
 Floor-scrapers, Gustave Courbet (2nd version). 1876 (source: Wikipedia)
Floor-scrapers, Gustave Courbet (2nd version). 1876 (source: Wikipedia) As I’ve written in previous posts, data preparation and data enrichment are exciting areas for entrepreneurs, investors, and researchers. Startups like Trifacta, Tamr, Paxata, Alteryx, and CrowdFlower continue to innovate and attract enterprise customers. I’ve also noticed that companies — that don’t specialize in these areas — are increasingly eager to highlight data preparation capabilities in their products and services.
During a recent episode of the O’Reilly Data Show Podcast, I spoke with Ihab Ilyas, professor at the University of Waterloo and co-founder of Tamr. We discussed how he started working on data cleaning tools, academic database research, and training computer science students for positions in industry.
Academic database research in data preparation
Given the importance of data integrity, it’s no surprise that the database research community has long been interested in data preparation and data wrangling. Ilyas explained how his work in probabilistic databases led to research projects in data cleaning:
In the database theory community, these problems of handling, dealing with data inconsistency, and consistent query answering have been a celebrated area of research. However, it has been also difficult to communicate these results to industry. And database practitioners, if you like, they were more into the well-structured data and assuming a lot of good properties around this data, [and they were also] more interested in indexing this data, storing it, moving it from one place to another. And now, dealing with this large amount of diverse heterogeneous data with tons of errors, sidled across all business units in the same enterprise became a necessity. You cannot really avoid that anymore. And that triggered a new line of research for pragmatic ways of doing data cleaning and integration. … The acquisition layer in that stack has to deal with large sets of formats and sources. And you will hear about things like adapters and source adapters. And it became a market on its own, how to get access and tap into these sources, because these are kind of the long tail of data.
…
The way I came into this subject was also funny because we were talking about the subject called probabilistic databases and how to deal with data uncertainty. And that morphed into trying to find data sets that have uncertainty. And then we were shocked by how dirty the data is and how data cleaning is a task that’s worth looking at.
Human-in-the-loop systems prevail
As data volume and variety grow, automation becomes necessary. In practice, many systems still combine human experts with algorithms. Ilyas explained that active learning is the right model, and the challenge is to find the right balance between human experts and automatic systems:
We have been, especially in academia, thinking about automating the data cleaning process as a mandate, as something exciting to do. … But the reality is, nobody will adopt a fully automated cleaning where the machines mess with the data without the custodians’ and the stewards’ approval, and without somebody who is using this data to tell us about how it would be used and how clean is clean. One of the innovations that I think is very fundamental to Tamr technology is how to judiciously involve the user. … In fact, humans can be in the loop driving the machine and being involved at the right time point where the machine needs guidance, when the machine needs approval, when the machine needs verification. So, the ability to have this full synergy between different roles of users and experts and the machine learning that can do the mundane tasks and find some insights is really crucial and also exciting.
Challenging machine learning tasks
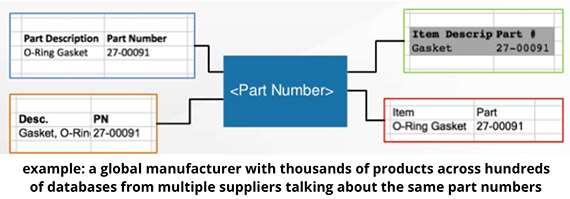
Data scientists searching for challenging, high-impact problems, should consider data cleaning problems. Ilyas noted that entity resolution, classification, and clustering at large scale (both in volume and variety) have practical applications in this area:
We’re employing a lot of classifiers to tell us, for example, that ‘this column is highly related to this other column’ or ‘this source is highly related to this other source.’ So, it’s a well-understood classification process. And as our audience knows, that with this machine learning and classification, we need training [data]. We need [data] to tell the machine a lot of examples of what constitutes a resemblance of similarity or connection. … So, it’s a classification process and there are other, also standard, techniques like clustering that we use heavily as well, to be able to represent collections of things that represent a single real-world entity, entity [resolution], and things like that. … So, how, in a top-down fashion, [do we] discover what the global schema will be? … Top-down, discover what will be the clusters of what we think represent the same real-world entity, and how to run that by custodians and stewards to verify it and then help [facilitate] a process that would provide eventually one representation at the right granularity?
You can listen to our entire interview in the SoundCloud player above, or subscribe through Stitcher, SoundCloud, TuneIn, or iTunes.
This post is part of a collaboration between O’Reilly and Tamr. See our statement of editorial independence.