 Front of a blue IBM-style punch card. (source: Wikimedia Commons)
Front of a blue IBM-style punch card. (source: Wikimedia Commons) “Small pieces loosely joined,” David Weinberger’s appealing theory of the Web, has much to say to programmers as well. It always inspires me to reduce the size of individual code components. The hard part, though, is rarely the “small” – it’s the “loose”.
After years of watching and wondering, I’m starting to see a critical mass of developers working within approaches that value loose connections. The similarities may not be obvious (or even necessarily welcome) to practitioners, but they share an approach of applying encapsulation to transformations, rather than data. Of course, as all of these are older technologies, the opportunity has been there for a long time.
The return of flow-based programming
No Flo and its successful Kickstarter to create a unique visual environment for JavaScript programming reawakened broader interest in flow-based programming. FBP goes back to the 1970s, and breaks development into two categories:
“There’s two roles: There’s the person building componentry, who has to have experience in a particular program area, and there’s the person who puts them together,” explains Morrison. “And it’s two different skills.”
That separation of skills – programmers creating separate black box transformations and less-programmery people defining how to fit the transformations together – created a social problem for the approach. (I still hear similar complaints about the designer/programmer roles for web development.)
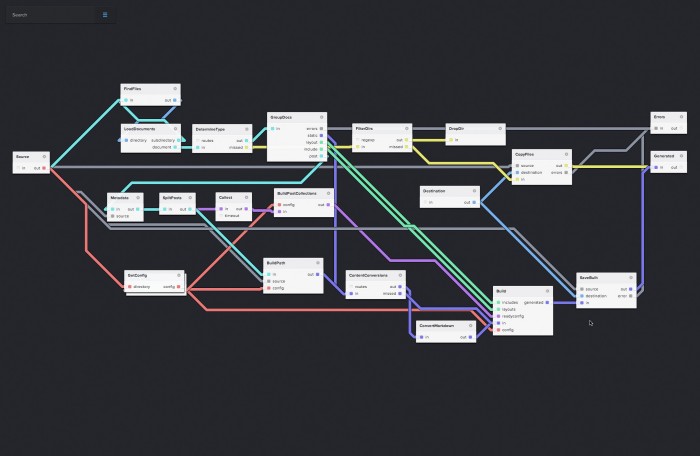
The map-like pictures that are drawing people to NoFlo, like this one for NoFlo Jekyll, show how the transformations connect, how the inputs and outputs are linked. I like the pictures, I’m not terribly worried that they will descend into mad spaghetti, and this division of labor makes too much sense to me. At the same time, though, it reminds me of a few other things.
Punch cards
Run a stack of punch cards through one program. Take the resulting cards and run them through another program. The programs don’t even have to be one same computer, so long as the second program understands as input the output of the first. The larger flow of the program might well be represented as a map of a physical delivery.

Unix pipes
Sooner or later, every sufficiently fragmented system will look like Unix pipes, feeding the output of one process into the input of another (with a bit of buffering infrastructure). Unix pipes are another old technology. In an early pre-Unix memo, Doug McIlroy took inspiration from flow through a hose:
We should have some ways of coupling programs like garden hose–screw in another segment when it becomes when it becomes necessary to massage data in another way.
Unix pipes certainly make it easier for less advanced developers to take advantage of powerful tools created by experts. Despite that echo, though “less advanced” is still pretty advanced. Unix shell scripting still feels a lot like the programming used for the underlying components, and Unix culture and graphical programming may not be a common mix.
Functional programming
Functional programming gives developers the opportunity to write their code as transformations all the way down to the bottom.
Clean functions – functions without side effects – are effectively pure transformations. Something comes in, something goes out, and the results should be predictable. Functions that create side effects or rely on additional inputs (say, from a database) are more complicated to model, but it’s easier to train programmers to notice that complexity when it’s considered unusual.
The difficulty, of course, is that decomposing programs into genuinely independent components in a fine-grained way is difficult. Many programmers have to re-orient themselves from orthodox object-oriented development, and shift to a world in which data structures are transparent but the behavior – the transformation – is not.
Much of what I loved about learning Erlang was that re-orientation. I could build complex data structures, but they didn’t have behavior. Every program was a series of transformations on data, and Erlang’s process structures and OTP made it possible to create intricate distributed pathways. Those structures are, of course, meant to be described by programmers and don’t likely fit neatly into the diagrams of flow-based programming.
Erlang pushes further than many functional languages in enforcing that separation between data and behavior. Developers coming to FP through, say, Scala or JavaScript, may not notice this distinction at first, but it’s a discipline I’d encourage them to embrace, a transition I’d encourage them to make.
Web services and XML
When I first got into XML, I was thrilled by the open data aspect of it all. Developers could use whatever languages they wanted, and share information between them. The reality, unfortunately, was that such radical openness was terrifying. Companies leaped to get first-mover advantage through standardization, and in particular by standardizing tools for passing information between systems.
I can’t say that these tools quite looked like flow-based programming. Many of the early expectations came from CORBA and object-oriented programming as it was understood in the Java and .NET worlds. I somewhat regret writing about XML-RPC, which at first seemed like a relatively simple way to make a function call to an opaque service. SOAP and the WS-* specifications offered much more sophisticated possibilities. Business Process Execution Language in particular had some similar dreams.
On a simpler level, not attempting to distribute processing, XProc gives developers a set of tools for defining pipelines processing XML information. Basic control structures like for-each, choose, and try help developers pass information between transformations of many kinds. For some cases, XProc offers much the same opportunity as the latest generation of flow-based tools. XSLT is, by definition, a transformation language, and many other XML tools are effectively that as well. XProc makes it easy to connect them.
I’ve also pondered what role REST may play in these conversations. The PUT and DELETE methods are, of course, all about side-effects, and not so much about flow. I don’t yet have a good answer here.
(I also need to study the relationship between this, flow-based programming, and Jackson Structured Programming and Jackson Systems Development, which have come up in a few XML contexts.)
Humans as transformers
So far, all of this sounds really automated. Programs pass around messages, sometimes over networks, and perform transformations. Humans might create inputs or deal with the outputs, but we’re pretty cut out of the conversation.
Humans, however, are extremely versatile if unpredictable transformers. We don’t just create information. We can edit, modify, and check it for sanity. While we may not want to see every step of every transformation – that’s why we write programs after all – there may be cases we do want to see. Error handling is a classic case even in highly automated systems, but flow-based approaches also mesh neatly with human workflows.
Most of the work I’ve seen in this space was built explicitly around human workflows. People create or edit something, put it into a system, and the system then modifies it and maybe passes it to another person or process.
However, even systems built with the assumption that they are primarily computing pipelines can incorporate human input. I was heartened to see Norm Walsh, for example, add a wait for (possibly human) update feature to the XML Calabash XProc tool in response to a request. (I suggested the same thing the next day, after it was already in!)
I’m also intrigued by the growing prominence of Git. While most people use Git as a source code management tool, its foundation is an extremely flexible toolset for recording transformations over time. Is that something that can be incorporated into flow-based programming models? I’m not yet sure, but I want to explore further.
The dots aren’t connected
My encounter with flow-based programming has me re-examining my assumptions about how to write programs and use computers. Many different aspects of computing seem to be converging toward that model, at many different scales and levels of granularity. It’s too soon to know whether this is a coincidence or a sign of things to come. I suspect, though, that we may finally be on the verge of a saner way to organize programs and programming.
Update: I should also note the Flow Based Programming Google Group for more conversation.