Apache Spark: Powering applications on-premise and in the cloud
The O'Reilly Data Show Podcast: Patrick Wendell on the state of the Spark ecosystem.
 Drawing by A.L. Tarter (source: Wellcome Library)
Drawing by A.L. Tarter (source: Wellcome Library)
As organizations shift their focus toward building analytic applications, many are relying on components from the Apache Spark ecosystem. I began pointing this out in advance of the first Spark Summit in 2013 and since then, Spark adoption has exploded.
With Spark Summit SF right around the corner, I recently sat down with Patrick Wendell, release manager of Apache Spark and co-founder of Databricks, for this episode of the O’Reilly Data Show Podcast. (Full disclosure: I’m an advisor to Databricks). We talked about how he came to join the UC Berkeley AMPLab, the current state of Spark ecosystem components, Spark’s future roadmap, and interesting applications built on top of Spark.

Learn faster. Dig deeper. See farther.
User-driven from inception
From the beginning, Spark struck me as different from other academic research projects (many of which “wither away” when grad students leave). The AMPLab team behind Spark spoke at local SF Bay Area meetups, they hosted 2-day events (AMP Camp), and worked hard to help early users. That mindset continues to this day. Wendell explained:
We were trying to work with the early users of Spark, getting feedback on what issues it had and what types of problems they were trying to solve with Spark, and then use that to influence the roadmap. It was definitely a more informal process, but from the very beginning, we were expressly user-driven in the way we thought about building Spark, which is quite different than a lot of other open source projects. We never really built it for our own use — it was not like we were at a company solving a problem and then we decided, “hey let’s let other people use this code for free”. … From the beginning, we were focused on empowering other people and building platforms for other developers, so I always thought that was quite unique about Spark.
Large-scale applications
Unbeknownst to many, the largest Spark deployments are in China. Tencent publicly discussed their 8,000 node Spark cluster at Strata + Hadoop World in San Jose this past February, and other large Chinese companies such as Alibaba and Baidu have shared lessons from running large Spark deployments.
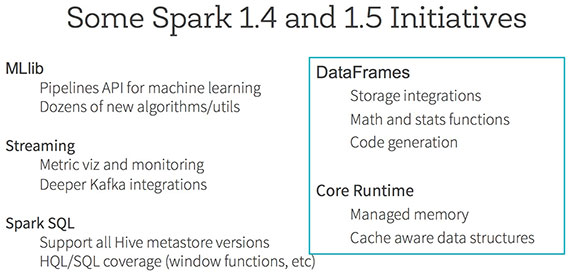
Spark’s ability to support large-scale workloads, along with the maturation of popular components like MLlib, Spark SQL, Spark Streaming, and GraphX, are leading to many interesting applications. Wendell described a few applications built with Spark, some of which are being showcased at Spark Summit SF:
One of them is a major effort around Spark SQL at Microsoft — this is a large internal deployment they’re doing on Spark SQL actually running on Mesos on fairly large clusters. … They’re going to talk about how they’re getting value from Spark SQL and how they use it to turn around and act as an internal analytics service for major parts of the company.
…
The other one I had just seen that was notable was from Airbnb, and it’s from their demand prediction team. You can imagine Airbnb — they’re always trying to understand where they’re going to have more demand for people to stay, and they use MLlib and they do a lot of modeling of this using Spark.
…
Huawei [is doing] some really cool stuff using MLlib. It’s from a telecommunications division in Huawei. They have large telco networks, and these networks have tons and tons of data, terabytes of data every second. What they are trying to do is find hot spots in the network or subpaths or routers that are congested so they can go and try to alleviate the congestion and add more hardware, and that is a complex modeling problem. You have these graphs with maybe thousands of edges in them and a lot of subpaths. What they are using in MLlib is something called Frequent Pattern Matching.
…
[BlinkDB is] not dead. No matter how high performance my engine is, if I need to scan a terabyte of data to answer my query, it’s going to be slow — even if you’re reading from memory. BlinkDB does some really intelligent subsampling, and that is for sure ending up in Spark. I think the timeline is probably more like 1.6 timeframe. Maybe in another one or two releases, that’s maybe six months out. That is absolutely something that we plan to add to Spark.
Cloud becomes more mainstream
AMPLab researchers were early users of Amazon Web Services (AWS), and even early versions of Spark came with scripts for running it on AWS. Fast-forward to today and companies are much more open to deploying applications on public cloud services. Databricks and several other “cloud first” startups are well-positioned to take advantage of this trend. Wendell noted:
I think we’ve really reached a tipping point. If you look at some of the numbers about growth of the S3 storage on AWS, it’s just monumental, exponential growth over the last few years. What is interesting is just more and more, even fairly traditional companies are migrating significant workloads to the cloud. One nice thing is that analytics tends to be the earliest workloads that gets migrated because operational databases [are] a little bit harder to move. There’s a lot of different constraints, but analytical — like historical data and so forth — [is] often a lot easier from a governed perspective for companies to move. A major thing fueling that is the price wars between the major cloud providers — you know it’s not just an Amazon world anymore; you have Azure, you have Google Compute, you have Rackspace, and they are all fighting with each other to decrease prices. That’s starting to look very attractive to companies that are making major infrastructure investments.
…
The AMPLab was one of the very first users of AWS. We were [early] adopters, and it was great for us in a research setting because [we did not] want to invest in a large piece of hardware infrastructure, but we did want to run large scale experiments.
You can listen to our entire interview in the SoundCloud player above, or subscribe through SoundCloud, TuneIn, or iTunes.
For more on the most recent release of Apache Spark, register now and attend an upcoming free webcast featuring Patrick Wendell. If you’re interested in becoming a Certified Apache Spark Developer, visit the Databricks/O’Reilly Spark certification page.