
 A loom in the Musée du Textile in Cholet, France. (source: By sethoscope on Flickr)
A loom in the Musée du Textile in Cholet, France. (source: By sethoscope on Flickr) In 2011, Kashmir Hill, Gizmodo and others alerted us to a privacy gaffe made by Fitbit, a company that makes small devices to help people keep track of their fitness activities. It turns out that Fitbit broadcast the sexual activity of quite a few of their users. Realizing this might not sit well with those users, Fitbit took swift action to remove the search hits, the data, and the identities of those affected. Fitbit, like many other companies, believed that all the data they gathered should be public by default. Oops.
Does anyone think this is the last time such a thing will happen?
Fitness data qualifies as “personal,” but sexual data is clearly in the realm of the “intimate.” It might seem like semantics, but the difference is likely to be felt by people in varying degrees. The theory of contextual integrity says that we feel violations of our privacy when informational contexts are unexpectedly or undesirably crossed. Publicizing my latest workout: good. Publicizing when I’m in flagrante delicto: bad. This episode neatly exemplifies how devices are entering spaces where they’ve not tread before, physically and informationally.
I spoke at length with Scott David, a legal expert on identity management and technical standards. He sums up the problem in one succinct term: “the Intimacy of Things.” Fitbits recording sexual activity, smart meters deducing when we shower, cars knowing when we don’t go to work, wearable medical devices knowing our weight — our Things are moving into more private spaces. David sees the IoT as more a social phenomenon than a technical one. Accordingly, there are social challenges to consider beyond the merely technical.
In 2004, the UK’s then-Information Commissioner, Richard Thomas, worried aloud if Britain might be “sleepwalking into a surveillance society” because of plans to roll out national ID cards (since defeated). Such a worry can be reapplied to the Internet of Things, though we owe it to ourselves to quash alarmism in favor of measured discussion. The social and the technical can be juxtaposed by imagining a spectrum with surveillance on one end and logging on the other:

Logging is a by-product of systems; it’s vital because programmers and technicians need to know when something goes wrong. On the other end we have surveillance, which David Lyon, one of the world’s foremost scholars on the subject, defines thusly:
“… purposeful, routine, systematic and focused attention paid to personal details, for the sake of control, entitlement, management, influence or protection”
It’s easy to hear evil undertones to the word “surveillance” – with reason – but the above definition gives us a lot more specificity to work with. Does the exposure of Fitbit sex data pass the “surveillance test?” I think not. Somewhere between the poles of logging and surveillance is “monitoring” – less systematic, perhaps not for control or entitlement or influence, but more organized than logging. The Fitbit data lives closer to this middle than to either pole. These terms can, of course, be argued and reframed, but the spectrum is useful when considering privacy aspects of the IoT. Not only does it provide some more language around how to evaluate these aspects, but it also highlights the layered nature of privacy protection.
Privacy layers
Privacy is not a characteristic of a system. It’s not like color you add to glass, or waterproofing to a watch. It is more accurate to say that “privacy preservation” is a characteristic of a system, but that’s far too inexact, much like saying a system is “secure” – the details matter. Further, the details exist within layers. Let’s return to our spectrum and turn it 90 degrees:
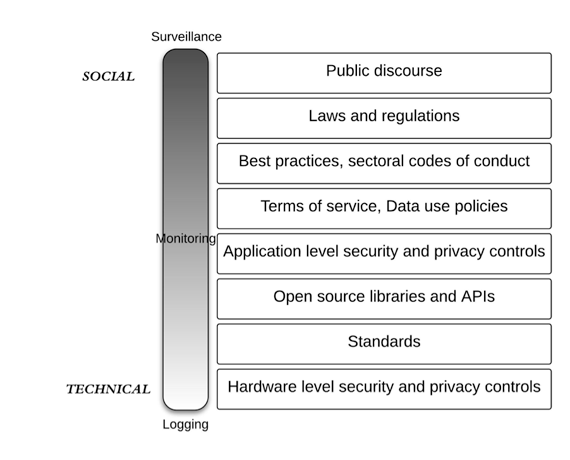
The blocks on the right are layers of rules, code, practices, technology, and ways we speak. They are tools, constraints and behavior that can be arrayed against the spectrum of logging to surveillance. This layered approach yields a lot of granular questions:
- Who can see the logs? How are they locked down in hardware — at the application layer?
- What privacy standards can be engineered into the system?
- What privacy controls do the APIs offer? Are they sufficient?
- How is authentication and authorization secured? How flexible are the policies?
- How do the terms of service and privacy policies relate to the system architecture?
- Are industry best practices for sharing data with third parties considered?
- Does the data collected fall into a regulatory regime, perhaps in another market or country?
- Will the public find any of the data collection or use thereof creepy?
To be sure, the ordering of the layers is not fixed – laws and regulations can affect logging just as hardware level controls can affect surveillance. The point is that the Internet of Things, or whatever term you use to describe billions of connected, sensing devices, is both a technical and a social phenomenon, and the preservation of privacy occurs at many layers, involving bits, wires, radio waves, standards, words, laws, and talk. One can argue about whether we are sleepwalking into a surveillance society, but the Intimacy of Things will certainly monitor and log more and more of our personal moments.
PIA for the IoT
If that list of questions looks a little daunting, that’s OK. It’s a little daunting. Privacy preservation is a social goal, and the increasing complexity of our technologies makes that goal harder and harder to achieve. Still, we must forge ahead, heedless of glib pronouncements that privacy is dead. Regarding complexity, consider building safety: construction technology evolves, there are thousands of things to inspect, and lives could be in the balance. The social goal of preventing harm to people is given voice in building safety regimes, made of laws, regulations, inspection criteria, best practices, professional know-how, certification and sanctions. The preservation of privacy is accomplished in exactly the same way.
For more than a decade now, US government agencies have been required to perform Privacy Impact Assessments (PIAs) when putting new services online. These are just what they sound like: tools to assess the privacy risks posed by the collection and use of personal data by a service or product. Making such an assessment requires a layered and granular approach, much like the list of questions above.
Thankfully, the PIA concept is a mature one. That said, its application to the IoT is in its infancy. In 2011, the European Commission released a Privacy and Data Protection Impact Assessment Framework for RFID Applications. This is one of the first IoT-specific PIA frameworks, though its risk assessment methodology will be familiar to anyone who has dealt with compliance, information governance, or security.
The PIA is a very useful organizing principle, all the more so within the maker community, which will generally have less exposure to risk management and compliance practices. Organizations such as the recently created Internet of Things Privacy Forum (full disclosure: I am the founder of the Forum) and Trilateral Research & Consulting are seeking to broaden and apply Privacy Impact Assessments across IoT stakeholders, from makers to global manufacturers.
Privacy is not something to be lost like a football game or one’s keys. It’s an inherent social property, reflecting our values and intimacies, what we choose to hide and to show. We don’t lose it because technology has evolved, and we don’t preserve it because we cherish it. The billions of devices coming into our homes, onto our person, and into the streets will be watching us. Governance of these growing flows of intimate data will require improved methods, tools, and discourse — the social and the technical.