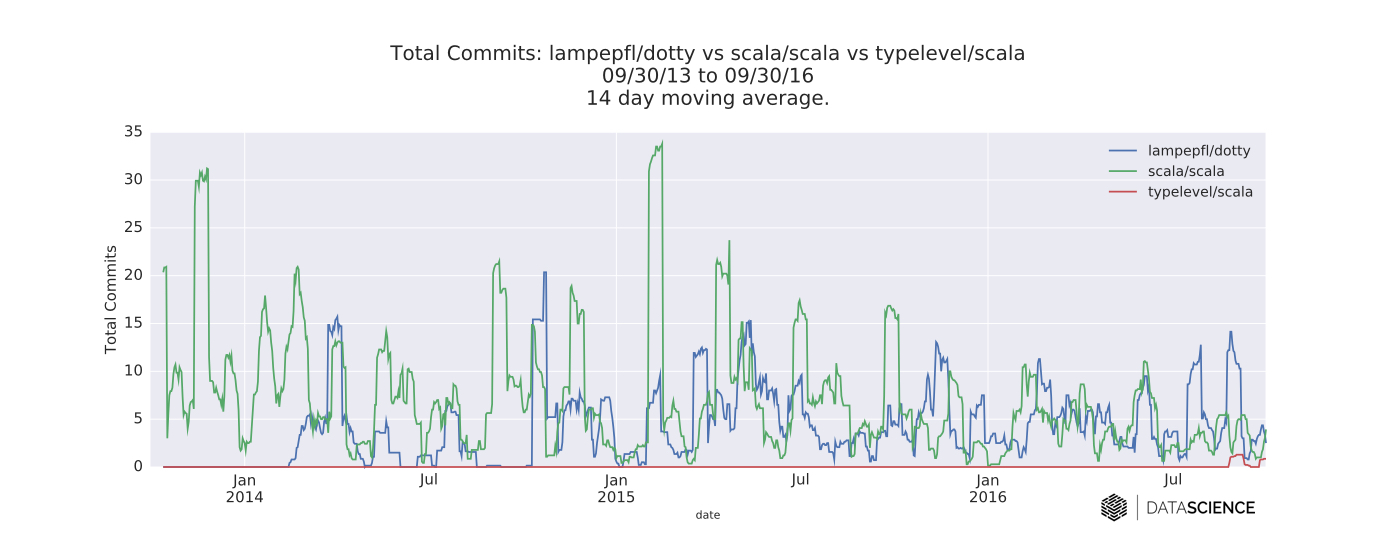
I also compared the two compilers (along with Typelevel’s fork) by analyzing time series data from their respective GitHub repositories. In general, the new watchers (most likely from the Dotty announcement and Hacker News posts here and here) are perhaps the most interesting things about these time series.
Lightbend is the Scala support and PLAY reactive JVM framework company that was founded by Odersky, former poker champion and software engineer Paul Phillips, and Akka creator Jonas Bonér. The company was initially named “Typesafe” to reflect its functional programming roots, and pivoted to “Lightbend” in February 2016. I spoke with Mark Brewer, CEO of Lightbend, about the company’s work on Scala, and this is what he said:
Scala 2.12 has been a significant investment for Lightbend and the many outside contributors. The back end has been completely rewritten to take advantage of features in Java 8 (so translations of Scala to Java don’t have to take place when it is compiled down to Java byte code). Additionally, 2.12 brings in a new optimizer that performs much deeper static analysis to eliminate the overhead of higher order code patterns common in functional programming. Now that 2.12 is in a final (hopefully) release candidate, the team is beginning on 2.13 work. The 2.13 feature set is still being defined, but it will include a new collections library (which the community has been asking for) and other features that come from Dotty.
Lightbend’s work on the 2.12 release, in particular, demonstrates the extent to which it has been responsive to the FP community’s needs and input.
Finally, it is interesting to note that with Dotty getting closer to being able to compile large portions of the main Scala ecosystem, the prospect of significant savings in development cycle times has caused a number of companies to come forward and express interest in moving to it as soon as possible. It will be interesting to see what happens when Dotty achieves functional parity with scalac.
Codes of conduct wars
Scala is a multi-paradigm language, and its community is certainly a reflection of that. Martin Odersky’s original goal with Scala was to prove that functional code could be organized according to object-oriented principles. This design thesis has led to significant adoption by converts from pure functional programming (FP) languages (e.g. Haskell) in addition to the large numbers of Java converts drawn by the projects listed above.
A community divided: Cats and Scalaz
Historically, the Scala FP community was represented by Scalaz, which is still one of the most starred Scala libraries on GitHub. There is and has always been a sizable pool of expat Haskell developers working on Scalaz; since its inception, the community has been somewhat polarizing in its full-throated advocacy of porting Haskell-like FP patterns, syntax, etc., to Scala.
In late 2014, after the failed introduction of a new Code of Conduct (CoC), the community began to fracture, as seen in this Tweet from Edward Kmett.
The Typelevel folks did, in fact, leave to create a new FP library (Cats), which, although not a direct fork of Scalaz, uses many of the same concepts and is more or less a direct competitor.
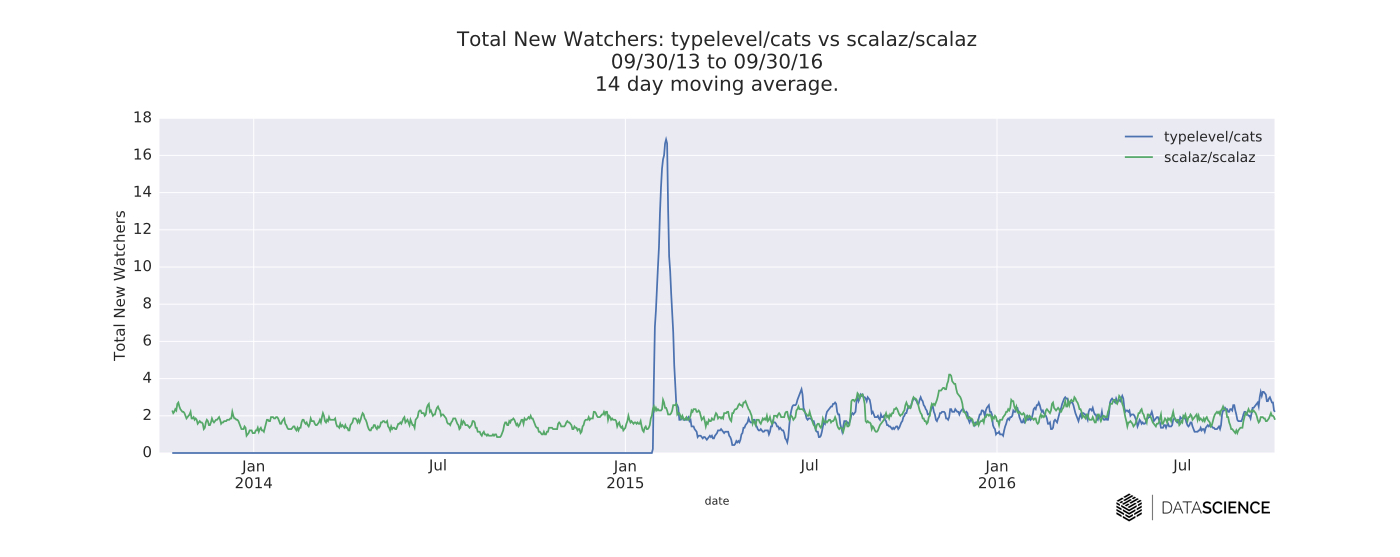

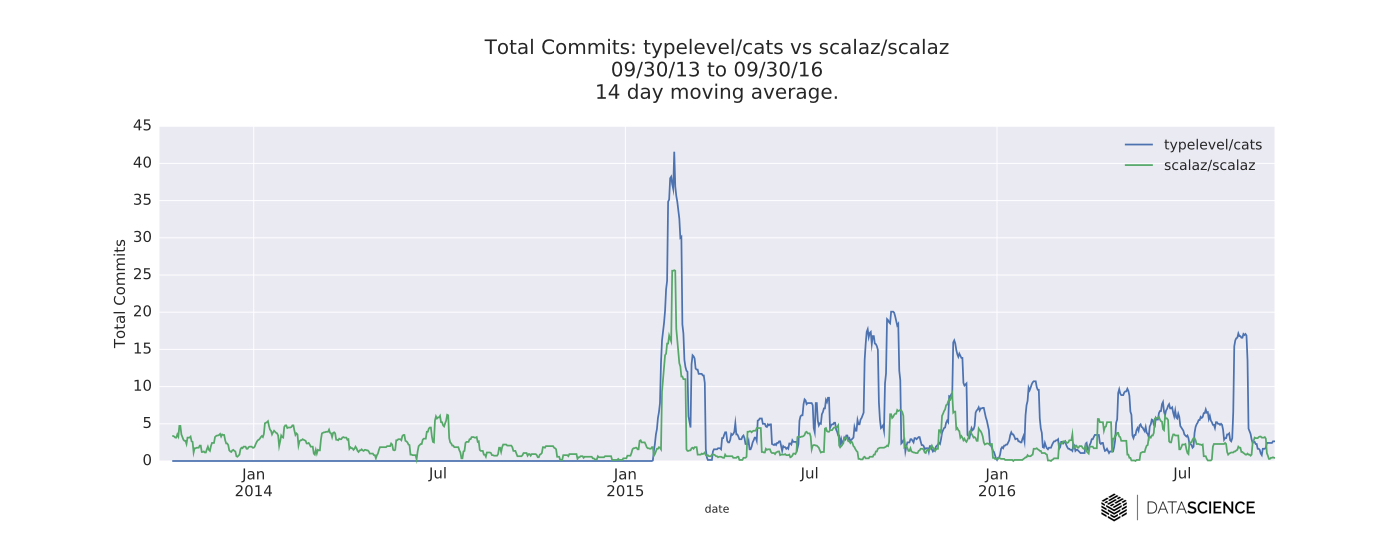
The overall magnitude of pull request activity metrics are larger for Cats than Scalaz, though some of this may be due to the age of the library. However, in terms of commits per day and new watchers per day, there appears to be no significant decrease over time for Scalaz. So, it would seem that the fears of some in the community have come to pass. Indeed, the existence of both Scalaz and Cats has caused numerous headaches for downstream libraries, though most seem to have found workable solutions, either through including all necessary FP dependencies (as FS2 and scodec have done), or abstracting them through shims or source-code-level preprocessing.
On the other hand, perhaps Tony Morris was correct in saying that the Scalaz project is quite different from Cats in terms of motivation, and that ultimately there is room for both libraries to continue to evolve and serve different needs within the Scala community. Cats has striven to remain lightweight and modular (see here and here) as well as eschew some of the more inscrutable syntax of Scalaz.
Free speech vs. non-violent communication
The proximal reason that the Scalaz CoC failed was that the first person to be banned as a result of its introduction happened to be the project’s founder. However, the larger reason might have been that the CoC was imposed on a seven-year-old community rather than introduced as an initial condition. Changing the modes of group discourse in this fashion is arguably tantamount to asking participants to join an entirely separate movement. The two most likely outcomes are flat-out rejection of the CoC, or (this is what happened with Scala-internals) the CoC is just ignored and the constant negativity drags forum activity to a near halt.
The main fault line that the Scalaz drama exposed (the same issue just came up again recently on the Scala-debate forum) is a philosophical disagreement over codes of conduct in open source software development. One side feels that ideas are tantamount, and how those ideas may be communicated is of lesser importance (this debate came to a head at LambdaConf this year). This side feels that it is not acceptable to ignore criticism simply because it was conveyed in a rude or insulting fashion.
The other side feels that violent communication drags the entire community down, and therefore notions of acceptable communication should be circumscribed by a CoC. I can say from personal experience that my interactions with the Typelevel crew have been incredibly positive—the same goes for everyone on my team. Typelevel’s patience for newcomers has been instrumental in our adoption of their projects, Cats in particular.
Should you use Scala? Debunking some FUD
Like any mainstream language, Scala has attracted its fair share of pundits, and the concomitant “Scala is Awesome” (I’m guilty), and “Scala is Dead” pieces (like this recent one, apparently by a Java developer). If you are considering learning Scala or hiring a Scala team, you should consider both sides and judge them for yourself, but in the interests of debunking some obvious FUD, I’d like to address several of the most common concerns (there is a nice discussion of several other concerns here).
1. Concerns about the Typesafe name change and Scala stewardship
For the less familiar, in February, Scala’s “parent company” Typesafe changed its name to Lightbend. This concern seems overblown to me. Lightbend CEO Mark Brewer made it clear in a followup blog post that Lightbend has a continued commitment to the language and the community around Scala. When I mentioned the lingering concerns to Brewer, he replied:
We are fortunate to have a very engaging (and vocal) community around Scala, which frequently means that opinions on what Lightbend is doing get a significant amount of coverage. No complaints though—we’d much rather have that than no engagement.
2. Concerns about developer onboarding
This concern is somewhat well founded. Scala has a steeper learning curve than many other languages, and the lack of centralized onboarding materials and community forums (like Rust has, for example) is an ongoing issue. In March of this year, EPFL announced the establishment of an open source foundation for Scala called the Scala Center (backed by Lightbend, IBM, Verizon, and several others).
3. The need for improved documentation
Hopefully, the introduction of the Scala Center will also include more documentation efforts. I spoke with Heather Miller, executive director of the Scala Center, about documentation and this is what she said:
Personally, I’ve long held documentation to be a concern that a company should hire a technical writer to address. As the person who personally wrote most of the base Scala documentation that’s out there, I’ve been quite passionate for about five years now that this should not be a volunteer task. However, due to how the Scala Center is governed, it is not my personal decision alone to make whether or not Scala Center funds should be allocated to hire a professional writer to improve documentation. This is something that needs to be proposed, discussed, and voted on at the upcoming advisory board meeting before I can take action hiring.
The Scala Center has 3.5 full-time employees, and as part of EPFL, they are under fairly strict hiring constraints (employees must be part of a federal university, salaries are not competitive, etc.). The center listens to suggestions from individuals, companies, and advisory board members every week on unofficial channels. These recommendations are distilled into proposals and submitted every three months at advisory board meetings. The advisory board then votes on these proposals, taking into consideration the most pressing concerns of all stakeholders involved. The center then basically does its best with the people they have on staff to complete the work proposed.
4. Concerns about Scala community processes
This concern is also somewhat well founded. In addition to (and somewhat connected to) the Scalaz episode, there has been an increase in people complaining about trolling and a concomitant drop off in forum participation. Miller says she’s been approached by a number of people, most often women, who feel, as she puts it:
Not just intimidated, but also sometimes degraded, or they see people degrading one another and it turns them off from even participating. They feel it’s a hostile environment, more so than other communities they’ve participated in.
Thus far, the Scala Center’s focus has been on projects like easing Scala/Dotty migration and improving high-level governance (they recently rebooted the Scala improvement process). They are now gearing up for a major announcement regarding a new Scala platform process and an associated library restructuring.
5. Concerns about hiring Scala developers
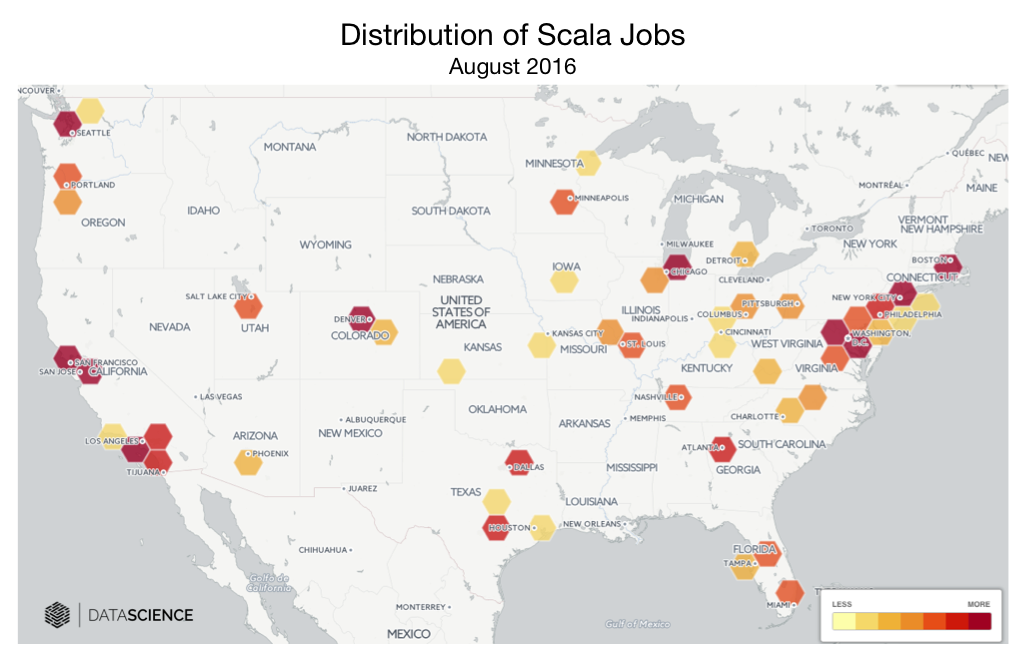
This concern is very well founded. If you anticipate the need to grow a very large team or to grow a team quickly, Scala may not be the language for you. Scala developers also tend to be in high demand relative to other mainstream functional languages.
Expertise is somewhat well distributed—there are big pools of people working in it in the major tech hubs, and smaller pools scattered throughout the country. However, outside of the Bay Area, LA, New York, and Seattle, you will most likely need to be comfortable with remote teams. Experienced Scala developers are also well aware of their own worth; while it’s possible to hire a few senior Scala developers, it may not be simple or cost effective to fill your entire team with mature Scala talent. This is at odds with the standard Java strategy of building a developer team by hiring from the massive pool of mature talent.
Growing a language
The Scala community has never been more productive. We’re also seeing a gradual industry shift toward functional programming, which, given the complexity increases in other parts of the modern technology stack, is probably a good thing. Scala has found a definite niche in distributed data processing and is now driving mainstream adoption of functional techniques. In this respect, it has benefitted enormously from a passionate functional programming community.
I don’t think most of the Scala community wants to see Scala go “full enterprise,” however. Amongst the people I spoke with, there is a consensus that a Java-like track would be unhealthy. Java achieving total dominance and then stagnating for a decade has not been a good thing for programming. So, continue to experiment and strive for organic growth. Resist early standardization, and simplify instead of piling up language extensions. Clarify and edit, as understanding grows, and iterate toward a closer approximation of the mutable and unattainable optimum.
Thanks to Janie Chen and Dave Goodsmith for their help with this post.