 Eye (source: Pixabay)
Eye (source: Pixabay) In the last decade or so, computer vision has made tremendous strides forward, mostly because of developments in deep learning. It is not just that we have new and better algorithms—digital cameras and the web have provided us with a near infinite set of training data. And maybe even more importantly, graphics cards developed for computer gaming turn out to have super computer powers when it comes to training deep neural networks.
This is all good news for anybody wanting to experiment with deep learning and image recognition. All it takes to build a cat versus dog classifier these days is Keras and a Python notebook with 100 lines of code. But doing this doesn’t tell us what computers see.
If we wanted to understand how humans see, we could open their skulls and try to figure out how information flows from the eye’s photoreceptor cells through the visual cortex to the rest of the brain. This would be rather hard, though. It’s much easier to poke that opened-up brain with an electrode until the subject sees the color blue. So, how do we prod a neural net with an electrode?
Modern networks typically consist of a large number of layers stacked on top of each other. The image to be recognized gets fed into the lowest layer, and as the information travels through the network, the image representation becomes more abstract until at the other end, a label comes out and the network says, I see a cat!
Poking a neural network with an electrode boils down to running this process in reverse; rather than showing the network a picture and asking it what it sees, we’re going to give the network some noise and ask it to make changes such that a particular neuron has a maximum activation. The image that does that represents what this particular neuron sees, what a human would report seeing if we prodded that neuron.
Let’s start by loading a pre-trained image-recognition network into Keras:
model = vgg16.VGG16(weights='imagenet', include_top=False) model.summary()
That last statement shows us the structure of the network.
We define a loss function that optimizes the output of the given neuron, then create an iterate Keras function that optimizes toward that by changing the input image. We then start with an image filled with noise and run the iteration 16 times. (All code referred to in this post is available on GitHub as both a standalone script and a Python notebook. See the references at the end of the article.)
loss = K.mean(layer_output[:, :, :, neuron_idx])
grads = K.gradients(loss, input_img)[0]
iterate = K.function([input_img], [loss, grads])
img_data = np.random.uniform(size=(1, 256, 256, 3)) + 128.
for i in range(16):
loss_value, grads_value = iterate([img_data])
img_data += grads_value * step
We can try this on some random neuron and we see some artifacts appear that seem to tickle this specific neuron:

That’s cute! Not quite what I’d imagine brain-surgery-induced hallucinations look like, but it is a start! This neuron was picked from a random layer. Remember as we go through the stacked layers, the abstraction level is supposed to go up. What we can do now is sample neurons from different layers and order them by layer; that way we get an idea of the sort of features that each layer is looking out for:

This aligns nicely with our intuition that abstraction goes up as we traverse the layers. The lowest layers are looking for colors and simple patterns; if you go higher, the patterns become more complex.
Unfortunately, there’s a limit to how far this trick will get us; if you find the bit in the highest layer that represents cat-ness, you can optimize all you want, but no obvious cats will roll out.
We can get more detail, though, by zooming in on the image as we run the optimization function. The idea here is if you optimize an image for neuron activation, it tends to get stuck in a local minimum since there is no good way for it to influence the overall structure of the image. So instead of starting with a full image, we start with a small 64×64 image that we optimize. We then scale the image up a bit and optimize again. Doing this for 20 steps gives us a nice and full result that has a certain plasticity to it.
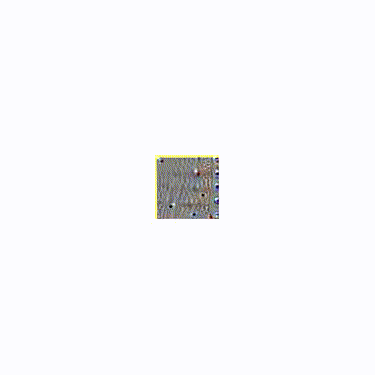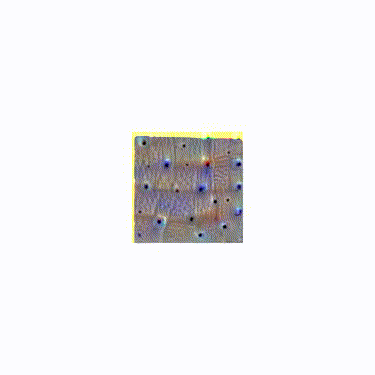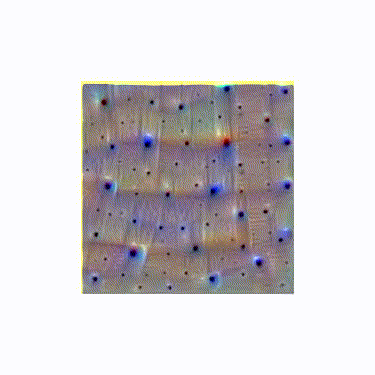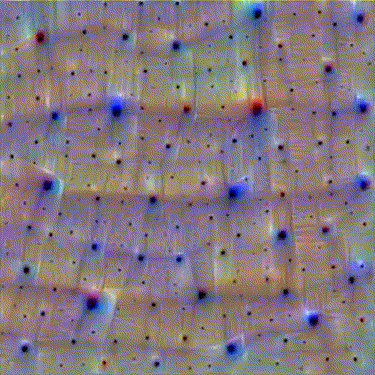
The zooming itself is somehow pleasing, like something organic unfolding.
We can make this into a movie of arbitrary length if we keep zooming, but once we reach a certain size, we also need to start center cropping so the image always remains the same size. This movie has a nice fractal-like mesmerizing effect. But why stop there? We can loop through a set of random neurons while zooming, making for a wonderful acid-like movie:
In this post, we’ve seen some tricks to visualize what a neural network sees. The visualizations are interesting and somehow compelling by themselves, but they also give us an understanding into how computer vision works. As information flows through, the level of abstraction increases, and we can to some extent show those abstractions.
The notebook version of the code can be found on GitHub. A script-based version can be found on GitHub as well.