Stream processing and mining just got more interesting
A general purpose stream processing framework from the team behind Kafka and new techniques for computing approximate quantiles.
Largely unknown outside data engineering circles, Apache Kafka is one of the more popular open source, distributed computing projects. Many data engineers I speak with either already use it or are planning to do so. It is a distributed message broker used to store1 and send data streams. Kafka was developed by Linkedin were it remains a vital component of their Big Data ecosystem: many critical online and offline data flows rely on feeds supplied by Kafka servers.
Apache Samza: a distributed stream processing framework

Learn faster. Dig deeper. See farther.
Behind Kafka’s success as an open source project is a team of savvy engineers who have spent2 the last three years making it a rock solid system. The developers behind Kafka realized early on that it was best to place the bulk of data processing (i.e., stream processing) in another system. Armed with specific use cases, work on Samza proceeded in earnest about a year ago. So while they examined existing streaming frameworks (such as Storm, S4, Spark Streaming), Linkedin engineers wanted a system that better fit their needs3 and requirements:
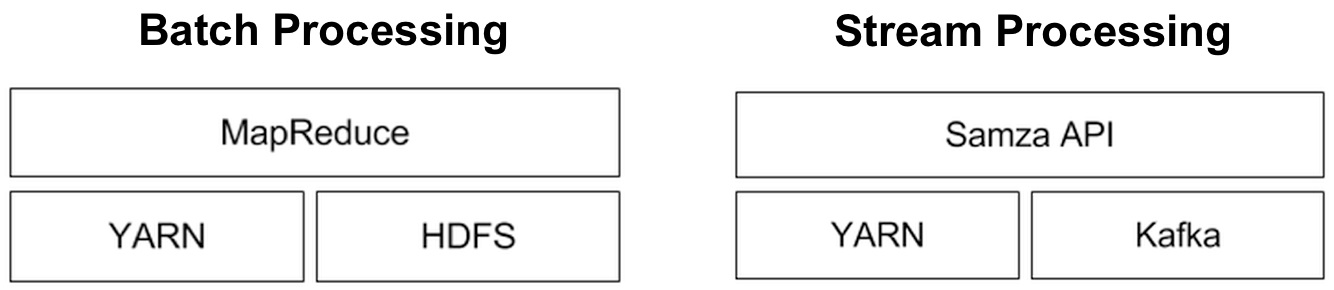
Just as MapReduce requires a data source (in most cases HDFS), a general purpose data processing system like Samza requires a source of streams. Out of the box, Samza uses YARN as its fault-tolerant, distributed execution system, and Kafka as its messaging system. But Samza is pluggable and can be used with other systems – there is already interest in making Samza work with other execution systems (AWS, Mesos).
Stream Mining and near realtime computations
For now Samza users who need to do stream mining have to write code4 (common problems include finding the “top k”, “distinct elements”, “heavy hitters”, quantiles, moments). However as a general purpose stream processing framework it can be used for a broad set of problems: simple “counts”, approximate answers (“sketches”), and more advanced algorithms. Data scientists will also like the fact that Samza (and Kafka) can easily reprocess data, a useful feature when new algorithms need to be deployed or existing ones have to tweaked.
Within Linkedin, Samza occupies the space between batch (Hadoop jobs that run for a few hours) and online systems (milliseconds). By supporting tasks that take a few seconds to a few minutes to run, Samza is potentially useful for a variety of user services such as periodic updates of rankings and recommendations. I expect Samza to attract interest from developers who are already using Kafka. As I pointed out in a recent post, integrated systems are attracting attention (as convenience and familiarity, outweigh performance). Furthermore, as interfaces and dedicated libraries emerge, Samza will become useful to many more data scientists.
Frugal Streaming, Approximate Quantiles and Histograms
Speaking of approximate answers, I thought I’d highlight a couple of recent posts that relate to streaming and realtime analytics. The first explains simple algorithms (Frugal-1U and Frugal-2U) for computing approximate quantiles in streaming data. The second uses Druid to approximate quantiles and build histograms (in near realtime) for large data sets. As data volume and velocity continue to rise5, I expect systems that produce approximate answers to become more common.
Related posts:
- Running batch and long-running, highly available service jobs on the same cluster
- Near realtime, streaming, and perpetual analytics
- Interactive Big Data analysis using approximate answers
- Scalable streaming analytics using a single-server
(0) Thanks to Chris Riccomini and Jay Kreps of Linkedin for walking me through the details of Samza.
(1) Kafka retains published messages for a configurable amount of time – during which period one can resend and reprocess them accordingly.
(2) Here’s an interesting bit to illustrate how much work has gone into Kafka: just getting replication right took 5 experienced developers a year! While the bulk of Kafka development still happens within Linkedin, about 30% comes from external developers.
(3) Stateful processing is particularly important to Linkedin: “We are not aware of any state management facilities in Storm …”
(4) Pushing the MapReduce analogy further, at some point a simpler system (a la Pig, Hive, SQL) may make it easier to use Samza. One of the things that makes Spark Streaming attractive is its programming interface: the same (concise) code that works for batch jobs (Spark), will work (with minor changes) for stream processing.
(5) The “real-time big data triangle of constraints” posits that you can have only two of the following: volume, velocity, exact.