The log: The lifeblood of your data pipeline
Why every data pipeline should have a Unified Logging Layer.
 The Flamingoes by Henri Rousseau (source: Wikipedia)
The Flamingoes by Henri Rousseau (source: Wikipedia)
The value of log data for business is unimpeachable. On every level of the organization, the question, “How are we doing?” is answered, ultimately, by log data. Error logs tell developers what went wrong in their applications. User event logs give product managers insights on usage. If the CEO has a question about the next quarter’s revenue forecast, the answer ultimately comes from payment/CRM logs. In this post, I explore the ideal frameworks for collecting and parsing logs.
Apache Kafka Architect Jay Kreps wrote a wonderfully crisp survey on log data. He begins with the simple question of “What is the log?” and elucidates its key role in thinking about data pipelines. Jay’s piece focuses mostly on storing and processing log data. Here, I focus on the steps before storing and processing.

Learn faster. Dig deeper. See farther.
Changing the way we think about log data
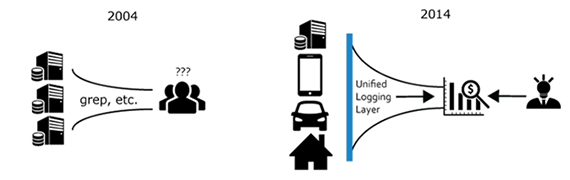
Over the last decade, the primary consumer of log data shifted from humans to machines.
Software engineers still read logs, especially when their software behaves in an unexpected manner. However, in terms of “bytes processed,” humans account for a tiny fraction of the total consumption. Much of today’s “big data” is some form of log data, and businesses run tens of thousands of servers to parse and mine these logs to gain competitive edge.
This shift brought about three fundamental changes in how we ought to think about collecting log data. Specifically, we need to do the following:
-
Make logs consumable for machines first, humans second: Humans are good at parsing unstructured text, but they read very slowly, whereas machines are the exact opposite — they are terrible at guessing the hidden structure of unstructured text but read structured data very, very quickly. The log format of today must serve machines’ needs first and humans’ second.
Several formats are strong candidates: Protocol Buffer, MessagePack, Thrift, etc. However, JSON seems to be the clear winner for one critical reason: It is human readable. At the end of the day, humans also need to read the logs occasionally to perform sanity checks, and JSON is easy to read for both machines and humans. This is one decided advantage that JSON has over binary alternatives like Protocol Buffer. While human reading is secondary to machine intelligibility, it is, after all is said and done, still a requirement for quality logging.
-
Transport logs reliably: The amount of log data produced today is staggering. It’s not unheard of for a young startup to amass millions of users, who in turn produce millions of user events and billions of lines of logs. Product managers and engineers revel at the opportunity to analyze all these logs to understand their customers and make their software better.
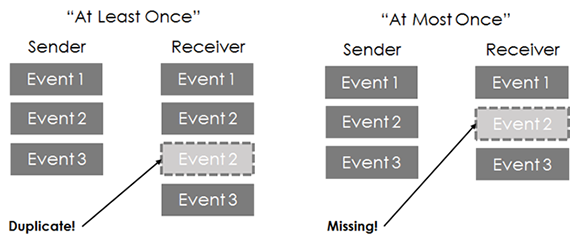
Errors in log transporting over networks. Image courtesy of Kiyoto Tamura. But doing so presents a challenge: Logs need to be transported from where they are produced (mobile devices, sensors, or plain old Web servers) to where they can be archived cost-effectively (HDFS, Amazon S3, Google Cloud Storage, etc.).
Transporting terabytes and petabytes of logs over a network creates an interesting technical challenge. At minimum, the transport mechanism must be able to cope with network failures and not lose any data. Ideally, it should be able to prevent data duplication. Achieving both — or the “exactly once” semantics in data infrastructure parlance — is the holy grail of distributed computing.
-
Support many data inputs and outputs:
Many-to-Many log routing. Image courtesy of Kiyoto Tamura. Today, collecting and storing logs is more complex than ever. On the data input side, we have more devices producing logs in a wide range of formats. On the data output side, it looks like there is a new database or storage engine coming out every month. How can one hope to maintain logging pipelines with so many data inputs and outputs?
The need for the Unified Logging Layer
The answer is pluggable architecture. Every single platform that has managed to address a growing set of use cases, from WordPress through jQuery to Chrome, has a mechanism that allows individual users to extend the core functionality by contributing and sharing their work with other users as a plugin.
This means the user should be able to add his or her own data inputs and outputs as plugins. If a new data input plugin is created, it should be compatible with all existing output plugins and vice versa.
I’ve been calling the software system that meets the above three criteria the “Unified Logging Layer,” or the ULL for short. The ULL should be part of any modern logging infrastructure, as it helps the organization to collect more logs faster, more reliably, and scalably.
Fluentd
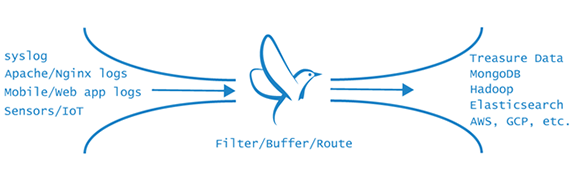
Fluentd is an open source log collector that implements the Unified Logging Layer and addresses each of the three requirements of the Unified Logging Layer.
-
JSON as the unifying format
Fluentd embraces JSON as the data exchange format. When logs come into Fluentd, it parses them as a sequence of JSON objects. Because JSON has become the de facto standard for data exchange while remaining human-readable, it’s a great candidate to satisfy the “make logs consumable machine-first, human-second” requirement of the Unified Logging Layer.
-
Reliability through file-based buffering and failover
Fluentd ensures reliable transport by implementing a configurable buffering mechanism. Fluentd buffers log data by persisting them to disk and keeps retrying until the payload is successfully sent to the desired output system. It also implements failover so that the user can send data to a safe secondary output until the connection to the primary output is recovered.
-
Pluggable inputs, outputs, and more
Fluentd implements all inputs and output as plugins. Today, the ecosystem boasts hundreds of input and outputs plugins contributed by the community, making it easy to send data from anywhere to anywhere.
What’s more: Fluentd’s parser (parsing incoming logs), filter (filtering parsed logs), buffer (how data is buffered), and formatter (formatting outgoing logs) are all pluggable, making it very easy to create and manage flexible and reliable logging pipelines.
You can learn more about the Unified Logging Layer and Fluentd on our website as well as via our GitHub repository.
Appendix: The duality of Kafka and Fluentd
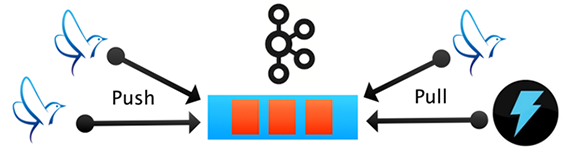
Over the last few years, I have given several talks on Fluentd, and many people have asked me how Fluentd is different from Apache Kafka. The difference is quite clear, actually. Fluentd is one of the data inputs or outputs for Kafka, and Kafka is one of the data inputs or outputs for Fluentd.
Kafka is primarily related to holding log data rather than moving log data. Thus, Kafka producers need to write the code to put data in Kafka, and Kafka consumers need to write the code to pull data out of Kafka. Fluentd has both input and output plugins for Kafka so that data engineers can write less code to get data in and out of Kafka. We have many users that use Fluentd as a Kafka producer and/or consumer.