The problems that information architecture addresses
Read chapter one from Information Architecture
 "Information Architecture, 4th Edition," by Louis Rosenfeld, Peter Morville, and Jorge Arango. (source: O'Reilly Media)
"Information Architecture, 4th Edition," by Louis Rosenfeld, Peter Morville, and Jorge Arango. (source: O'Reilly Media)
And it really doesn’t matter
If I’m wrong, I’m right
Where I belong I’m right
Where I belong“Fixing a Hole,” Lennon–McCartney

Learn faster. Dig deeper. See farther.
In this chapter, we’ll cover:
-
How information broke free from its containers
-
The challenges of information overload and contextual proliferation
-
How information architecture can help people deal with these challenges
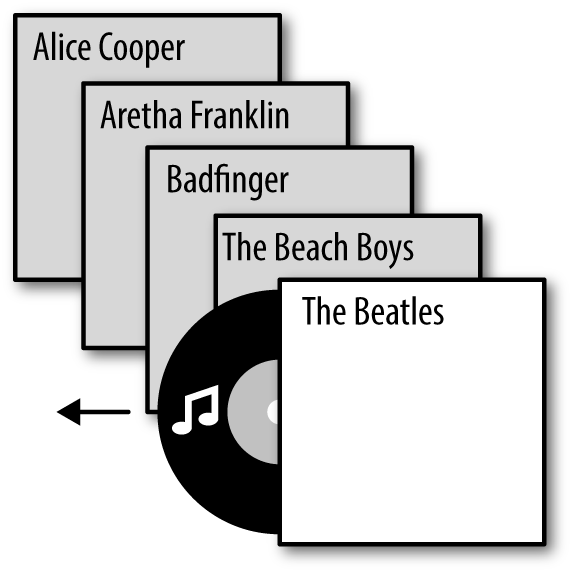
Marla was in the mood for The Beatles. She walked over to the shelf where she kept her LP records and looked through her collection. Fortunately, Marla was very organized: her record collection was neatly sorted alphabetically by the artist’s name. Alice Cooper, Aretha Franklin, Badfinger… and there, next to her Beach Boys albums, were The Beatles. She pulled the Sgt. Pepper’s Lonely Hearts Club Band vinyl disc out of its sleeve and put it on the turntable, and relaxed as the music started.
For most of our history, the information we have interacted with has existed in a one-to-one relationship with the artifacts that contain it. Marla had only one Sgt. Pepper’s album, and if she wanted to listen to it, she needed to know exactly where it was on the shelf. If she was traveling and didn’t bring her record with her, she couldn’t listen to it. Because the information (the music) was physically embedded in containers (vinyl discs), and she only had one copy of each, she had to define “one right way” to organize her records. Should they be ordered alphabetically based on the artists’ first names, as shown in Figure 1-1, or their last names? What about albums in which the composer mattered more than the performer, as in her copy of Holst’s The Planets? Then there were compilation albums, containing music by many artists. Should they be listed under “Various Artists”? And when she bought a new album, she needed to remember to store it in the right place in the collection. It all got very complicated very quickly. Perhaps she shouldn’t bother with organizing them at all… but then she wouldn’t be able to find them easily when she was in the mood for a particular artist.
Now meet Marla’s son, Mario. Instead of vinyl discs, Mario’s record collection consisted of compact discs (CDs). Because the music in the discs was stored digitally, he could now randomize the order in which the songs were played. He’d been promised that the music would also sound better, and the discs would last longer than the previous technology. It was great! However, even though the music was stored digitally, his plastic discs were not that different from his mother’s collection: the music was still tied to the individual physical discs that contained it. He still had to choose whether to organize the discs by the artist’s name or the album’s name; he couldn’t do both.
But then, in 2001, Mario got an iMac. The colorful computer’s advertising campaign invited him to “Rip, Mix, Burn” his music—in other words, liberate it from the plastic discs that contained it and get it into his computer (“Rip”). Once there, it would sound just as good as the CDs, but now he could explore it any way he pleased: he could browse his collection by artist, genre, album title, song title, year produced, and more. He could search it. He could save backup copies. He could make playlists that combined the music from various albums (“Mix”) and record songs onto blank discs (“Burn”) to share with friends (much to the chagrin of the people who’d produced the music).
As shown in Figure 1-2, Mario was no longer limited to the one-to-one relationship between information (the music) and containers (the discs) that his mother had to deal with. He was no longer constrained to deciding between sorting the albums alphabetically by artist name or album name; he could now do both simultaneously. He could make multiple perfect copies of his songs, and bring them with him on his laptop when he traveled. Mario stopped thinking of his music as something tied to its container. It had dematerialized.

Hello, iTunes
The tool that Mario used to do all of this, iTunes, is shown in Figure 1-3. Digital music had been around for a long time before iTunes, but this was the first time that many people encountered it in the mainstream. Originally a third-party application called SoundJam, iTunes was acquired by Apple in 2000 to become the default music player included with Macintosh computers. In its initial release, iTunes served a clear purpose: it allowed Mario to create and manage a music library for use in his own computer (“Rip, Mix, Burn”). He spent a long weekend importing his collection of 40 CDs into his Mac and organizing his music, and put the discs away for good. From now on, his music would be all-digital.
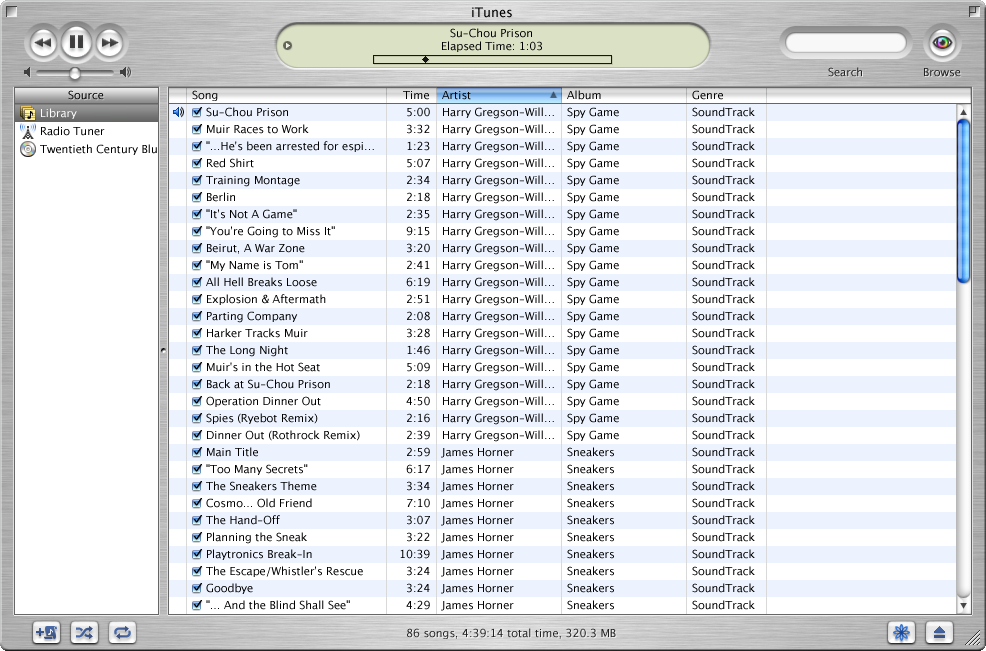
The first version of iTunes had a few distinct modes—for example, there was a “ripping” mode that showed progress when the user was extracting music from a CD into the computer—but its focus was clearly on allowing people like Mario to find and play music from their own collections. As a result of this reduced feature set, it had a very simple user interface and information structures. Mario loved it, and playing music became one of his favorite uses for his Mac.
However, iTunes started to become more complex over time. Each new release of the app introduced amazing new features: smart playlists, podcast subscriptions, Internet radio station streaming, support for audiobooks, streamed music sharing, and more. When Apple released the iPod, Mario rushed to get one. iTunes was now about more than just managing music on his Mac: it was also about managing the library on his portable music player. In 2003, Apple introduced the iTunes Music Store. Now Mario could enter a separate mode within iTunes that allowed him to purchase music, using a categorization scheme that was different from the one he used to organize his own library. By 2005, the iTunes Music Store had more than 2 million songs available, a far cry from the 40 albums that Mario had in his collection to begin with. But Apple didn’t stop there: soon it started selling TV shows and then movies through the (now renamed) iTunes Store. TV shows, movies, and music were presented as distinct categories within the store, and each “department” had its own categorization scheme: rock, alternative, pop, hip-hop/rap, etc. for music; kids & family, comedy, action & adventure, etc. for movies; and so on.
iTunes was not just where Mario listened to and organized his music anymore. Now it was where he went to:
-
Buy, rent, and watch movies
-
Buy, rent, and watch TV shows
-
Preview and buy music
-
Buy applications for his iPod
-
Search for and listen to podcasts
-
Browse and subscribe to “iTunes U” university courses
-
Listen to streaming radio stations
-
Listen to audiobooks
-
Browse and listen to music shared by others in his household
Each of these functions introduced new content types with particular categorization schemes. iTunes still had a search box, as it had on day one, but search results were now much more difficult to parse, because they included different (and incompatible) media types. Was the result for “Dazed and Confused” referring to the movie, the movie soundtrack, the Led Zeppelin song, or one of its myriad covers?
Later, when Mario bought his first iPhone, he was surprised to discover that the functionality that he was used to having in iTunes on the Mac (music, movies, TV shows, podcasts, etc.) had now been “unbundled” into various apps, as shown in Figure 1-4. On the iPhone, iTunes is not where you play music; for that there is an app called (appropriately) “Music.” However, there are no “Movies” or “TV Shows” apps; there is one app (“Videos”) that plays both. This is not where Mario can see the videos he has shot himself, though; for that he has to go to the “Photos” app. There is also an app on the phone where Mario can buy movies, music, and TV shows, called “iTunes Store”—the only reference to iTunes on the phone—and another where he can buy iPhone apps, called “App Store.” All of these apps offer functionality that is available within iTunes on the Mac, and all of them have different content organization structures. Later on, Apple introduced a service called iTunes Match, which allowed Mario to upload his music collection to Apple’s “cloud”; now he also had to keep track of which songs were actually on his phone and his Mac, and which were on Apple’s servers.
Mario bought Apple products in part because of the company’s reputation for excellent design. He’d heard that Apple “controls the hardware and the software,” and was thus able to provide a unified, coherent experience across all of its products. Yet managing his media across his Mac and his iPhone was neither unified nor coherent. Also, over time, Mario became a consumer and an organizer of an information ecosystem; he had to deal with the information structures designed into the system by Apple and his own organization schemes for his personal music collection, which were now transcending many device form factors and contexts. Mario couldn’t quite put his finger on it, but he could tell that something big was amiss with the design of these products, even though he found them visually appealing.

The Problems Information Architecture Addresses
Mario was experiencing two problems:
-
The tool he used to manage and navigate his simple library of 40 or so music albums had changed into one that dealt with hundreds of millions of different data objects of various types (songs, movies, TV shows, apps, podcasts, radio streams, university lectures, and more), each with different organization schemes, business rules (e.g., restrictions on which device he is allowed to play back his rented movie on within the next 24 hours), and ways of interacting with the information (e.g., viewing, subscribing, playing, transcoding, etc.).
-
The functions provided by this tool were no longer constrained to Mario’s computer; they are now available across multiple devices, including his iPhone, iPod, Apple TV, CarPlay, and Apple Watch. Each of these devices brings with it different constraints and possibilities that define what they can (and cannot) do with these information structures (e.g., “Siri, play ‘With a Little Help from My Friends’”), and Mario doesn’t experience them as a consistent, coherent interaction model.
Let’s look at these challenges in a bit more detail.
Information Overload
People have been complaining about having to deal with too much information for centuries. As far back as Ecclesiastes (composed in the 3rd or 4th century BCE), we read that “of making many books there is no end.” However, the information technology revolution that started around 70 years ago has greatly increased the information available to us. The phrase “information overload” was popularized by futurist Alvin Toffler in the 1970s.1 Toffler called out the increased rate and pace of information production, and the resulting reduction in the signal-to-noise ratio, as problems that we’d have to deal with in the future. (As you can see from Mario’s example, this future is now!) The career of Richard Saul Wurman—originator of the term “information architect”—is based on using design to address information overload. His book Information Anxiety2 is considered a classic in the field.
In the 19th and 20th centuries, electronic media such as the telegraph, telephone, radio, and television allowed more information to reach more people over greater distances than ever before. However, the process really sped up in the second half of the 20th century with the appearance of digital computers and their eventual connection into what became the Internet. Suddenly, massive amounts of information could be shared with anyone in the world. The Internet—and the World Wide Web, especially—were conceptualized as two-way, interactive media. For example, you could not only receive email, but also send it. Sir Tim Berners-Lee meant for the Web to be a read/write medium; the first web browser, called WorldWideWeb (with no spaces), gave as much prominence to editing web pages as it did to browsing them. Compared to previous information media, publishing on the Web was fast, cheap, and efficient. As a result, the amount of information being published today in information environments like Facebook, Twitter, and WordPress dwarfs anything that has ever come before.
It’s important to note that while every advance in information technologies has increased the overall amount of information available and has made it possible for more people to publish and have access to information, the resulting glut has also led to the creation of new technologies to help people organize, find, and make better use of information. For example, the invention of the movable type printing press in the 15th century made more books and pamphlets available more cheaply to more people. This, in turn, led to the creation of technologies such as encyclopedias, alphabetic indexes, and public libraries, which allowed people to better manage and make sense of the new information sources.3
It should not be surprising, then, that some of the great success stories of the early Web, such as Google and Yahoo!, were companies founded to help users find information online.4 Still, there is much more information out there than we can manage, and the findability techniques that were effective in the late 1990s (e.g., Yahoo!’s curated hierarchical directory) are ineffective today.
With the rise of app-centric Internet-connected mobile devices such as smartphones, it has become fashionable for pundits to postulate the demise of the World Wide Web. However, instead of making the Web irrelevant, these devices have given more people access to the information available on the Internet. For many applications, the data sources that feed apps tend to be indistinguishable from (if not identical to) those that power the Web. If anything, the mobile revolution has increased access to the information available in the world.
So, back to Mario. Instead of the 400 or so songs in his record collection, he can now peruse the iTunes Store’s collection of 37 million songs. Not that he can flip through it like he could with his CDs (or even at his local Tower Records5); here, he’s going to need a bit of help to find what he’s looking for.
More Ways to Access Information
While the information explosion has been happening for a long time, the second problem Mario faces is newer: the relentless miniaturization of electronics, combined with widespread adoption of wireless communications technologies, has resulted in a proliferation of small, inexpensive Internet-connected devices that are transforming the way that we interact with information and with one another.
As we mentioned earlier, there was a time when information existed in a tightly coupled relationship with the artifacts that conveyed that information. Recall Marla’s record collection. The music in her copy of Sgt. Pepper’s was set into a singular vinyl disc that sat on her shelf. Marla’s copy was a reproduction: many more people had similar vinyl discs with that particular music on it. However, this particular container (the disc) and the information (the music) were irrevocably tied together after being manufactured.
Going back further—to a time before mechanical reproductions—we find an even tighter relationship between information and its containers. Think of early books: making handwritten copies—the only reproduction technique available before the invention of printing—was an extremely onerous process. It wasn’t easy or cheap to make copies, so individual instances of information artifacts such as books were even more valuable. Because of the rarity and cost of these early books, reading them was an activity reserved for particular classes of people (e.g., scholars, monks, aristocrats, etc.) in specific times and places (e.g., an abbey library during daylight hours).
Now consider an ebook, such as you would read on a Kindle. These “books” are not tied at all to their containing devices; a single Kindle ereader can contain hundreds of ebooks, and conversely, each individual Kindle ebook can be downloaded and read on a wide variety of different devices, ranging from smartphones to dedicated ereaders to desktop computers. You can have the same book open in more than one device at a time, as either a text file or an audiobook, and your reading position—along with your highlights and annotations—is synchronized instantaneously between devices. The presentation of these books varies from device to device depending on the features and limitations of each, with the text itself being an invariant that is reformatted, reflowed, and reconfigured to fit its new environment. (Perhaps you are reading or listening to these words on such a device!)
Whereas physical books—especially the expensive, handwritten ones—had constraints on when and where you could use them, ebooks have no such limitations. You are as likely to be reading an ebook while taking a bath as while standing in line at the supermarket. The result is that the information (e.g., the text of the book) is decoupled not only from the artifact that contains it (e.g., the paper book), but also from the contexts in which we access it (e.g., the quiet abbey library).
Another important difference between physical media (like printed books) and their digital counterparts is that the latter are part of a system that can gather information about their usage, including highlights, annotations, and reading patterns, and provide additional functionality based on this metadata. For example, Kindle apps include a feature called “popular highlights” that allows the reader to identify the passages of a book that have been most often highlighted by other Kindle readers (Figure 1-5). Decoupling information from its physical containers has also made it cheaper to reproduce and distribute, and this in turn has made it more available to more people. Fortunately, the days when information was only accessible to monks in abbey libraries are long gone.

Obviously, contextual proliferation is not just happening for books; we are experiencing it with all of our information technologies. As mentioned earlier, if Marla wanted to bring Sgt. Pepper’s along with her on a trip, she needed to bring the physical vinyl disc with her, and her music library back home would have a gap where that particular album used to be. On the other hand, when Mario wants to bring Sgt. Pepper’s on a trip, all he needs to do is drag a copy of the bits that represent the album from his computer onto his iPhone. Both devices now have exact replicas of the information, and neither music library is reduced as a result of the operation.
The next logical step in the dematerialization of information is for it to permeate our surroundings and become an ever-present feature of our personal interactions with the world. We can already see the beginnings of this ambient digital information layer in what is being referred to as the “Internet of Things”—the proliferation of small Internet-connected devices into everyday contexts and activities—and in “wearable” computers, whose constant proximity to our bodies allows them to record health and activity data, serve us small morsels of information in the form of just-in-time notifications, and activate or enable functions in the environment. Devices like the Fitbit activity monitors and the Nest thermostat serve as two-way information conduits between our physical environments and cyberspace, learning from our behavior patterns and adjusting themselves accordingly to suit our needs.
A fascinating example of this trend toward blurring of physical and information spaces was an innovating marketing campaign carried out in 2011 by South Korean supermarket chain Home Plus. In a bid for increased market share, Home Plus appealed to smartphone-wielding commuters by plastering subway stations with photographs of shelves full of groceries. Customers could walk up to these virtual shelves and order their groceries by snapping photos of QR codes associated with products (Figure 1-6.) Delivery would happen within minutes or hours, saving commuters time. As a result of the campaign, sales increased 130% in three months, and registered users increased 76%.

To summarize, we are not only having to deal with more information than ever before, we are also doing so in a wide variety of different physical and psychological contexts. This will take getting used to: we bring different expectations to a web search entered on a computer keyboard in a quiet office than one tapped into a five-inch glass screen in a football stadium or spoken into a car’s Bluetooth audio system while driving at 50 miles per hour. Increasingly, organizations have to consider how users will access their information in these and many other wildly different contexts. They will obviously want these experiences to be consistent and coherent regardless of where and how the information is being accessed.
So, Mario is not only faced with finding new music to listen to from a collection of over 37 million songs; he’s having to do so using multiple devices—notebook computer, smartphone, TV set-top box, and more—that provide very different ways of interacting with the information, and in a wide variety of different contexts. Mario is going to need a lot of help from the people who design these products and services.
Enter Information Architecture
Part of the reason Mario is confused is that while most software applications are designed to solve very specific problems, the successful ones tend to outgrow their problem-set boundaries to encompass more and more functionality over time. As a result, they lose clarity and simplicity. As we saw, while iTunes started its life as a tool to enable the digitization and management of music collections in personal computers, it grew to become a media platform that encompasses the original music ripping, playing, and organizing functionalities plus other media types (movies, podcasts, audiobooks, university courses, other software applications), other modes of access (buying, renting, streaming, subscribing, sharing), and various device/interaction paradigms (Microsoft Windows computers, iPods, iPads, Apple Watches, Apple TVs). In other words, iTunes went from being a tool to being an ecosystem.
Given the information and device class proliferation we mentioned earlier, this is a situation many organizations are already struggling with. What is needed is a systematic, comprehensive, holistic approach to structuring information in a way that makes it easy to find and understand—regardless of the context, channel, or medium the user employs to access it. In other words, someone needs to step out of the product development trenches and look at the broader picture in the abstract, to understand how it all fits together so that information can be easier to find and to understand. Information architecture can be used as a lens to help teams and individuals gain this perspective.
Places Made of Information
As we’ve said before, the experience of using digital products and services is expanding to encompass multiple devices in different places and times. It’s important to recognize that we interact with these products and services through the use of language: labels, menus, descriptions, visual elements, content, and their relationships with one another create an environment that differentiates these experiences and facilitates understanding (or not!). For example, the language employed by a recipe app on a mobile phone is bound to be different from that employed by an auto insurance company’s website. These differences in language help define them as distinct “places” that people can visit to accomplish certain specific tasks: they create a frame for the information they convey, allowing us to understand it relative to concepts we already know.
In his book Understanding Context, information architect Andrew Hinton argues that we make sense of these experiences much like we do physical places: by picking up on particular words and images that define what can and can’t be done in the environment—be it an idyllic open field in the English countryside or a web search engine. Digital experiences are new (and very real) types of places made of information; the design challenge lies in making them be coherent across multiple contexts. As Andrew says, “Information architecture is a discipline well-suited for attending to these challenges. It has been working with them in one way or another for decades.”6
Coherence Across Channels
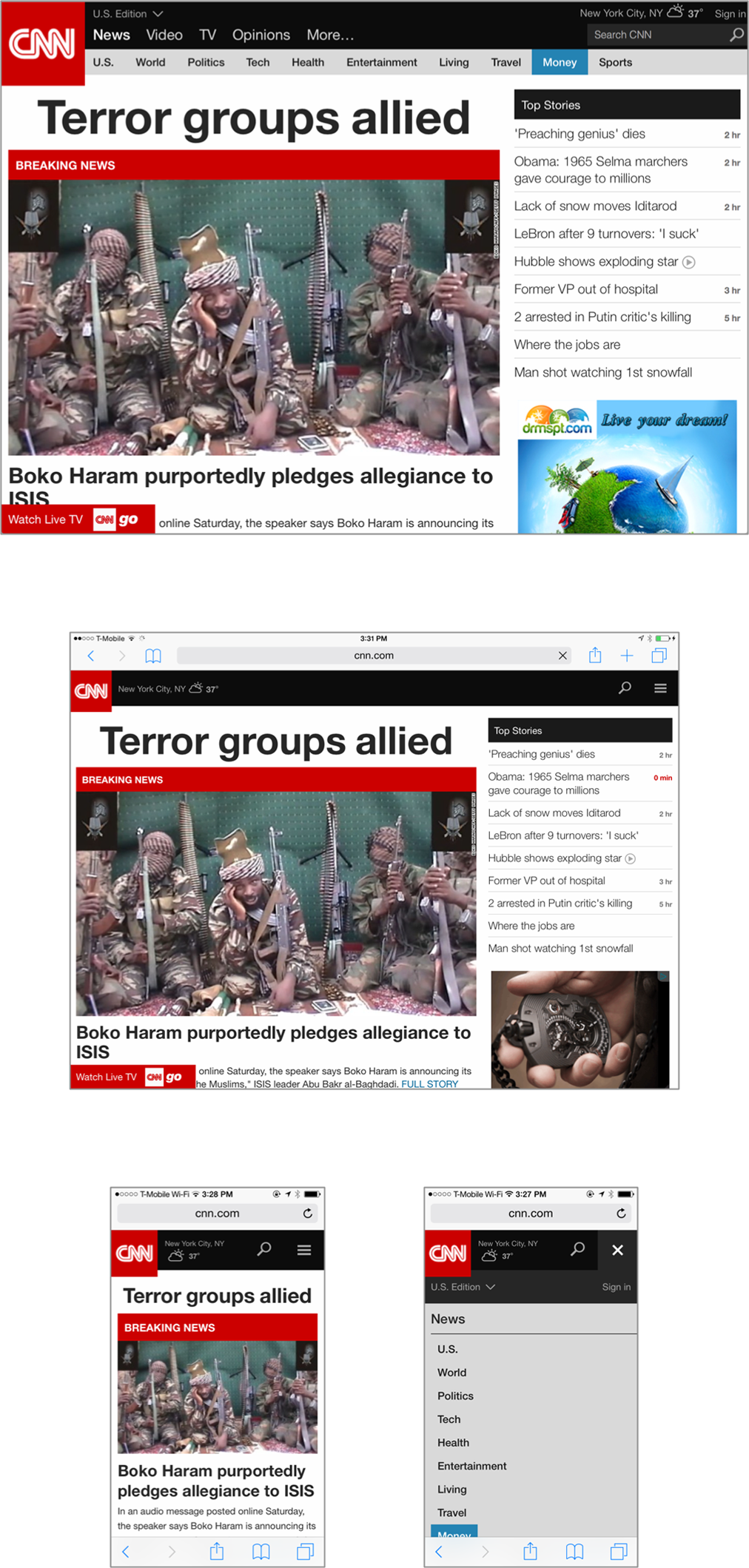
How does information architecture achieve this coherence? To begin with, it does so by asking designers to think about these challenges in the abstract. Where other design disciplines are focused on specific instances of an artifact—the label on a bottle of detergent, the look and feel of an app’s user interface—information architecture asks designers to define semantic structures that can be instantiated in multiple ways depending on the needs of different channels. A navigation structure that works well in a desktop web page should function differently when presented on a five-inch touchscreen, but the user’s experience with both should be coherent (Figure 1-7).
In their landmark book Pervasive Information Architecture, Andrea Resmini and Luca Rosati argue for consistency as a critical component of what they call a pervasive information architecture—that is, one that is experienced across multiple channels and contexts. As they explain it:
Consistency is the capability of a pervasive information architecture to serve the contexts it is designed for (internal consistency), and to preserve this logic across different media, environments, and uses (external consistency)…Consistency needs to be designed with the context it is addressing clear in mind, and in respect to the several media and environments that the service or process will span.7
In other words, when an organization serves its users via multiple channels, the users’ experiences across those channels should be consistent and familiar. For example, a person using a bank’s mobile app should experience consistent semantic structures when using the bank’s website or calling the bank’s phone-based service. While the capabilities and limitations of each channel are different, the semantic structures employed in each of them should be familiar and consistent. In order for this to happen, they must be abstracted from actual implementations.
Systems Thinking
Because of this emphasis on abstracting solutions to complex challenges, information architecture also requires that the designer think systemically about the problems at hand. Where other design disciplines focus on the design of particular artifacts, information architecture is concerned with defining the semantic systems that the individual artifacts—apps, websites, voice interfaces, etc.—will be working within. Peter’s book Intertwingled is an impassioned plea for systems thinking in the design of complex information environments. He calls out the dangers of low-level thinking when trying to design these new types of products and services:
In the era of ecosystems, seeing the big picture is more important than ever, and less likely. It’s not simply that we’re forced into little boxes by organizational silos and professional specialization. We like it in there. We feel safe. But we’re not. This is no time to stick to your knitting. We must go from boxes to arrows. Tomorrow belongs to those who connect.8
You can’t design products and services that work effectively and coherently across various interaction channels if you don’t understand how they influence and interact with one another and with various other systems that affect them. As mentioned earlier, each interaction channel brings to the mix different limitations and possibilities that should inform the whole. A high-level, comprehensive understanding of the ecosystem can help ensure that its constituent elements work together to present coherent experiences to users. As a discipline, information architecture is ideally suited to this task.
That said, the focus of information architecture is not only on high-level, abstract models: the design of products and services that are findable and understandable requires the creation of many low-level artifacts as well. Traditionally, many people think of website navigation structures when they think of information architecture, and this view isn’t entirely off: navigation menus and their ilk are certainly within the remit of what information architecture produces. It’s just that you can’t get there without having explored the more abstract territory first. Effective information environments strike a balance between structural coherence (high-level invariance) and suppleness (low-level flexibility), so well-designed information architectures consider both.
Having a systems-level view that is informed by (and that informs) day-to-day design activities is also a good way of ensuring that you are solving the right problems. In his book Introduction to General Systems Thinking, computer scientist Gerald Weinberg uses the following story to illustrate what he calls fallacies of absolute thought:
A minister was walking by a construction project and saw two men laying bricks. “What are you doing?” he asked the first.
“I’m laying bricks,” he answered gruffly.
“And you?’’ he asked the other. “I’m building a cathedral,” came the happy reply.
The minister was agreeably impressed with this man’s idealism and sense of participation in God’s Grand Plan. He composed a sermon on the subject, and returned the next day to speak to the inspired bricklayer. Only the first man was at work.
“Where’s your friend?” asked the minister.
“He got fired.”
“How terrible. Why?”
“He thought we were building a cathedral, but we’re building a garage.”9
So ask yourself: am I designing a cathedral or a garage? The difference between the two is important, and it’s often hard to tell them apart when your focus is on laying bricks. Sometimes—as in the case of iTunes—designers start working on a garage, and before they know what’s happening, they’ve grafted an apse, choir, and stained-glass windows onto it, making it hard to understand and use. Information architecture can help ensure that you’re working on the plans for a great garage (the best in the world!)—or a cathedral, if such is the problem you’re trying to solve. In the rest of the book, we’ll show you how.
Recap
Let’s recap what we’ve learned thus far:
-
Historically, information has shown a tendency to dematerialize, going from having a one-to-one relationship with its containers to being completely detached from its containers (as is the case with our digital information).
-
This has had two important effects in our time: information is more abundant than ever before, and we have more ways of interacting with it than ever before.
-
Information architecture is focused on making information findable and understandable. Because of this, it is uniquely well suited to address these issues.
-
It does this by asking the designer to think about problems through two important perspectives: that our products and services are perceived as places made of information, and that they function as ecosystems that can be designed for maximum effectiveness.
-
That said, information architecture doesn’t operate solely at the level of abstractions: for it to be effective, it needs to be defined at various levels.
In not available, we will give you a deeper overview of the discipline of IA, and will have a shot at defining the damned thing.10
1Alvin Toffler, Future Shock (New York: Random House, 1970).
2Richard Saul Wurman, Information Anxiety (New York: Bantam, 1989).
3For more on this topic, see Ann Blair’s Boston Globe article “Information overload, the early years”.
4Google’s stated mission is to “organize the world’s information and make it universally accessible and useful.”
5R.I.P.
6Andrew Hinton, Understanding Context (Sebastopol, CA: O’Reilly, 2014), 252.
7Andrea Resmini and Luca Rosati, Pervasive Information Architecture: Designing Cross-Channel User Experiences (Burlington, MA: Morgan Kaufmann, 2011), 90.
8Peter Morville, Intertwingled: Information Changes Everything (Ann Arbor, MI: Semantic Studios, 2014), 5.
9Gerald Weinberg, An Introduction to General Systems Thinking (New York: Dorset House, 2001) 61.
10“Defining the damned thing”—or DTDT, as it is often shortened on Twitter and mailing lists—is an ongoing source of contention in the IA community, to the merriment of some and annoyance of others. When you make a living labeling things, squabbles about conceptual boundaries are an occupational hazard.