
 A return from a march or a false alarm in a country village. (source: Wikimedia Commons)
A return from a march or a false alarm in a country village. (source: Wikimedia Commons) Here’s a familiar setting for data scientists and engineers working in data security: your company has invested in a security information and event management (SIEM) system with the hope of surfacing blazing-fast alerts through out-of-the-box security detection systems. However, your on-call security engineers are being inundated with many false alerts. What do you do?
This post explores how and why security detection systems fail, and how you can prevent these false alerts, also known as false positives. We will get to the bottom of why false positives can greatly limit intrusion detection systems by exploring false positives from the angle of base rate fallacy. At the end of this post, you’ll understand:
1. How, in the era of big data analytics, even with a small false positive rate, the chances of catching an attacker is as probable as getting struck by lightning.
2. In order to increase the chances of detection, you can:
- Improve logging fidelity
- Decrease false positives by using fine-tuned detections
As a reference for our discussion, we will re-visit one of the classic academic papers by Stefan Axelsson on the detrimental effects of false positives in security.
Introducing base rate fallacy
To help explain base rate fallacy, let’s imagine a scenario in which a drugstore pharmacist claims that a generic test for malaria is accurate 99% of the time. He claims that if you take this test, and it turns out positive (i.e. the test indicates that you have malaria), this means that your chances of being infected are 99%.
This of course is wrong. The efficacy of the test has nothing to do with your chances of being infected. In fact, this is a classic example of confusing how we interpret conditional probability. We assume, incorrectly, that the probability of an alert being triggered is the same as having an intrusion.
Let us assume that the probability of getting sick with malaria is so rare that only one in 10,000 people are infected. In our example, when the pharmacist says that the test for malaria is 99% accurate, what he is really saying is that, assuming that you are sick, the probability that the test is positive is 99%, or 0.99. We’ll represent this as P(P|S) = 0.99 (read as: given that you are (S)ick, the (P)robability of the test being (P)ositive equals 0.99).
Now, what you are really interested in is, given that the test is positive, what is the probability that you are sick — P(S|P). We can solve this using Bayes’ formula: (here “-S” refers to not sick):
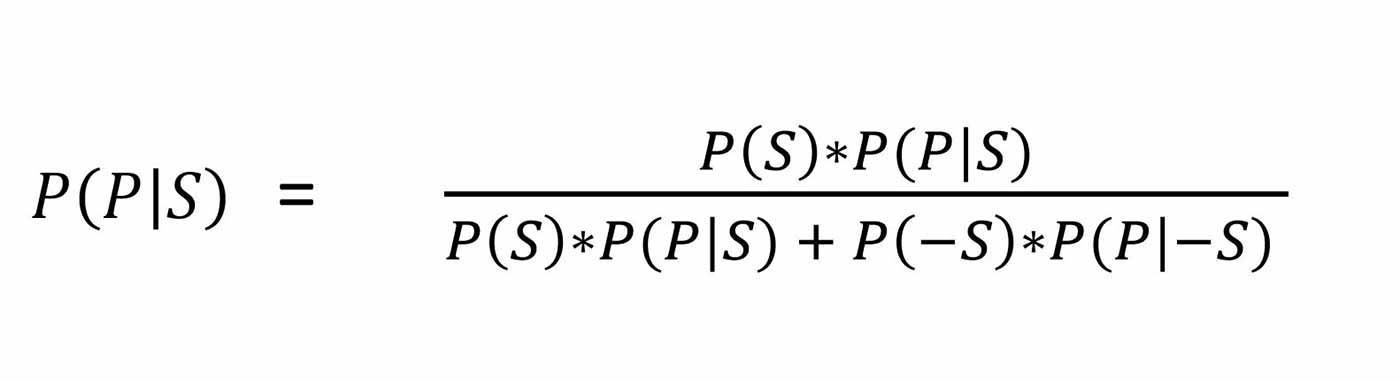
To solve this problem using Bayes’ Formula, we only need to calculate P(-S), for which we use Rules of Probability, P(-S) = 1 – P(S) = 1 – 1/10,000. Now, we have all of the values, and are ready to plug the numbers into our equation:
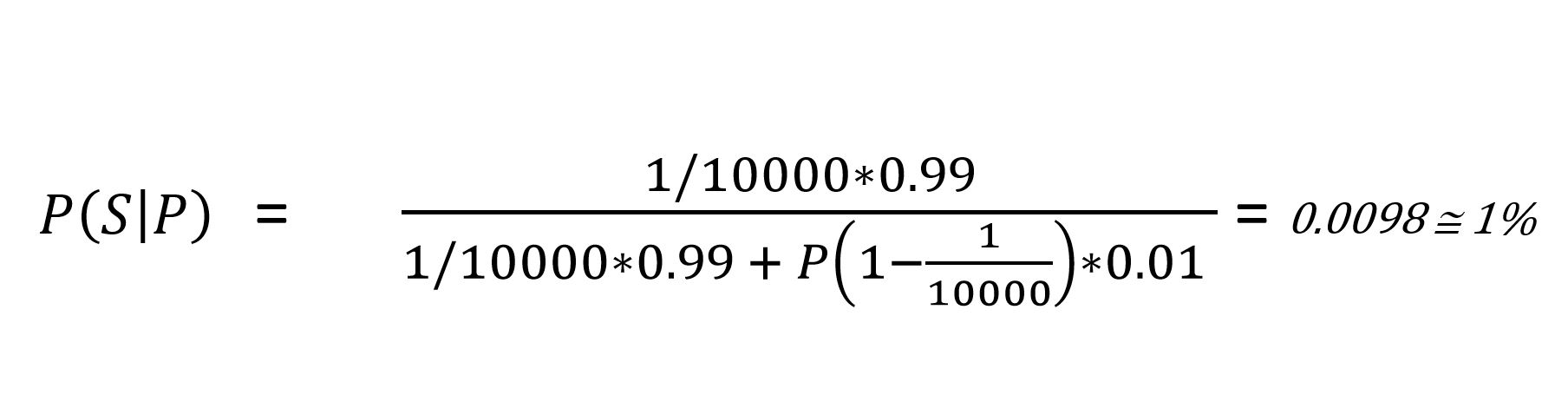
This equation shows that the probability you are sick — even though you tested positive — is less than 1%. How can this be? Even though the test is accurate 99% of the time, malaria is so rare that the chance of being infected in the first place is negligibly small. This misunderstanding is commonly called the base rate fallacy, wherein we misinterpret the outcome of the situation without considering prior knowledge.
How is base rate fallacy relevant to security?
In any detection system, we are essentially building alerts (which are akin to the test for malaria in the previous example), in order to detect the presence of Intrusions (which in our example, are akin to sickness).
Let’s assume that we have 100,000 records in a detection system, and that a specific act of intrusion can be traced back to 20 records. Interpreting this as probability of the intrusive behavior, as observed in our logs, P(I) is 20/100,000 = 2*10-5.
Hence, P(-I) = 1 – P(I) = 1 – 2*10-5 = 0.9998.
Similar to the previous case, we have the following conditions:
- P(A|I) is the probability that your detection can alert, given that there is an intrusion or the true positive rate. In other words, this is the capability to detect when there is an intrusion (similar to P(P|S) in the previous example).
- P(A|-I) are false positives, i.e. there is no intrusion, but the detection method still gives an alert.
The measurable output of your system is, of course, P(I|A) — given that the detection is alerting, what is the probability that my system has found the intrusion?
Again, you can apply Bayes’ Formula to solve the problem:

Even modest false positive rates can be devastating
We can infer that the probability of detecting an intrusion, given that there is an alert (i.e. P(I|A), is highest when the false positive rate (i.e. P(A|-I)) is zero. Therefore, in order for the detection system you are building to have 100% fidelity of alert, it should not generate any false positives.
Even modest false positive rates can quickly make analysts lose faith in detections. Imagine that you build an intrusion detection system, that correctly alerts seven out of 10 times — i.e., the true positive rate is 0.7 and its false positive rate is 0.1. When an alert gets triggered, what is the probability that there is an intrusion? Using the above formula, the probability there is an intrusion is 0.01%; this means, for example, that if the alert triggers 10,000 times, a real intrusion occurs only once. So, in the case of 10,000 alerts, 9,999 are misleading. Put differently, the odds that your security analyst is going to find this alert is as probable as you being struck by lightning in your lifetime.
Increasing the chances of detection
While this illustration is not representative of how intrusion systems are designed in practice, in that intrusion systems are not based on a binary decision and we have clever tricks to ameliorate corner cases (like adding priors), the exercise does indicate how important it is to decrease the false-positive rate and increase our probability of detecting intrusive behavior.
To increase our probability of detecting intrusive behavior, we need to make sure we can find the record of malicious activity easily. In our example above, we could only find traces of intrusion in a measly 20 records out of 100,000, which in turn, dramatically dampens our ability to detect intrusion when there is an alert. Our strategy, therefore, is to increase our chances of finding the malicious records.
A simple but powerful strategy to increase the chances of detections, is to clean your system, so that attack records manifest more easily. However, in practice, this is very difficult because it could take a long time to change or modify the system so that it logs the fields that we care about. A more suitable approach is to look at different log sources and add contextual data.
Techniques for decreasing false positives
If an event is really rare, try using a rule-based atomic detection. For instance, if you are trying to detect xp_cmdshell, to use my colleague John Walton‘s favorite example, you are better off simply searching for xp_cmdshell in your SQL logs instead of trying to build a probabilistic system. Unsurprisingly, highly focused atomic detections can guarantee extremely high precision and a promising recall rate.
Don’t get stuck in the rut with traditional machine learning approaches. If your events are truly rare, you may have a class imbalance problem. There are many ways to solve this — you can try to balance the distribution by sampling intelligently — for instance, you could use the Synthetic Minority Oversampling Technique (SMOTE) to create artificial data based on ‘minority’ events; you could use cost sensitive learning strategies, wherein you specify the cost for misclassifying the data (think Cost Sensitive Boosting); or you could also use active learning methods, wherein you search for the most informative instance and re-train the model.
Overall, in order to increase the fidelity of detections, we have two options at our disposal: first, we can increase the probability of detecting the intrusion (by improved log collection strategy), and second, we can decrease the probability of false positives (either by switching to atomic/rule-based detections or by alternative machine learning techniques).