

Why do data scientists spend so much time on data wrangling and data preparation? In many cases it’s because they want access to the best variables with which to build their models. These variables are known as features in machine-learning parlance. For many0 data applications, feature engineering and feature selection are just as (if not more important) than choice of algorithm:
Good features allow a simple model to beat a complex model. (to paraphrase Alon Halevy, Peter Norvig, and Fernando Pereira)
The terminology can be a bit confusing, but to put things in context one can simplify the data science pipeline to highlight the importance of features:
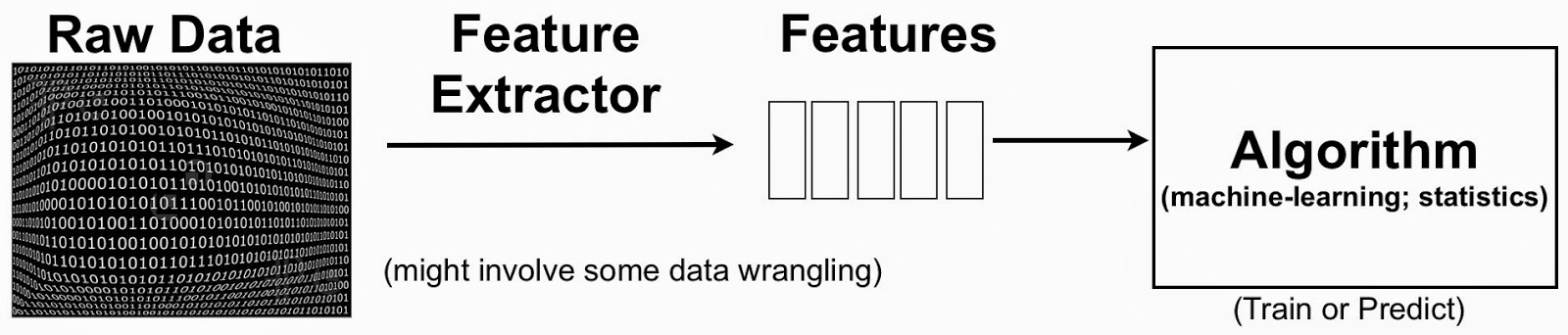
Feature engineering or the creation of new features
A simple example to keep in mind is text mining. One starts with raw text (documents) and extracted features could be individual words or phrases. In this setting, a feature could indicate the frequency of a specific word or phrase. Features1 are then used to classify and cluster documents, or extract topics associated with the raw text. The process usually involves the creation2 of new features (feature engineering) and identifying the most essential ones (feature selection).
Feature selection techniques
Why bother selecting features? Why not use all available features? Part of the answer could be that you need a solution that is simple, interpretable, and fast. This favors features that have good statistical performance and that are easy to explain to non-technical users. But there could be legal3 reasons for excluding certain features as well (e.g., the use of credit scores is discriminatory in certain situations).
In the machine-learning literature there are three commonly used methods for feature selection:
- Domain experts can manually pick out features, and more recently I wrote about a service that uses crowdsourcing techniques. It’s not hard to find examples of problems where domain expertise is insufficient, and this approach isn’t particularly practical when underlying data sets are massive.
- There are variable ranking procedures that use metrics like correlation, information criteria, etc. They scale to large data sets but can easily lead to strange recommendations (e.g., use “butter production in Bangladesh” to predict the S&P 500).
- Techniques that take a vast feature space and reduce it to a lower-dimensional one (clustering, principal component analysis, matrix factorization).
Expect more tools to streamline feature Discovery
In practice, feature selection and feature engineering are iterative processes where humans leverage automation4 to wade through candidate features. Statistical software have long had (stepwise) procedures for feature selection. New startups are providing similar tools: Skytree’s new user interface lets business users automate feature selection.
I’m definitely noticing much more interest from researchers and startups. A group out of Stanford5 just released a paper on a new R language extension and execution framework designed for feature selection. Their R extension enables data analysts to incorporate feature selection using high-level constructs that form a domain specific language. Some startups like ContextRelevant and SparkBeyond6, are working to provide users with tools that simplify feature engineering and selection. In some instances this includes incorporating features derived from external data sources. Users of SparkBeyond are able to incorporate the company’s knowledge databases (Wikipedia, OpenStreeMap, Github, etc.) to enrich their own data sources.
While many startups who build analytic tools begin by focusing on algorithms, many products will soon begin highlighting how they handle feature selection and discovery. There are many reasons why there will be more emphasis on features: interpretability (this includes finding actionable features that drive model performance), big data (companies have many more data sources to draw upon), and an appreciation of data pipelines (algorithms are just one component).
Building tools that automate feature discovery is an important topic in artificial engineering research. For more on recent trends in AI, check out our new series, Intelligence Matters.
Related content:
- Crowdsourcing Feature discovery
- Data Analysis: Just one component of the Data Science workflow
- Data Wrangling gets a fresh look
- Emotional AI: The Human Side of Machine Learning
(0) The quote from Alon Halevy, Peter Norvig, and Fernando Pereira is associated with big data. But features are just as important in small data problems. Read through the Kaggle blog and you quickly realize that winning entries spend a lot of their time on feature engineering.
(1) In the process documents usually get converted into structures that algorithms can handle (vectors).
(2) Once can for example create composite (e.g. linear combination) features out of existing ones.
(3) From Materialization Optimizations for Feature Selection Workloads: “Using credit score as a feature is considered a discriminatory practice by the insurance commissions in both California and Massachusetts.”
(4) Stepwise procedures in statistical regression is a familiar example.
(5) The Stanford research team designed their feature selection tool after talking to data analysts at several companies. The goal of their project was to increase analyst productivity.
(6) Full disclosure: I’m an advisor to SparkBeyond.