Training and serving NLP models using Spark MLlib
Beyond data processing: Utilizing Spark for individual predictions.
 Typewriter. (source: Pexels)
Typewriter. (source: Pexels)
Identifying critical information out of a sea of unstructured data, or customizing real-time human interaction are a couple of examples of how clients utilize our technology at Idibon—a San Francisco startup focusing on Natural Language Processing (NLP). The machine learning libraries in Spark ML and MLlib have enabled us to create an adaptive machine intelligence environment that analyzes text in any language, at a scale far surpassing the number of words per second in the Twitter firehose.
Our engineering team has built a platform that trains and serves thousands of NLP models, which function in a distributed environment. This allows us to scale out quickly and provide thousands of predictions per second for many clients simultaneously. In this post, we’ll explore the types of problems we’re working to resolve, the processes we follow, and the technology stack we use. This should be helpful for anyone looking to build out or improve their own NLP pipelines.

Learn faster. Dig deeper. See farther.
Constructing predictive models with Spark
Our clients are companies that need to automatically classify documents or extract information from them. This can take many diverse forms, including social media analytics, message categorization and routing of customer communications, newswire monitoring, risk scoring, and automating inefficient data entry processes. All of these tasks share a commonality: the construction of predictive models, trained on features extracted from raw text. This process of creating NLP models represents a unique and challenging use case for the tools provided by Spark.
The process of building a machine learning product
A machine learning product can be broken down into three conceptual pieces: the prediction itself, the models that provide the prediction, and the data set used to train the models.
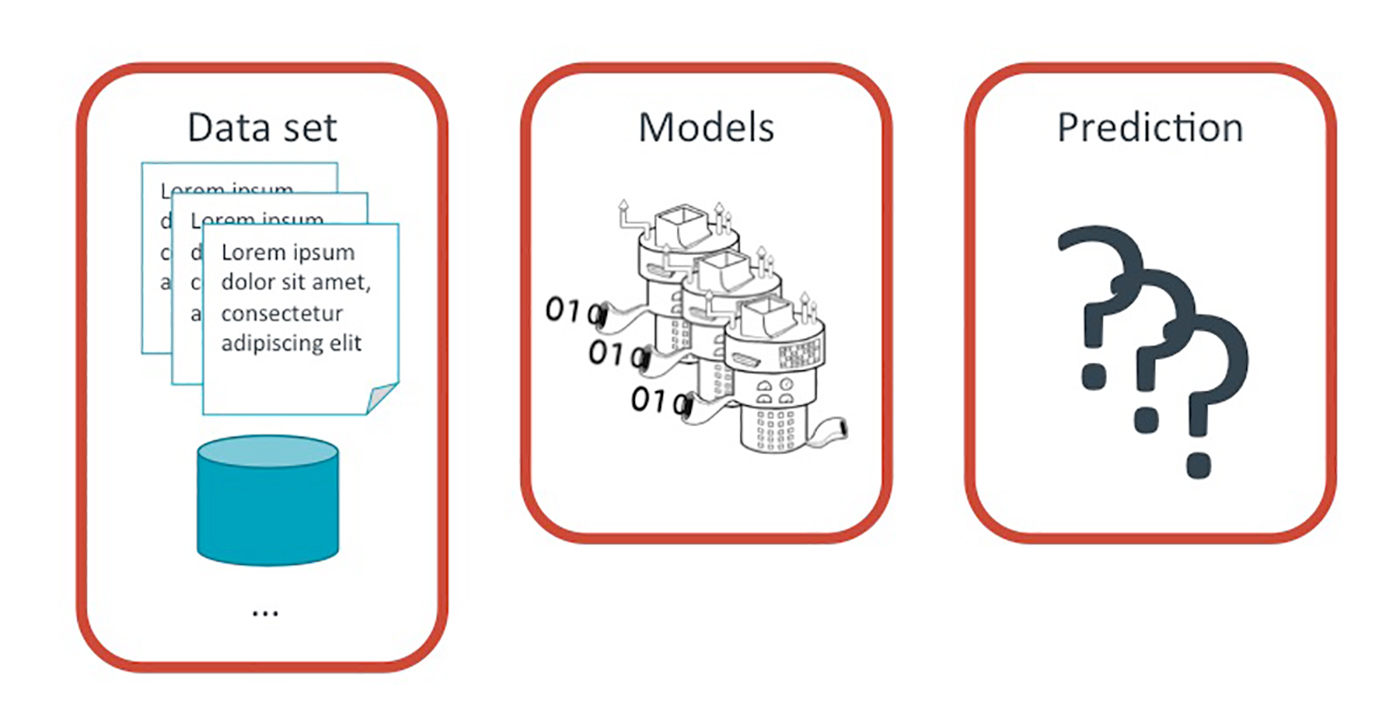
Prediction
In our experience, it’s best to begin with business questions and use them to drive the selection of data sets, rather than having data sets themselves drive project goals. If you do begin with a data set, it’s important to connect data exploration with critical business needs as quickly as possible. With the right questions in place, it becomes straightforward to choose useful classifications, which is what a prediction ultimately provides.
Data set
Once the predictions are defined, it becomes fairly clear which data sets would be most useful. It is important to verify that the data you have access to can support the questions you are trying to answer.
Model training
Having established the task at hand and the data to be used, it’s time to worry about the models. In order to generate models that are accurate, we need training data, which is often generated by humans. These humans may be experts within a company or consulting firm, or in many cases, they may be part of a network of analysts.
Additionally, many tasks can be done efficiently and inexpensively by using a crowdsourcing platform like CrowdFlower. We like their platform because it categorizes workers based on specific areas of expertise, which is particularly useful for working with languages other than English.
All of these types of workers submit annotations for specific portions of the data set in order to generate training data. The training data is what you’ll use to make predictions on new or remaining parts of the data set. Based on these predictions, you can make decisions about the next set of data to send to annotators. The point here is to make the best models with the fewest human judgements. You continue iterating between model training, evaluation, and annotation—getting higher accuracy with each iteration. We refer to this process as adaptive learning, which is a quick and cost-effective means of producing highly accurate predictions.
Operationalization
To support the adaptive learning process, we built a platform that automates as much as possible. Having components that auto-scale without our intervention is key to supporting a real-time API with fluctuating client requests. A few of the tougher scalability challenges we’ve addressed include:
- Document storage
- Serving up thousands of individual predictions per second
- Support for continuous training, which involves automatically generating updated models whenever the set of training data or model parameters change
- Hyperparameter optimization for generating the most performant models
We do this by using a combination of components within the AWS stack, such as Elastic Load Balancing, Autoscaling Groups, RDS, and ElastiCache. There are also a number of metrics that we monitor within New Relic and Datadog, which alert us before things go terribly awry.
Below is a high-level diagram of the main tools in our infrastructure.
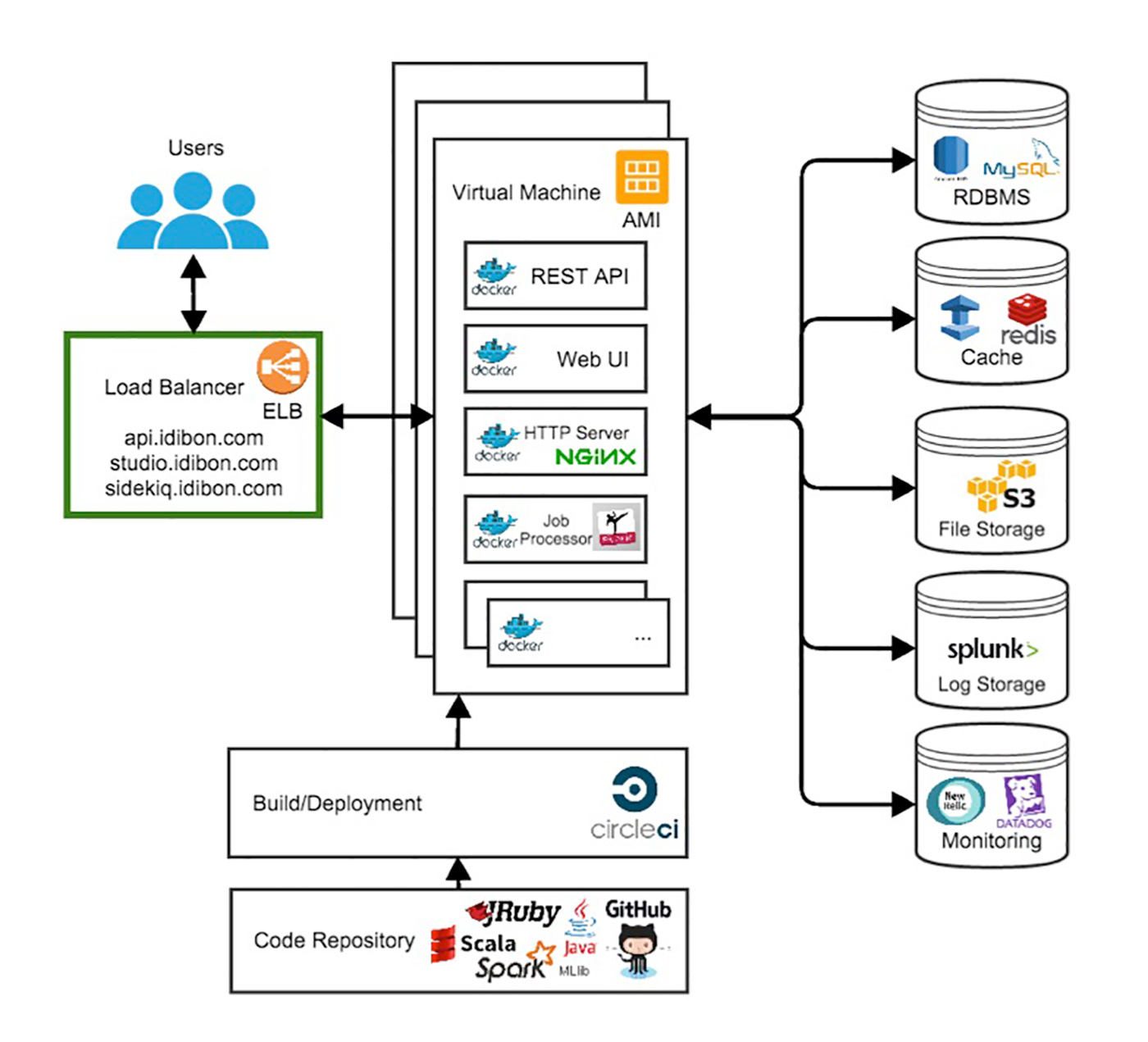
Spark’s role
A core component of our machine learning capabilities is the optimization functionality within Spark ML and MLlib. Making use of these for NLP purposes involves the addition of a persistence layer that we refer to as IdiML. This allows us to utilize Spark for individual predictions, rather than its most common usage as a platform for processing large amounts of data all at once.
What are we using Spark for?
At a more detailed level, there are three main components of an NLP pipeline:
- Feature extraction, in which text is converted into a numerical format appropriate for statistical modeling.
- Training, in which models are generated based on the classifications provided for each feature vector.
- Prediction, in which the trained models are used to generate a classification for new, unseen text.
A simple example of each component is described below:
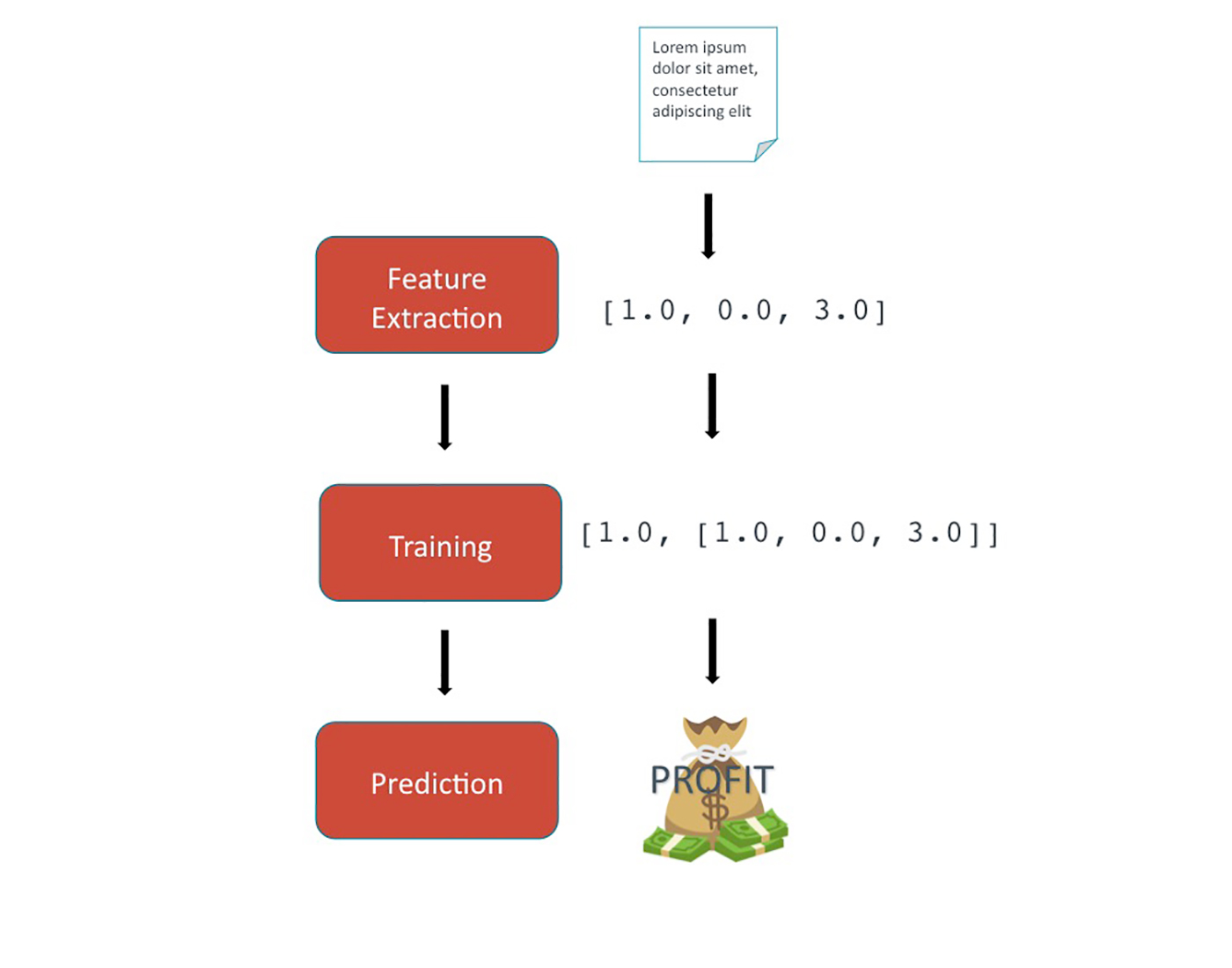
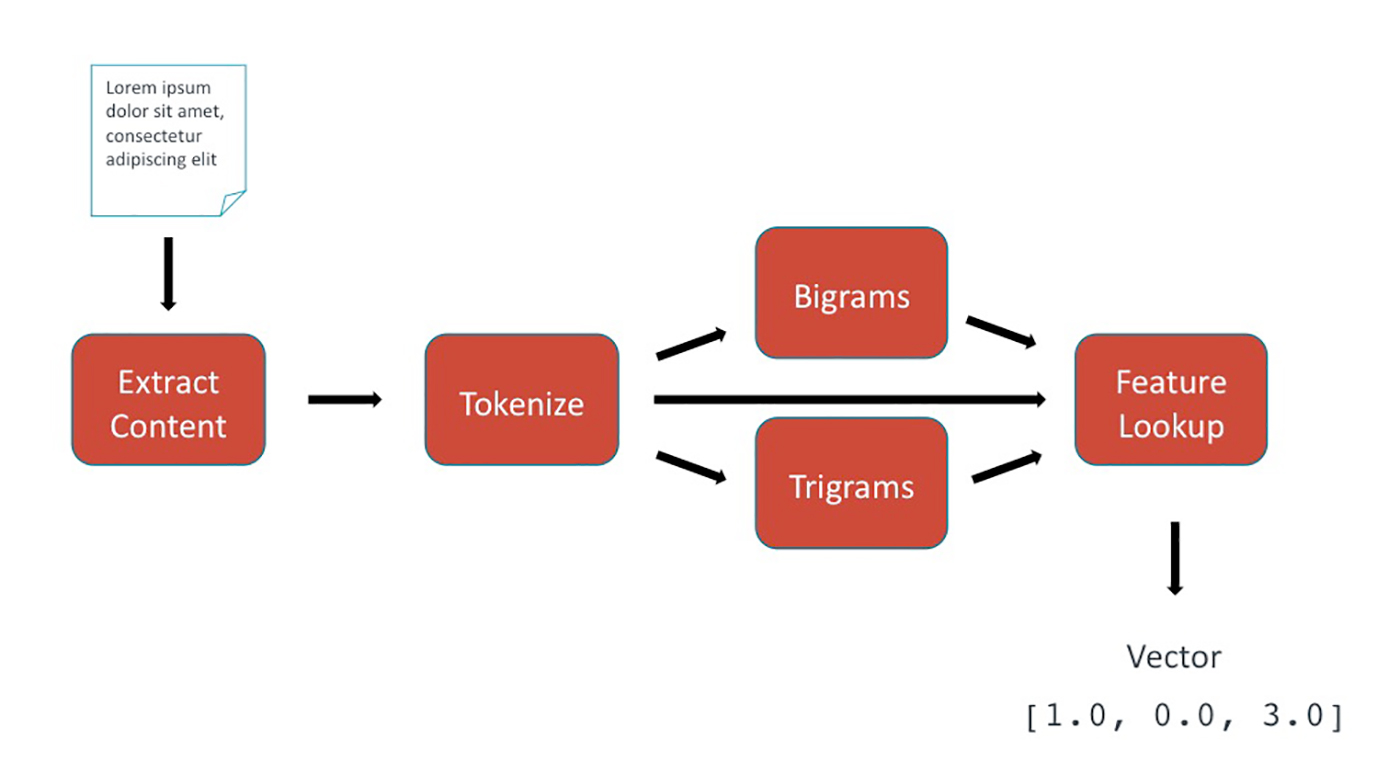
Feature extraction
In the feature extraction phase, text-based data is transformed into numerical data in the form of a feature vector. This vector represents the unique characteristics of the text and can be generated by any sequence of mathematical transformations. Our system was built to easily accommodate additional feature types, such as features derived from deep learning, but for simplicity’s sake, we’ll consider a basic feature pipeline example:
- Input: a single document, consisting of content and perhaps metadata.
- Content extraction: isolates the portion of the input that we’re interested in, which is usually the content itself.
- Tokenization: separates the text into individual words. In English, a token is more or less a string of characters with whitespace or punctuation around them, but in other languages like Chinese or Japanese, you need to probabilistically determine what a “word” is.
- Ngrams: generates sets of word sequences of length n. Bigrams and trigrams are frequently used.
- Feature lookup: assigns an arbitrary numerical index value to each unique feature, resulting in a vector of integers. This feature index is stored for later use during prediction.
- Output: a numerical feature vector in the form of Spark MLlib’s
Vectordata type (org.apache.spark.mllib.linalg.Vector).
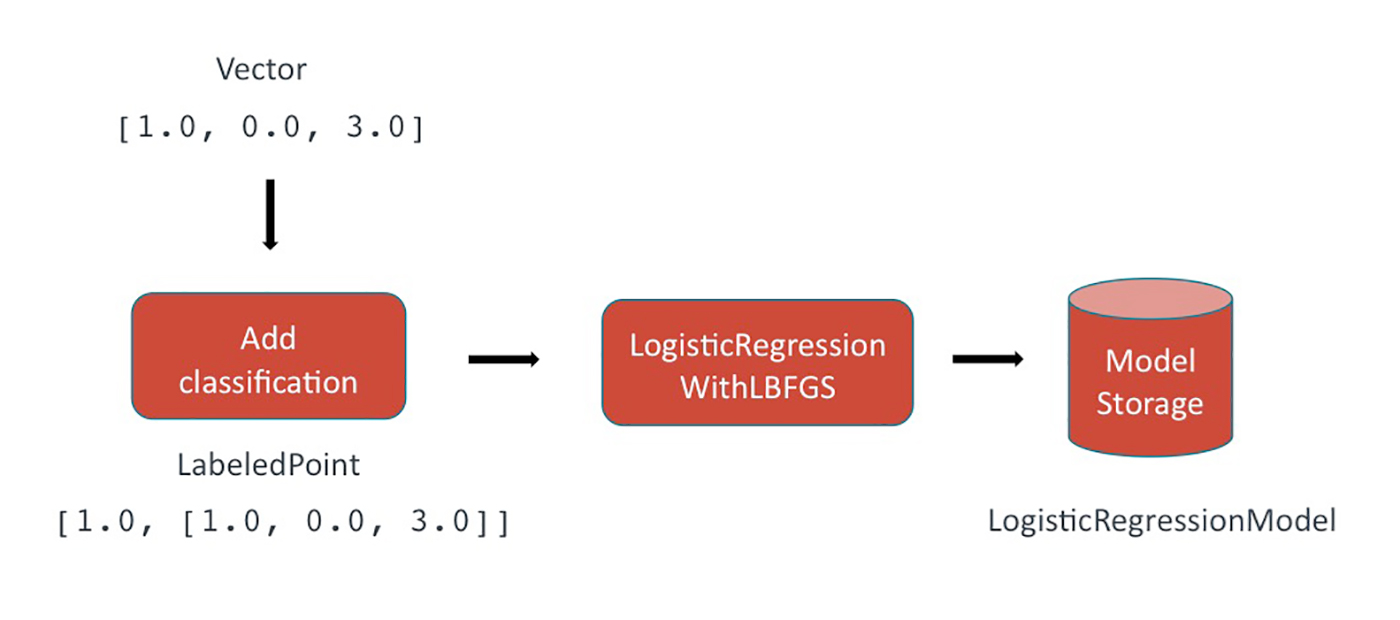
Training
During the training phase, a classification is appended to the feature vector. In Spark, this is represented by the LabeledPoint data type. In a binary classifier, the classification is either true or false (1.0 or 0.0).
- Input: numerical feature
Vectors. - A
LabeledPointis created, consisting of the feature vector and its classification. This classification was generated by a human earlier in the project lifecycle. - The set of
LabeledPointsrepresenting the full set of training data is sent to theLogisticRegressionWithLBFGSfunction in MLlib, which fits a model based on the given feature vectors and associated classifications. - Output: a
LogisticRegressionModel.
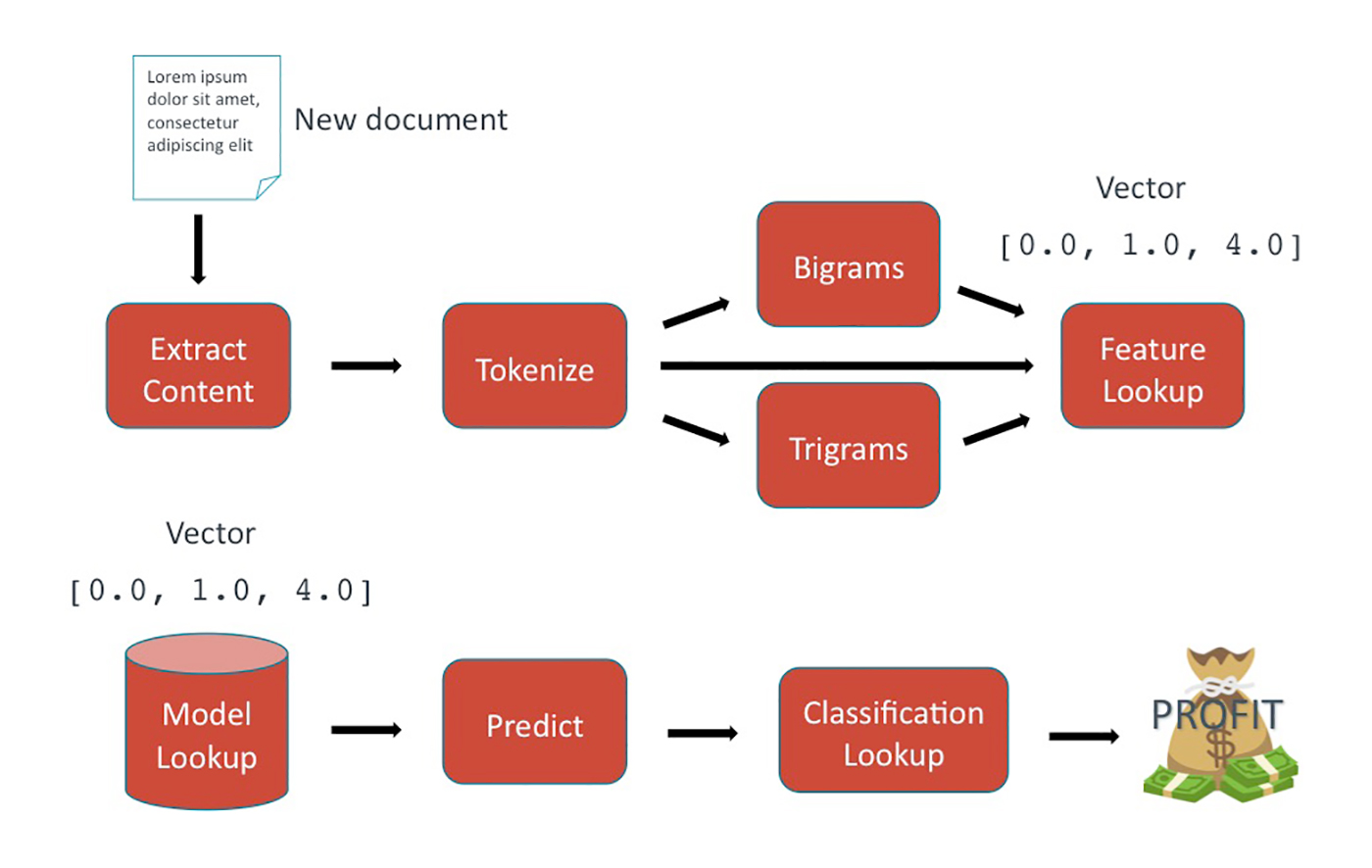
Prediction
At prediction time, the models generated during training are used to provide a classification for the new piece of text. A confidence interval of 0-1 indicates the strength of the model’s confidence in the prediction. The higher the confidence, the more certain the model is. The following components encompass the prediction process:
- Input: unseen document in the same domain as the data used for training.
- The same featurization pipeline is applied to the unseen text. The feature index generated during training is used here as a lookup. This results in a feature vector in the same feature space as the data used for training.
- The trained model is retrieved.
- The feature
Vectoris sent to the model, and a classification is returned as a prediction. - The classification is interpreted in the context of the specific model used, which is then returned to the user.
- Output: a predicted classification for the unseen data and a corresponding confidence interval.
Prediction data types
In typical Spark ML applications, predictions are mainly generated using RDDs and DataFrames: the application loads document data into one column and MLlib places the results of its prediction in another. Like all Spark applications, these prediction jobs may be distributed across a cluster of servers to efficiently process petabytes of data. However, our most demanding use case is exactly the opposite of big data: often, we must analyze a single, short piece of text and return results as quickly as possible, ideally within a millisecond.
Unsurprisingly, DataFrames are not optimized for this use case, and our initial DataFrame-based prototypes fell short of this requirement.
Fortunately for us, MLlib is implemented using an efficient linear algebra library, and all of the algorithms we planned to use included internal methods that generated predictions using single Vector objects without any added overhead. These methods looked perfect for our use case, so we designed IdiML to be extremely efficient at converting single documents to single Vectors so that we could use Spark MLlib’s internal Vector-based prediction methods.
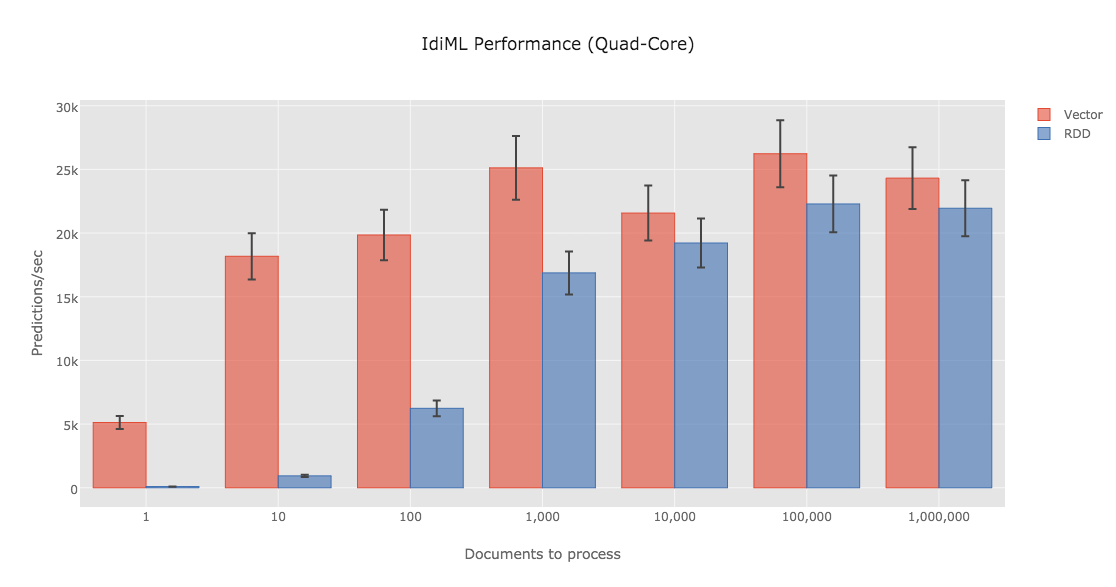
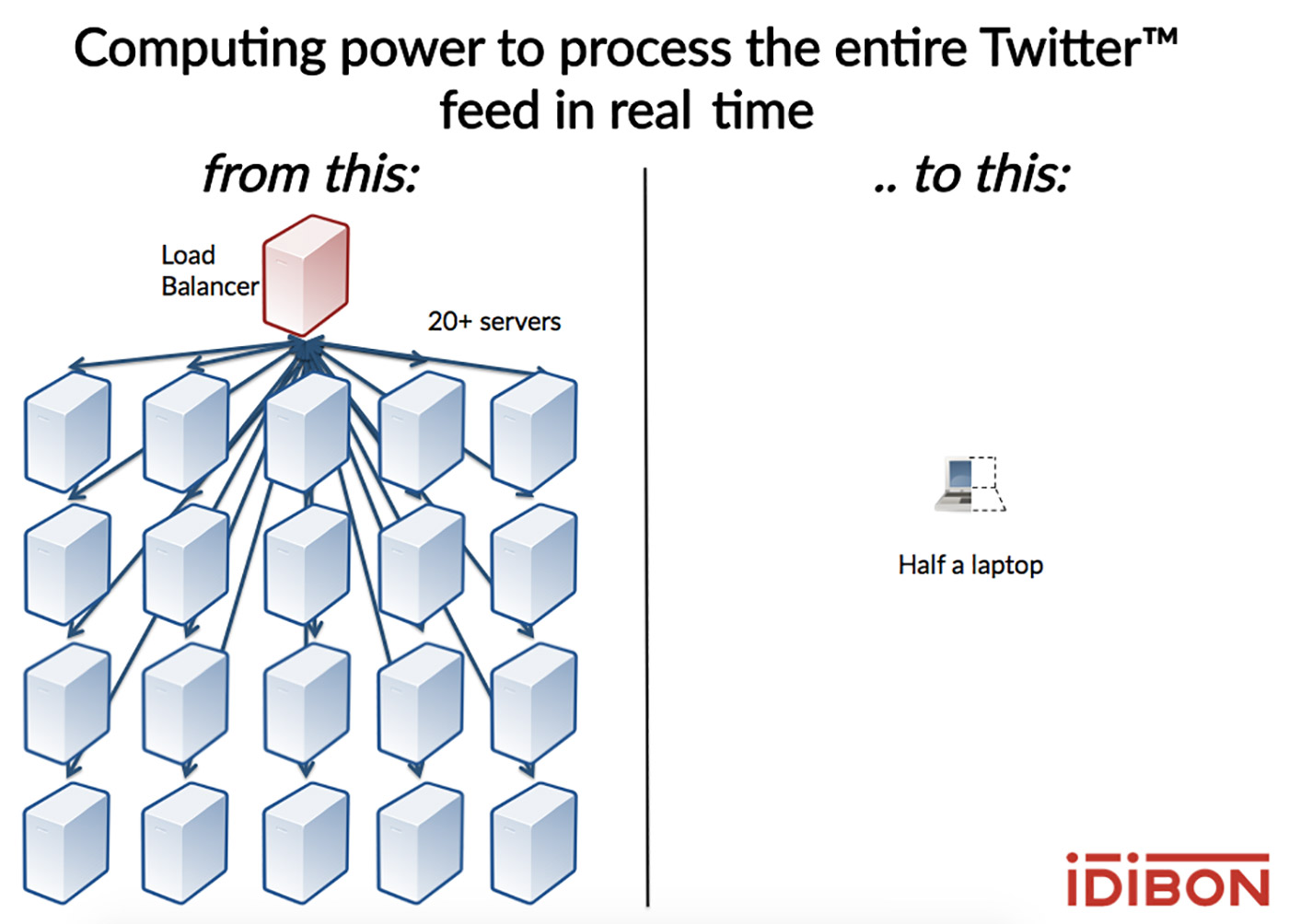
For a single prediction, we observed speed improvements of up to two orders of magnitude by working with Spark MLlib’s Vector type as opposed to RDDs. The speed differences between the two data types are most pronounced among smaller batch sizes. This makes sense considering that RDDs were designed for processing large amounts of data. In a real-time Web server context such as ours, small batch sizes are by far the most common scenario. Since distributed processing is already built into our Web server and load-balancer, the distributed components of core Spark are unnecessary for the small-data context of individual predictions. As we learned during the development of IdiML and have shown in the chart above, Spark MLlib is an incredibly useful and performant machine learning library for low-latency and real-time applications. Even the worst-case IdiML performance is capable of performing sentiment analysis on every Tweet written, in real time, from a mid-range consumer laptop.
Fitting it into our existing platform with IdiML
In order to provide the most accurate models possible, we want to be able to support different types of machine learning libraries. Spark has a unique way of doing things, so we want to insulate our main code base from any idiosyncrasies. This is referred to as a persistence layer (IdiML), which allows us to combine Spark functionality with NLP-specific code that we’ve written ourselves. For example, during hyperparameter tuning we can train models by combining components from both Spark and our own libraries. This allows us to automatically choose the implementation that performs best for each model, rather than having to decide on just one for all models.
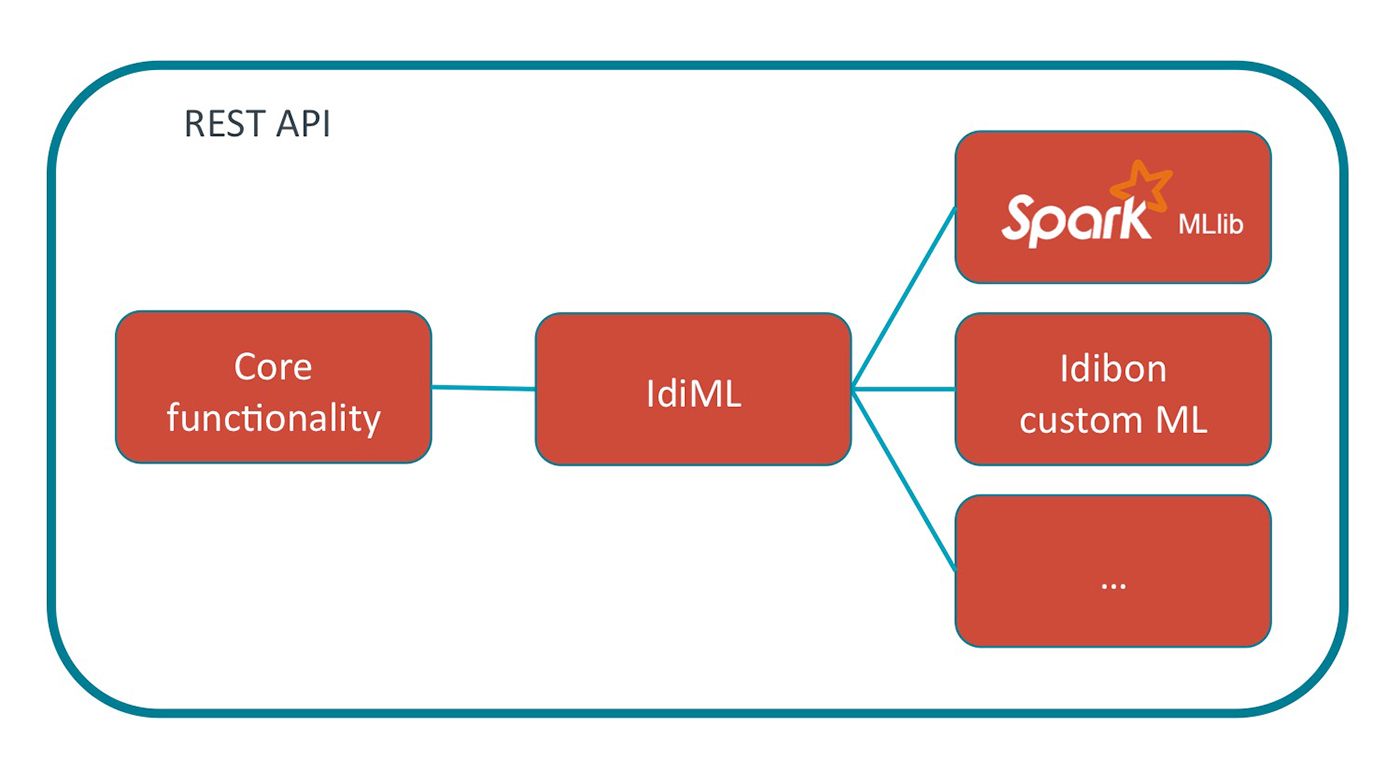
Why a persistence layer?
The use of a persistence layer allows us to operationalize the training and serving of many thousands of models. Here’s what IdiML provides us with:
- A means of storing the parameters used during training. This is necessary in order to return the corresponding prediction.
- The ability to version control every part of the pipeline. This enables us to support backward compatibility after making updates to the code base. Versioning also refers to the ability to recall and support previous iterations of models during a project’s lifecycle.
- The ability to automatically choose the best algorithm for each model. During hyperparameter tuning, implementations from different machine learning libraries are used in various combinations and the results evaluated.
- The ability to rapidly incorporate new NLP features by standardizing the developer-facing components. This provides an insulation layer that makes it unnecessary for our feature engineers and data scientists to learn how to interact with a new tool.
- The ability to deploy in any environment. We are currently using Docker containers on EC2 instances, but our architecture means that we can also take advantage of the burst capabilities that services such as Amazon Lambda provide.
-
A single save and load framework based on generic
InputStreams&OutputStreams, which frees us from the requirement of reading and writing to and from disk. - A logging abstraction in the form of slf4j, which insulates us from being tied to any particular framework.
Faster, flexible performant systems
NLP differs from other forms of machine learning because it operates directly on human-generated data. This is often messier than machine-generated data, since language is inherently ambiguous, which results in highly variable interpretability—even among humans. Our goal is to automate as much of the NLP pipeline as possible so that resources are used more efficiently: machines help humans, help machines, help humans. To accomplish this across language barriers, we’re using tools such as Spark to build performant systems that are faster and more flexible than ever before.