
 QR Dome by Russia at the thirteenth International Architecture Edition, Venice Biennale (source: Jérémy Lelièvre/Flickr)
QR Dome by Russia at the thirteenth International Architecture Edition, Venice Biennale (source: Jérémy Lelièvre/Flickr) Data processing in the enterprise goes very swiftly from “good enough” to “we need to be faster!” as expectations grow. The Zeta Architecture is an enterprise architecture that enables simplified business processes and defines a scalable way for increasing the speed of integrating data into the business. Following a bit of history and a description of the architecture, I’ll use Google as an example and look at the way the company deploys technologies for Gmail.
Origin story and motivation
I’ve worked on a variety of different information systems over my career, each with their own classes of challenge. The most interesting from a capacity perspective was for a company that delivers digital advertising. The biggest technical problems in that industry flow from the sheer volume of transactions that occur on a daily basis. Traffic flows in all hours of the day, but there are certainly peak periods, which means all planning must revolve around the capacity during the peak hours. This solution space isn’t altogether different than that of Amazon; they had to build their infrastructure to handle massive loads of peak traffic. Both Amazon and digital advertising, incidentally, have a Black Friday spike.
Many different architectural ideas came to my mind while I was in digital advertising. Real-time performance tracking of the advertising platform was one such thing. This was well before real-time became a hot buzzword in the technology industry. There was a point in time where this digital advertising company was “satisfied” with, or perhaps tolerated, having a two-to-three-hour delay between making changes to the system and having complete insight into the effects of the changes. After nearly a year at this company, I was finally able to get a large architectural change made to streamline log collection and management. Before the implementation started, I told everyone involved what would happen. Although this approach would enable the business to see the performance within approximately 5-10 minutes of the time a change was made, that this would not be good enough after people got a feel for what real-time could deliver. Since people didn’t have that taste in their mouths, they wouldn’t yet support going straight to real-time for this information. The implementation of this architecture was in place a few months after I departed the company for a new opportunity. The implementation worked great, and after about three months of experience with the new architecture, my former colleagues contacted me and told me they were looking to re-architect the entire solution to go to real time.
You might be wondering why I have decided to share this anecdote. It’s simple: “Good enough” doesn’t exist when it comes to technology. It is just a matter of time before people want more and faster. I predicted that my colleagues’ expectations would quickly change, and it proved to be true.
All of those expectations got me thinking, “what could I do to protect against those new expectations that I knew were bound to happen?” Over the following few months, I worked through the ramifications to all the pieces of an enterprise architecture to help solve this. But there was still something missing. I couldn’t put my finger on it until I attended 2014 MesosCon in Chicago. Finally, the last piece of my architecture was sitting in front of me. I was missing global resource management. When I added that in, it opened up new doors and new ways to benefit from the rest of the pieces of my architecture. Suddenly it hit me: the strategic combination of all of these pieces was greater than the sum of each of the parts.
High-level components with descriptions
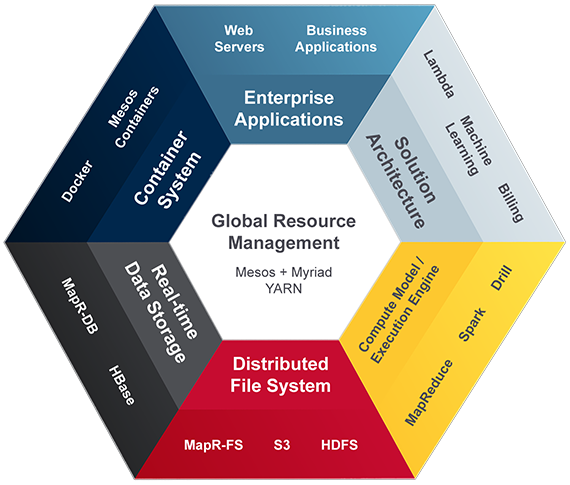
The high-level component view of this architecture is intended to support the goals defined for this new architecture. It is not intended to dictate which specific software or project, open source or otherwise, that must be used. There are seven pluggable components of this new architecture, and all of the components must work together:
- Distributed file system — Utilizing a shared distributed file system, all applications will be able to read and write to a common location, which enables simplification of the rest of the architecture.
- Real-time data storage — This supports the need for high-speed business applications through the use of real-time databases.
- Pluggable compute model / execution engine — Different groups within a business have different needs and requirements for meeting the demands put upon them at any given time, which requires the support of potentially different engines and models to meet the needs of the business.
- Deployment / container management system — The need for having a standardized approach for deploying software are important and all resource consumers should be able to be isolated and deployed in a standard way.
- Solution architecture — This focuses on solving a particular business problem. There may be one or more applications built to deliver the complete solution. These solution architectures generally encompass a higher level interaction amongst common algorithms or libraries, software components, and business workflows. All too often, solution architectures are folded into enterprise architectures, but there is a clear separation with the Zeta Architecture.
- Enterprise applications — In the past, these applications would drive the rest of the architecture. However, in this new model, there is a shift. The rest of the architecture now simplifies these applications by delivering the components necessary to realize all of the business goals we are defining for this architecture.
- Dynamic and global resource management — Allows dynamic allocation of resources to enable the business to easily accommodate for whatever task is the most important today.
After putting all of my ideas on paper, there were two things I still needed to do: design a visual representation to explain this architecture and, most importantly, name it. After finally coming up with a visual representation that was simple to understand, a name finally came to me. Thus was the Zeta Architecture begotten (I’ll tell you the way I came up with the name in a future post).
While thinking through the visuals and implementation details of this architecture, something else hit me. I stumbled upon a way to document Google’s architecture. I’ve never seen Google document what I will call their enterprise architecture, but this is it. This diagram maps out how Google operates its technology stack, with Gmail as a use case. This architecture will allow anyone who implements it to be able to run at Google scale and efficiency.
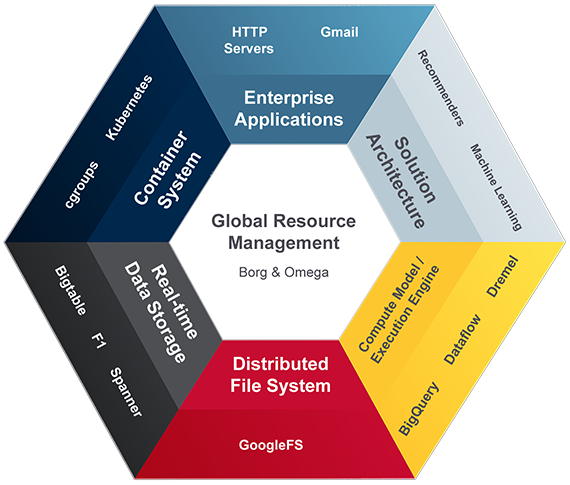
There are a couple of the interesting points about Google’s technologies in this diagram. Borg is sometimes referred to as the project that is unnamed within Google, but outside of Google, it’s called Borg. Omega is their scheduler, and it is the crux of their dynamic distributed resource management. It figures out where and when to place jobs. Google has mentored open source projects like Apache Mesos, which takes many cues from Omega. From a solution architecture perspective, Gmail conceptually operates on top of a recommendation engine. The machine learning concepts in general are delivered in many of the products Google offers.
What else?
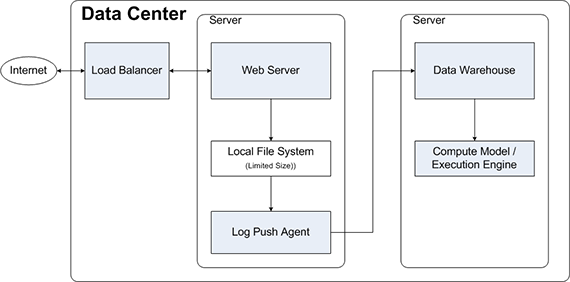
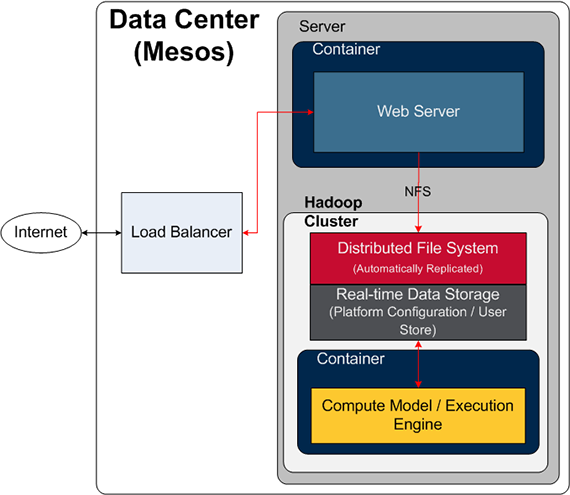
Web servers generate logs, they land on a local disk, and the logs are periodically rotated so they can be shipped elsewhere. They are moved to some other servers for data processing, and then jobs are run on the logs. This is a pretty standard story, and it isn’t so bad at small scale, but a lot of work goes into log shipping at scale. So, how could we make it better? We should run the distributed file system across all of these servers that are running Web servers. Logs would still get generated, but now they would land on the distributed file system. No other changes required, log shipping goes away, and the data is immediately available to the compute model / execution engine for analytics or any other process the business needs. There is a lot less monitoring required from the IT operations perspective.
If logs don’t have to be shipped, then technologies like Flume or Kafka can be removed from some application architectures. This does not obsolete those technologies; instead, those technologies should be used for use cases where streaming or queuing data makes sense. Overall, this is a big process simplification. In the anecdote I shared at the beginning of this article, we used Flume as the solution. My coworkers were able to configure and tune Flume to handle more than 1.5 million log lines per second, sustained throughout the day, and it worked fine. There were only hundreds or thousands of hours put into designing and building the solution, and then of course, managing it and maintaining the code base and configuration for deployment. Of course, we can’t forget that it also needed to be monitored. All of those things become unnecessary with the Zeta Architecture, at least for this use case.
Less is more
Nearly every application architecture needs to concern itself with many different things, including data protection schemes, how to backup data, recovery from failures, load balancing, and even running multiple versions of software. The Zeta Architecture simplifies those application architectures because it delivers or supports those important issues. Fewer moving parts means fewer potential failure points. Better hardware utilization means less to operate and lower operational costs. The business is then capable of leveraging a global set of resources to solve any problem based on what is most important right now. These days, priority number one seems to change fast and often, and this architecture supports a business that needs to change things instantly.
Additional materials
If you’re interested in learning more, I have written a free downloadable technical white paper documenting the Zeta Architecture. I have also written a free downloadable executive summary titled Building the Data-Centric Enterprise that covers this topic.