
 Portland General Electric's Salem Smart Power Center includes a large-scale energy storage system. (source: Portland General Electric on Flickr)
Portland General Electric's Salem Smart Power Center includes a large-scale energy storage system. (source: Portland General Electric on Flickr) This post is about using Apache Cassandra for analytics. Think time series, IoT, data warehousing, writing, and querying large swaths of data—not so much transactions or shopping carts. Users thinking of Cassandra as an event store and source/sink for machine learning / modeling / classification would also benefit greatly from this post.
Two key questions when considering analytics systems are:
- How much storage do I need (to buy)?
- How fast can my questions get answered?
I conducted a performance study, comparing different storage layouts, caching, indexing, filtering, and other options in Cassandra (including FiloDB), plus Apache Parquet, the modern gold standard for analytics storage. All comparisons were done using Spark SQL. More importantly than determining data modeling versus storage format versus row cache or DeflateCompressor, I hope this post gives you a useful framework for predicting storage cost and query speeds for your own applications.
I was initially going to title this post, “Cassandra vs Hadoop,” but honestly, this post is not about Hadoop or Parquet at all. Let me get this out of the way, however, because many people, in their evaluations of different technologies, are going to think about one technology stack versus another. Which is better for which use cases? Is it possible to lower total cost of ownership (TCO) by having just one stack for everything? Answering the storage and query cost questions are part of this analysis. To be transparent, I am the author of FiloDB. While I do have much more vested on one side of this debate, I will focus on the analysis and let you draw your own conclusions. However, I hope you will realize that Cassandra is not just a key-value store; it can be—and is being—used for big data analytics, and it can be very competitive in both query speeds and storage costs.
Wide spectrum of storage costs and query speeds
Figure 1 summarizes different Cassandra storage options, plus Parquet. Farther to the right denotes higher storage densities, and higher up the chart denotes faster query speeds. In general, you want to see something in the upper right corner.
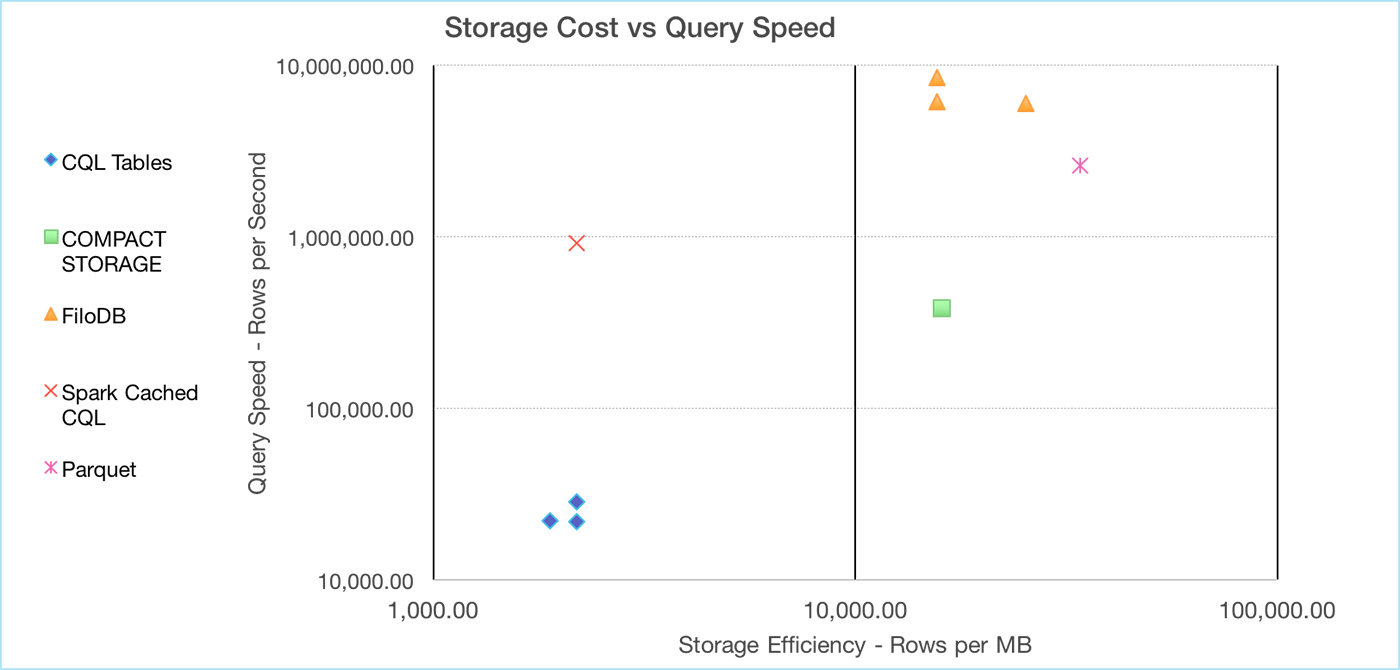
Here is a brief introduction to the different players used in the analysis:
- Regular Cassandra 2.x CQL tables, in both narrow (one record per partition) and wide (both partition and clustering keys, many records per partition) configurations
- COMPACT STORAGE tables, the way all of us Cassandra old timers did it before CQL (0.6, baby!)
- Caching Cassandra tables in Spark SQL
- FiloDB, an analytical database built on C* and Spark
- Parquet, the reference gold standard
What you see in Figure 1 is a wide spectrum of storage efficiency and query speed, from CQL tables at the bottom to FiloDB, which is up to 5x faster in scan speeds than Parquet and almost as efficient storage-wise. Keep in mind that the chart above has a log scale on both axes. Also, while this article will go into the tradeoffs and details about different options in depth, we will not be covering the many other factors people will choose CQL tables for, such as support for modeling maps, sets, lists, custom types, and many other things.
Summary of methodology for analysis
Query speed was computed by averaging the response times for three different queries:
df.select(count(“numarticles”)).show
SELECT Actor1Name, AVG(AvgTone) as tone FROM gdelt GROUP BY Actor1Name ORDER BY tone DESC
SELECT AVG(avgtone), MIN(avgtone), MAX(avgtone) FROM gdelt WHERE monthyear=198012
The first query is an all-table-scan simple count. The second query measures a grouping aggregation. And the third query is designed to test filtering performance with a record count of 43.4K items, or roughly 1% of the original data set. The data set used for each query is the GDELT public data set: 1979-1984, 57 columns x 4.16 million rows, recording geopolitical events worldwide. The source code for ingesting the Cassandra tables and instructions for reproducing the queries are available in my cassandra-gdelt repo.
The storage cost for Cassandra tables is computed by running compaction first, then taking the size of all stable files in the data folder of the tables.
To make the Cassandra CQL tables more performant, shorter column names were used (for example, a2code instead of Actor2Code).
All tests were run on my Macbook Pro 15” Mid-2015, SSD / 16GB. Specifics are as follows:
- Cassandra 2.1.6 installed using CCM
- Spark 1.4.0 except where noted, run with master = ‘local[1]’ and spark.sql.shuffle.partitions=4
- Spark-Cassandra-Connector 1.4.0-M3
Running all the tests essentially single threaded was done partly out of simplicity and partly to form a basis for modeling performance behavior (see the modeling query performance section below).
Scan speeds are dominated by storage format
OK, let’s dive into details! The key to analytics query performance is the scan speed, or how many records you can scan per unit time. This is true for whole table scans, and it is true when you filter data, as we’ll see later. Figure 2 below shows the data for all query times, which are whole table scans, with relative speed factors for easier digestion:
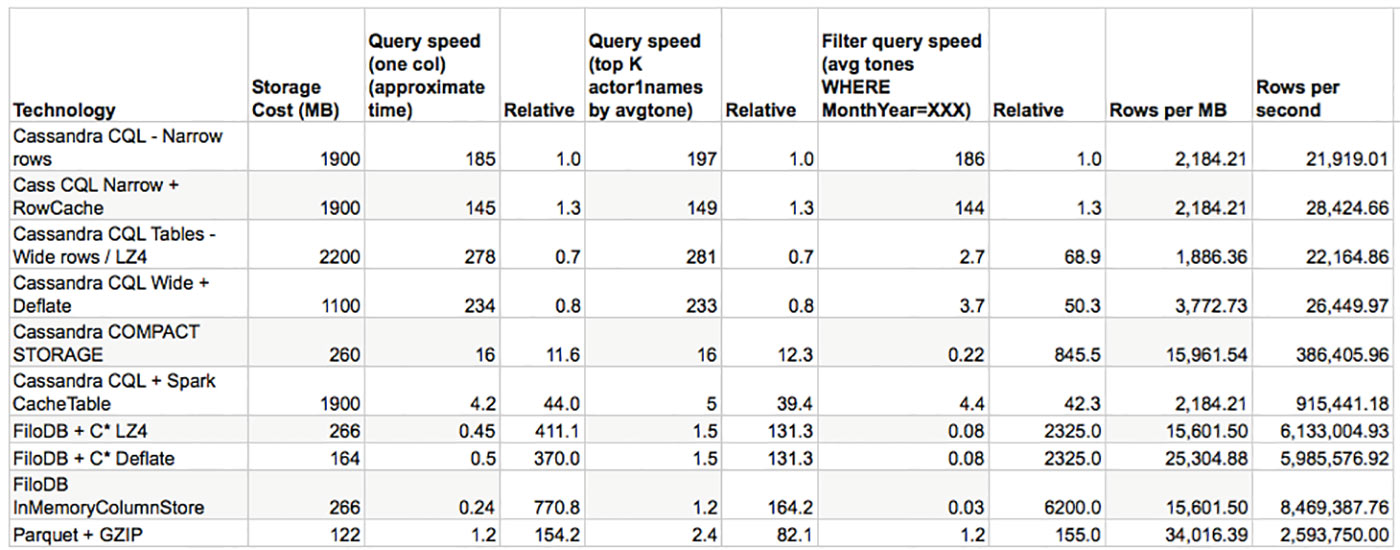
NOTE: to get more accurate scan speeds, one needs to subtract the baseline latency in Spark, but this is left out for simplicity. This actually slightly disfavors the fastest contestants.
Cassandra’s COMPACT STORAGE gains an order-of-magnitude improvement in scan speeds simply due to more efficient storage. FiloDB and Parquet gain another order of magnitude due to a columnar layout, which allows reading only the columns needed for analysis, plus more efficient columnar blob compression. Thus, storage format makes the biggest difference in scan speeds. More details are below, but for regular CQL tables, the scan speed should be inversely proportional to the number of columns in each record, assuming simple data types (not collections).
Part of the speed advantage of FiloDB over Parquet has to do with the InMemory option. You could argue this is not fair; however, when you read Parquet files repeatedly, most of that file is most likely in the OS Cache anyway. Yes, having in-memory data is a bigger advantage for networked reads from Cassandra, but I think part of the speed increase is because FiloDB’s columnar format is optimized more for CPU efficiency, rather than compact size. Also, when you cache Parquet files, you are caching an entire file or blocks thereof, compressed and encoded; FiloDB relies on small chunks, which can be much more efficiently cached (on a per-column basis, and allows for updates). Folks at Databricks have repeatedly told me that caching Parquet files in-memory did not result in significant speed gains, and this makes sense due to the format and compression.
Wide row CQL tables are actually less efficient than narrow row due to additional overhead of clustering column name prefixing. Spark’s cacheTable should be nearly as efficient as the other fast solutions, but suffers from partitioning issues.
Storage efficiency generally correlates with scan speed
In Figure 2, you can see that these technologies list in the same order for storage efficiency as for scan speeds, and that’s not an accident. Storing tables as COMPACT STORAGE and FiloDB yields a roughly 7-8.5x improvement in storage efficiency over regular CQL tables for this data set. Less I/O = faster scans!
Cassandra CQL wide row tables are less efficient, and you’ll see why in a minute. Moving from LZ4 to Deflate compression reduces storage footprint by 38% for FiloDB and 50% for the wide row CQL tables, so it’s definitely worth considering. DeflateCompressor actually sped up wide row CQL scans by 15%, but slowed down the single partition query slightly.
Why Cassandra CQL tables are inefficient
Let’s say a Cassandra CQL table has a primary key that looks like (pk, ck1, ck2, ck3) and other columns designated c1, c2, c3, c4 for creativity. This is what the physical layout looks like for one partition (“physical row”):
| Column header | ck1:ck2:ck3:c1 | ck1:ck2:ck3:c2 | ck1:ck2:ck3:c3 | ck1:ck2:ck3:c4 | ck1:ck2:ck3a:c1 | ck1:ck2:ck3a:c2 | ck1:ck2:ck3a:c3 | ck1:ck2:ck3a:c4 |
| pk : value | v1 | v2 | v3 | v4 | v1 | v2 | v3 | v4 |
Cassandra offers ultimate flexibility in terms of updating any part of a record, as well as inserting into collections, but the price paid is that each column of every record is stored in its own cell, with a very lengthy column header consisting of the entire clustering key, plus the name of each column. If you have 100 columns in your table (very common for data warehouse fact tables), then the clustering key ck1:ck2:ck3 is repeated 100 times. It is true that compression helps a lot with this, but not enough. Cassandra 3.x has a new, trimmer storage engine that does away with many of these inefficiencies, at a reported space savings of up to 4x.
COMPACT STORAGE is the way that most of us who used Cassandra prior to CQL stored our data: as one blob per record. It is extremely efficient. That model looks like this:
| Column header | ck1:ck2:ck3 | ck1:ck2:ck3a |
| pk | value1_blob | value2_blob |
You lose features such as secondary indexing, but you can still model your data for efficient lookups by partition key and range scans of clustering keys.
FiloDB, on the other hand, stores data by grouping columns together, and then by clumping data from many rows into its own efficient blob format. The layout looks like this:
| Column 1 | Column 2 | |||
|---|---|---|---|---|
| pk | Chunk 1 | Chunk 2 | Chunk 1 | Chunk 2 |
Columnar formats minimize I/O for analytical queries, which select a small subset of the original data. They also tend to remain compact even in-memory. FiloDB’s internal format is designed for fast random access without the need to deserialize. On the other hand, Parquet is designed for very fast linear scans, but most encoding types require the entire page of data to be deserialized—thus, filtering will incur higher I/O costs.
A formula for modeling query performance
We can model the query time for a single query using a simple formula:
Predicted queryTime = Expected number of records / (# cores * scan speed)
Basically, the query time is proportional to how much data you are querying, and inversely proportional to your resources and raw scan speed. Note that the scan speed above is single-core scan speed, such as was measured using my benchmarking methodology. Keep this model in mind when thinking about storage formats, data modeling, filtering, and other effects.
Can caching help? A little bit.
If storage size leads partially to slow scan speeds, what about taking advantage of caching options to reduce I/O? Great idea. Let’s review the different options.
- Cassandra row cache: I tried row cache of 512MB for the narrow CQL table use case—512MB was picked as it was a quarter of the size of the data set on disk. Most of the time your data won’t fit in cache. This increased scan speed for the narrow CQL table by 29%. If you tend to access data at the beginning of your partitions, row cache could be a huge win. What I like best about this option is that it’s really easy to use and brain-dead simple, and it works with your changing data.
- DSE has an in-memory tables feature. Think of it, basically, as keeping your SSTables in-memory instead of on disk. It seems to me to be slower than row cache (since you still have to decompress the tables), and I’ve been told it’s not useful for most people.
- Finally, in Spark SQL you can cache your tables (CACHE TABLE in spark-sql, sqlContext.cacheTable in spark-shell) in an on-heap, in-memory columnar format. It is really fast (44x speedup over base case above), but suffers from multiple problems: the entire table has to be cached, it cannot be updated, and it is not HA (once any executor or the app dies, ka-boom!). Furthermore, you have to decide what to cache, and the initial read from Cassandra is still really slow.
None of the above options are anywhere close to the wins that better storage format and effective data modeling will give you. As my analysis shows, FiloDB, without caching, is faster than all Cassandra caching options. Of course, if you are loading data from different data centers or constantly doing network shuffles, then caching can be a big boost, but most Spark on Cassandra setups are collocated.
The Future: Optimizing for CPU, not I/O
For Spark queries over regular Cassandra tables, I/O dominates CPU due to the storage format. This is why the storage format makes such a big difference, and also why technologies like SSD have dramatically boosted Cassandra performance. Due to the dominance of I/O costs over CPU, it may be worth it to compress data more. For formats like Parquet and FiloDB, which are already optimized for fast scans and minimized I/O, it is the opposite—the CPU cost of querying data actually dominates over I/O. That’s why the Spark folks are working on code-gen and Project Tungsten.
If you look at the latest trends, memory is getting cheaper; NVRAM, 3DRAM, and very cheap persistent DRAM technologies promise to make I/O bandwidth no longer an issue. This trend obliterates decades of database design based on the assumption that I/O is much, much slower than CPU, and instead favors CPU-efficient storage formats. With the increase in IOPs, optimizing for linear reads is no longer quite as important.
Filtering and data modeling
Remember our formula for predicting query performance:
Predicted queryTime = Expected number of records / (# cores * scan speed)
Correct data modeling in Cassandra deals with the first part of that equation—enabling fast lookups by reducing the number of records that need to be looked up. Denormalization, writing summaries instead of raw data, and being smart about data modeling all help reduce the number of records. Partition and clustering key filtering are definitely the most effective filtering mechanisms in Cassandra. Keep in mind, though, that scan speeds are still really important, even for filtered data—unless you are really doing just single-key lookups.
Look back at Figure 2. What do you see? Using partition key filtering on wide row CQL tables proved very effective—100x faster than scanning the whole wide row table on 1% of the data (a direct plugin in the formula of reducing the number of records to 1% of original). However, since wide rows are a bit inefficient compared to narrow tables, some speed is lost. You can also see in Figure 2 that scan speeds still matter. FiloDB’s in-memory execution of that same filtered query was still 100x faster than the Cassandra CQL table version—taking only 30 milliseconds as opposed to nearly three seconds. Will this matter? For serving concurrent, Web-speed queries it will certainly matter.
Note that I only modeled a very simple equals predicate, but in reality, many people need much more flexible predicate patterns. Due to the restrictive predicates available for partition keys (= only for all columns except last one, which can be IN), modeling with regular CQL tables will probably require multiple tables, one each to match different predicate patterns. (This is being addressed in C* 2.2 a bit, maybe more in 3.x) This needs to be accounted for in the storage cost and TOC analysis. One way around this is to store custom index tables, which allows application-side custom scan patterns. FiloDB uses this technique to provide arbitrary filtering of partition keys.
Some notes on the filtering and data modeling aspect of my analysis:
- The narrow rows layout in CQL is one record per partition key, thus partition key filtering does not apply. See discussion of secondary indices below.
- Cached tables in Spark SQL, as of Spark 1.5, only does whole table scans. There might be some improvements coming, though—see SPARK-4849 in Spark 1.6.
- FiloDB has roughly the same filtering capabilities as Cassandra—by partition key and clustering key—but improvements on the partition key filtering capabilities of C are planned.
- It is possible to partition your Parquet files and selectively read them, and it is supposedly possible to sort your files to take advantage of intra-file filtering. That takes extra effort, and since I haven’t heard of anyone doing the intra-file sort, I deemed it outside the scope of this study. Even if you were to do this, the filtering would not be anywhere near as granular as is possible with Cassandra and FiloDB—of course, your comments and enlightenment are welcome here.
Cassandra’s secondary indices usually not worth it
How do secondary indices in Cassandra perform? Let’s test that with two count queries with a WHERE clause on Actor1CountryCode, a low cardinality field with a hugely varying number of records in our portion of the GDELT data set:
- WHERE Actor1CountryCode = ‘USA’: 378k records (9.1% of records)
- WHERE Actor1CountryCode = ‘ALB’: 5005 records (0.1% of records)
| Large country | Small country | 2i Scan Rate | |
|---|---|---|---|
| Narrow CQL Table | 28s / 6.6x | 0.7s / 264x | 13.5k records/sec |
| CQL Wide Rows | 143s / 1.9x | 2.7s / 103x | 2643 records/sec |
If secondary indices were perfectly efficient, one would expect query times to reduce linearly with the drop in the number of records. Alas, this is not so. For the CountryCode = USA query, one would expect a speedup of around 11x, but secondary indices proved very inefficient, especially in the wide rows case. Why is that? Because for wide rows, Cassandra has to do a lot of point lookups on the same partition, which is very inefficient and results in only a small drop in the I/O required (in fact, much more random I/O), compared to a full table scan.
Secondary indices work well only when the number of records is reduced to such a small amount that the inefficiencies do not matter and Cassandra can skip most partitions. There are also other operational issues with secondary indices, and they are not recommended for use when the cardinality goes above 50,000 items or so.
Predicting your own data’s query performance
How should you measure the performance of your own data and hardware? It’s really simple, actually:
- Measure your scan speed for your base Cassandra CQL table. Number of records / time to query, single threaded
- Use the formula earlier—Predicted queryTime = Expected number of records / (# cores * scan speed)
- Use relative speed factors above for predictions
The relative factors above are based on the GDELT data set with 57 columns. The more columns you have (data warehousing applications commonly have hundreds of columns), the greater you can expect the scan speed boost for FiloDB and Parquet. (Again, this is because, unlike for regular CQL/row-oriented layouts, columnar layouts are generally insensitive to the number of columns.) It is true that concurrency (within a single query) leads to its own inefficiencies, but in my experience, that is more like a 2x slowdown, and not the order-of-magnitude differences we are modeling here.
User concurrency can be modeled by dividing the number of available cores by the number of users. You can easily see that in FAIR scheduling mode, Spark will actually schedule multiple queries at the same time (but be sure to modify fair-scheduler.xml appropriately). Thus, the formula becomes:
Predicted queryTime = Expected number of records * # users / (# cores * scan speed)
There is an important case where the above formula needs to be modified, and that is for single-partition queries (for example, where you have a WHERE clause with an exact match for all partition keys, and Spark pushes down the predicate to Cassandra). The above formula assumes that the queries are spread over the number of nodes you have, but this is not true for single-partition queries. In that case, there are two possibilities:
- The number of users is less than the number of available cores. Then, the query time = number_of_records / scan_speed.
- The number of users is >= the number of available cores. In that case, the work is divided amongst each core, so the original query time formula works again.
Conclusions
Apache Cassandra is one of the most widely used, proven, and robust distributed databases in the modern big data era. The good news is that there are multiple options for using it in an efficient manner for ad-hoc, batch, time-series analytics applications.
For (multiple) order-of-magnitude improvements in query and storage performance, consider the storage format carefully, and model your data to take advantage of partition and clustering key filtering/predicate pushdowns. Both effects can be combined for maximum advantage—using FiloDB plus filtering data improved a three-minute CQL table scan to sub-100ms response times. Secondary indices are helpful only if they filter your data down to, say, 1% or less—and even then, consider them carefully. Row caching, compression, and other options offer smaller advantages up to about 2x.
If you need a lot of individual record updates, or lookups by individual record, but don’t mind creating your own blob format, the COMPACT STORAGE / single column approach could work really well. If you need fast analytical query speeds with updates, fine-grained filtering and a Web-speed in-memory option, FiloDB could be a good bet. If the formula above shows that regular Cassandra tables, laid out with the best data modeling techniques applied, are good enough for your use case, kudos to you!