
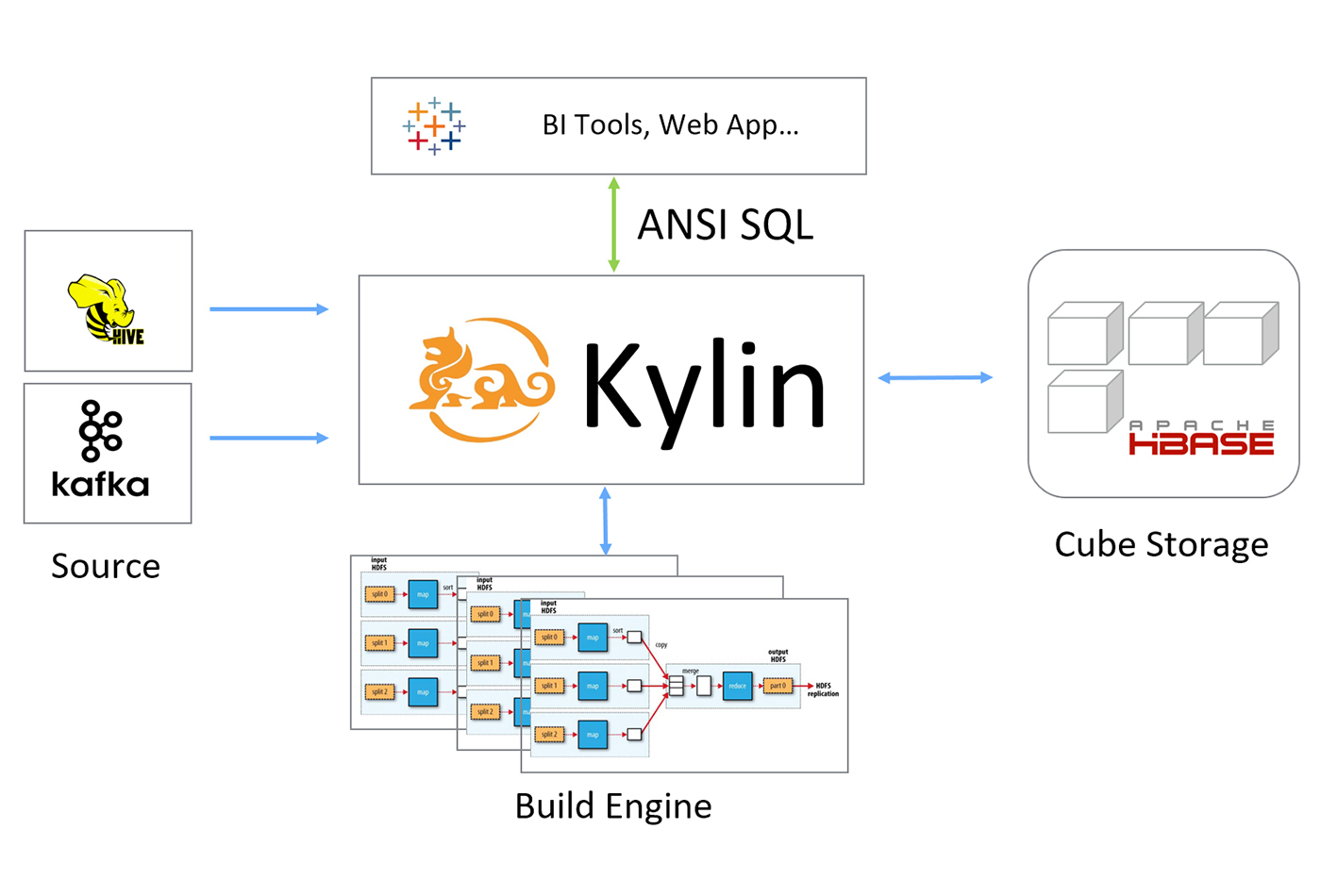
 Apache Kylin architecture.
Apache Kylin architecture. SQL on Hadoop is continuously improving, but it’s still common to wait minutes to hours for a query to return. In this post, we will discuss the open source distributed analytics engine Apache Kylin and examine, specifically, how it speeds up big data query orders, and what some of the features in version 2.0—including snowflake schema support and streaming cubing—mean for interactive BI.
What is Apache Kylin?
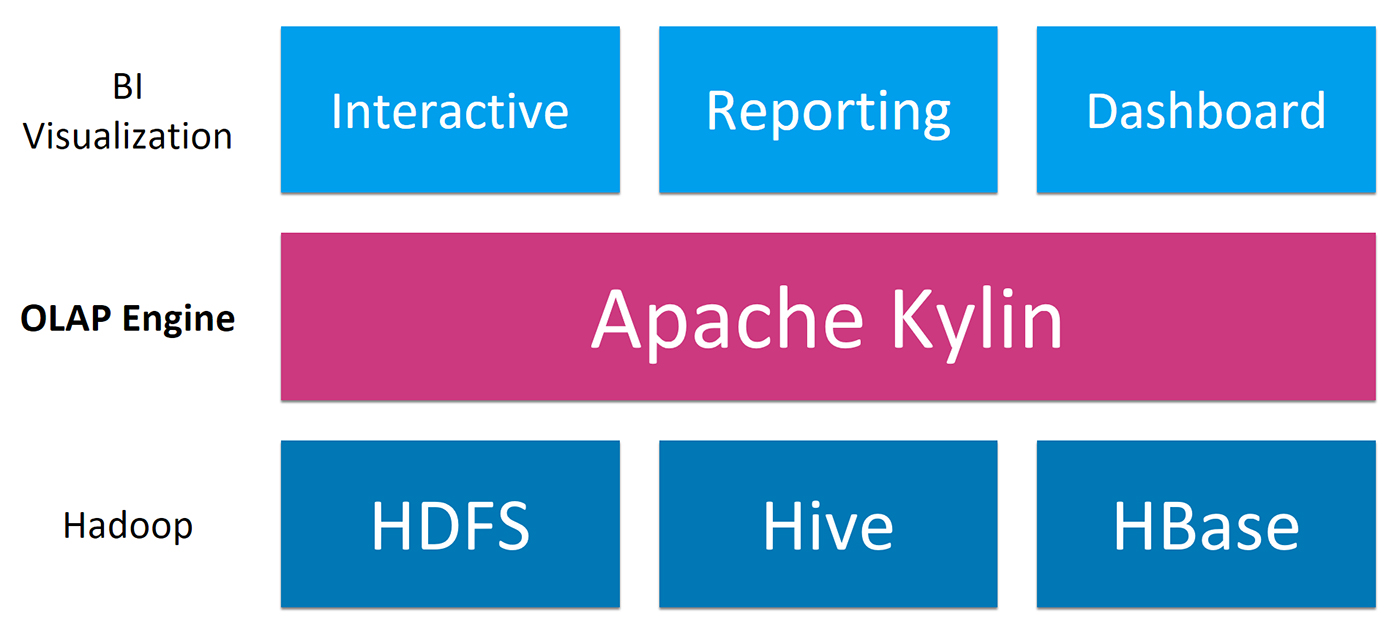
Kylin is an OLAP engine on Hadoop. As shown in Figure 1, Kylin sits on top of Hadoop and exposes relational data to upper applications via the standard SQL interface.
Kylin can handle big data sets and is fast in terms of query latency, which differentiates it from other SQL on Hadoop. For example, the biggest instance of Kylin in production that we’re aware of is at toutiao.com, a news feed app in China. This app has a table of three trillion rows and the average query response time is less than one second. We’ll discuss what makes Kylin so fast in the next section.
Another feature of the Kylin engine is that it can support complex data models. For example, there is a 60-dimension model running at CPIC, an insurance group in China. Kylin provides standard JDBC / ODBC / RestAPI interfaces, enabling a connection with any SQL application.
Kyligence has also developed an online demo, showcasing the BI experience on 100 million airline records. Check it out to learn, for example, the most delayed airline to San Francisco International Airport in the past 20 years. (Login with username “analyst”, password “analyst”, select the “airline_cube”, drag and drop dimensions and measures to play with the data set.)
A retail scenario: Demonstrating Kylin’s speed
Kylin is faster than traditional SQL on Hadoop because it adopts pre-calculation to get a jump-ahead in terms of SQL execution. For example, Imagine a retail scenario where you’re dealing with many orders. One order can contain multiple line items. To see the business impact of cancelled orders and returned items, an analyst might write a query to report the revenue by “returnflag” and “orderstatus” within a time range, as shown in Figure 2. The diagram shows the query compiled into a relational expression, also called the “execution plan.”
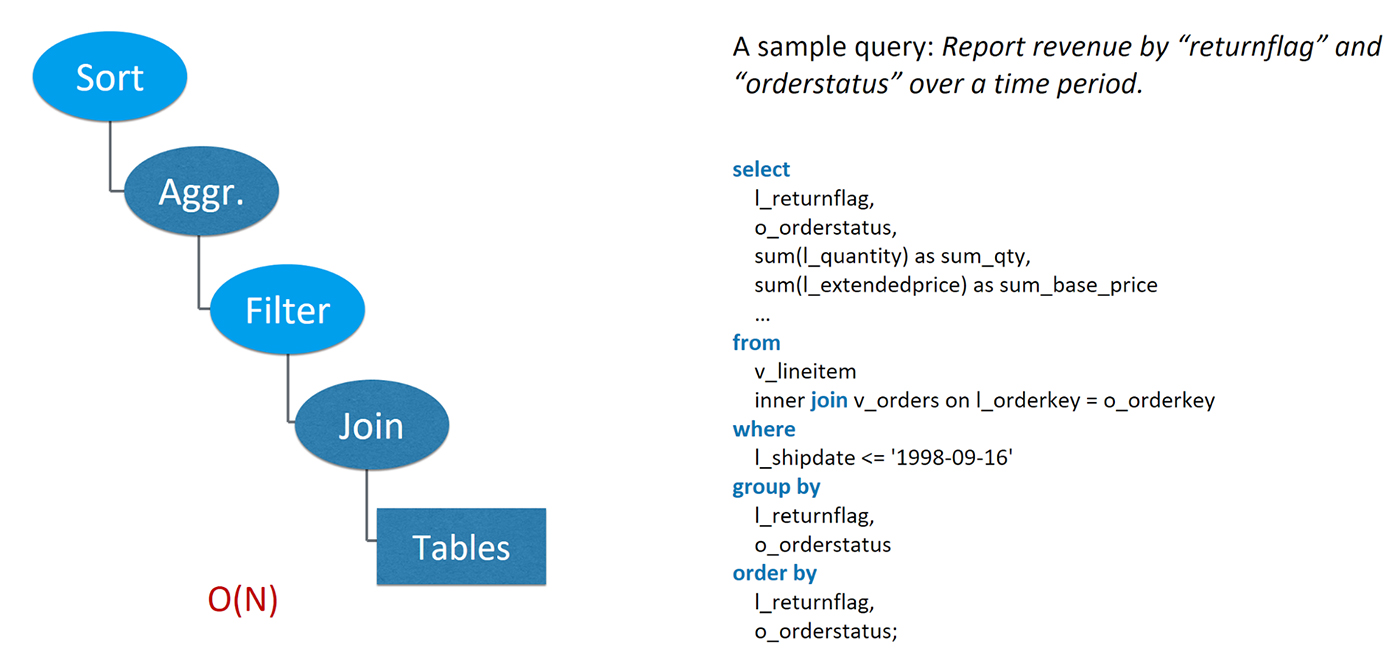
From the execution plan, it is easy to see that the time complexity of such an execution is at least O(N), where N represents the total number of rows in the tables, because each table row has to be visited at least once. And we assume the joining tables are perfectly partitioned and indexed, such that the expensive join operator can also finish in linear time complexity (which is not very likely in a real case).
The O(N) time complexity is not good, as it means the query will be 10 times slower if the data grows 10 times. A query that now takes one second could become 10 or 100 seconds later if data continues to grow. What we want is consistent query speed regardless of the size of the data.
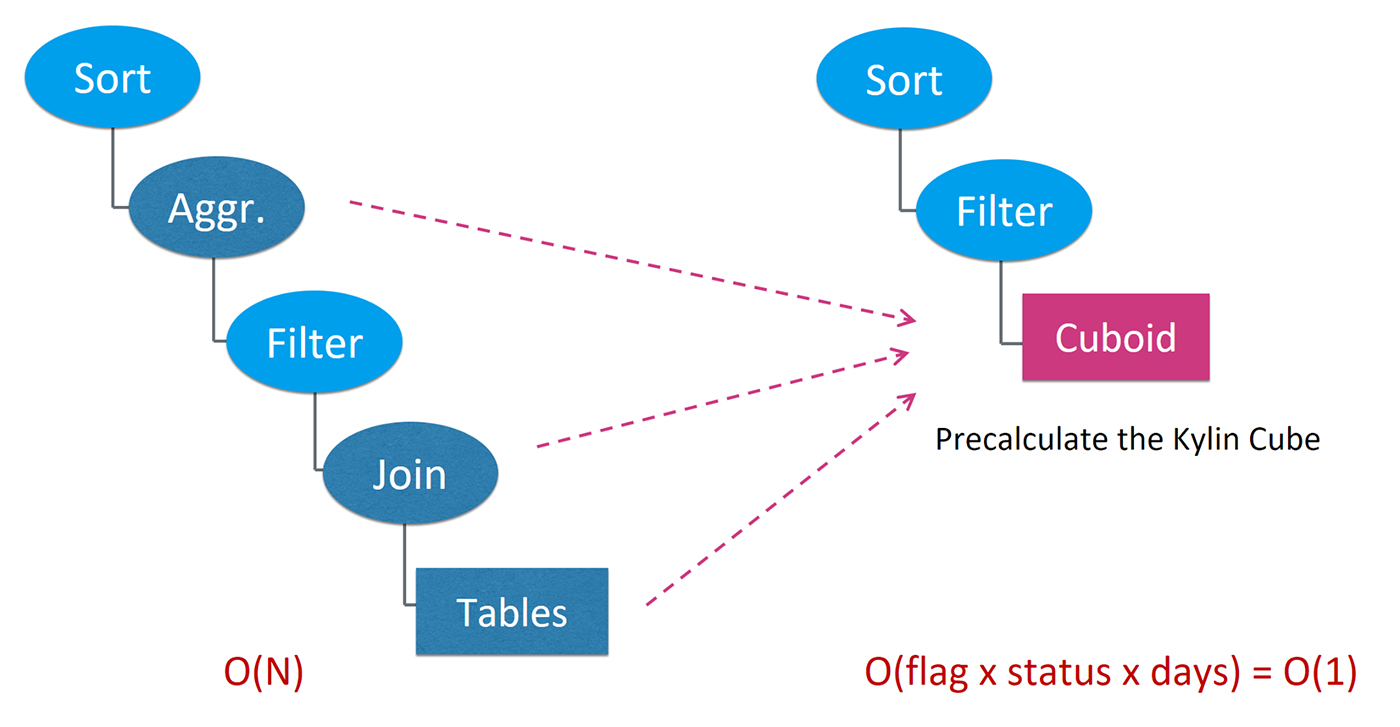
Kylin’s solution is pre-calculation. The idea is if we know the query pattern ahead of time, we can pre-calculate part of the execution in advance—in this case, pre-calculate the Aggregate, Join, and Table Scan operators. The result is a cuboid in cube theory (or call it a “materialized summary table” if that sounds better).
The original execution plan can be transformed to be on top of the cuboid, as Figure 3 shows. The cuboid contains rows summed up by “returnflag”, “orderstatus”, and “date”. Because there is a fixed number of return flags and order status, and the date range is limited for three years; there are about 1,000 days. That means the number of rows in the cuboid is at most “flag x status x days”, which is a constant in the big O notion. The new plan will guarantee a constant execution time, regardless of the size of the source data. Exactly what we want!
A look at Kylin’s architecture
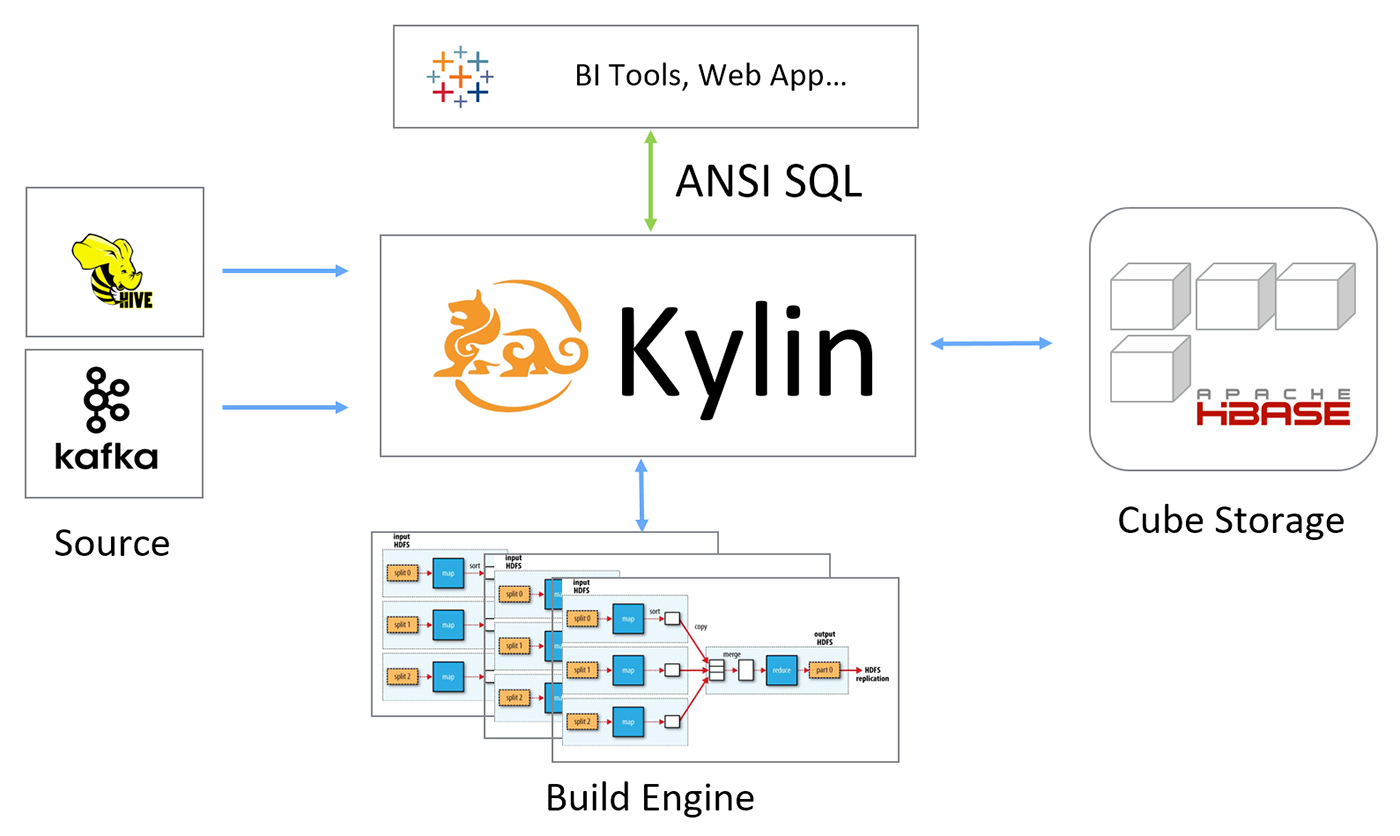
As we’ve seen, Kylin is a system that relies on pre-calculation. The core is based on the classic cube theory and is developed into a SQL-on-big-data solution (Figure 4). It uses model and cube concepts to define the space of pre-calculation. The build engine loads data from the source and does the pre-calculation in a distributed system, using either MapReduce or Spark. The calculated cube is stored in HBase. When a query comes in, Kylin compiles it into a relational expression, finds the matching model, and executes it on top of the pre-calculated cuboid instead of the source data.
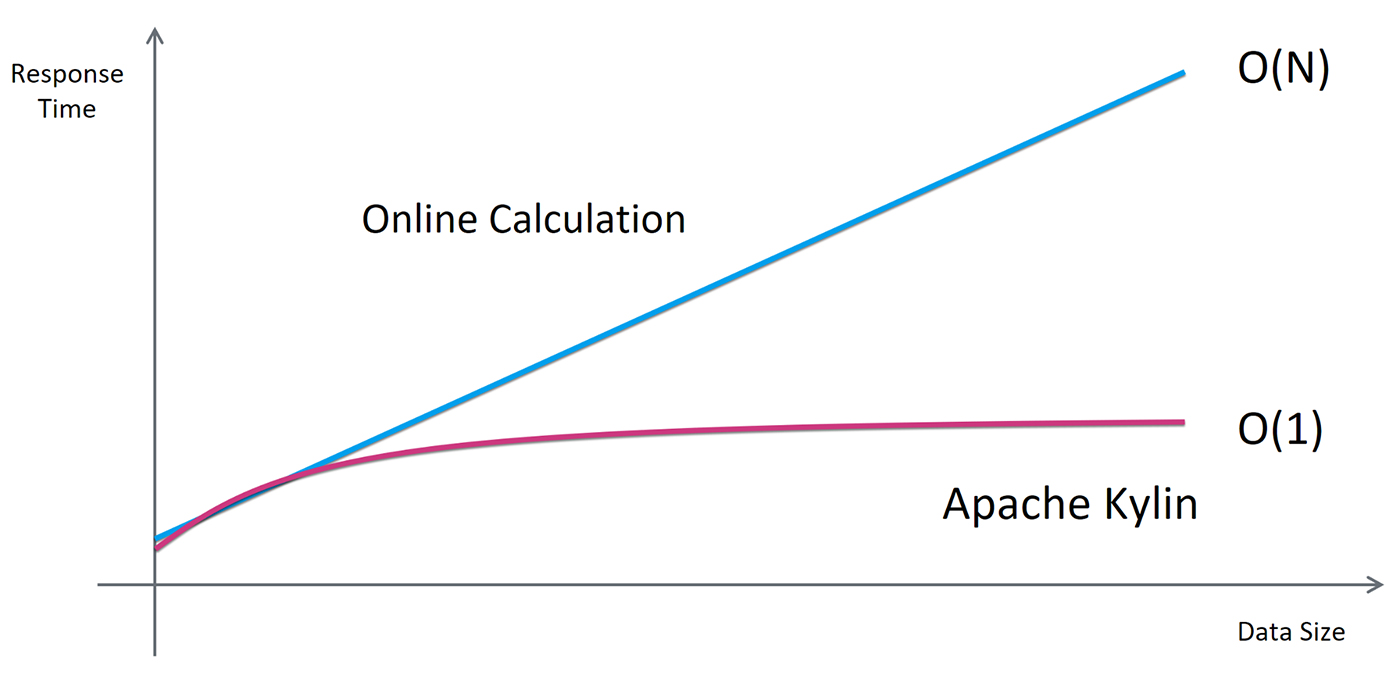
The key here is modeling. If you have a good understanding of the data and the analysis requirement, you can capture the right pre-calculation with the right model and cube definition. Then, most of your queries (if not all) will be able to transform into the cube query. The execution time complexity can be reduced to O(1), as shown in Figure 5, and achieve a very fast query speed, regardless of the original data size.
(Further reading: A star schema benchmark that demonstrates Kylin’s consistent performance on different scales of data.)
Features in Kylin 2.0
Snowflake schema support and TPC-H benchmark
Kylin 2.0 introduced big enhancements to model metadata and can support the snowflake data model out-of-box. To demonstrate the greatly improved modeling and SQL capability, efforts were made to run TPC-H queries on Kylin 2.0. The detailed steps and results are available here for others to repeat and verify.
Note the goal here is not comparing performance with other TPC-H results. On one hand, per TPC-H specification, pre-calculation is not permitted across tables, so in that sense, Kylin does not qualify a valid TPC-H system. On the other hand, no performance tuning has been done on these queries yet. The room for improvement is still very big.
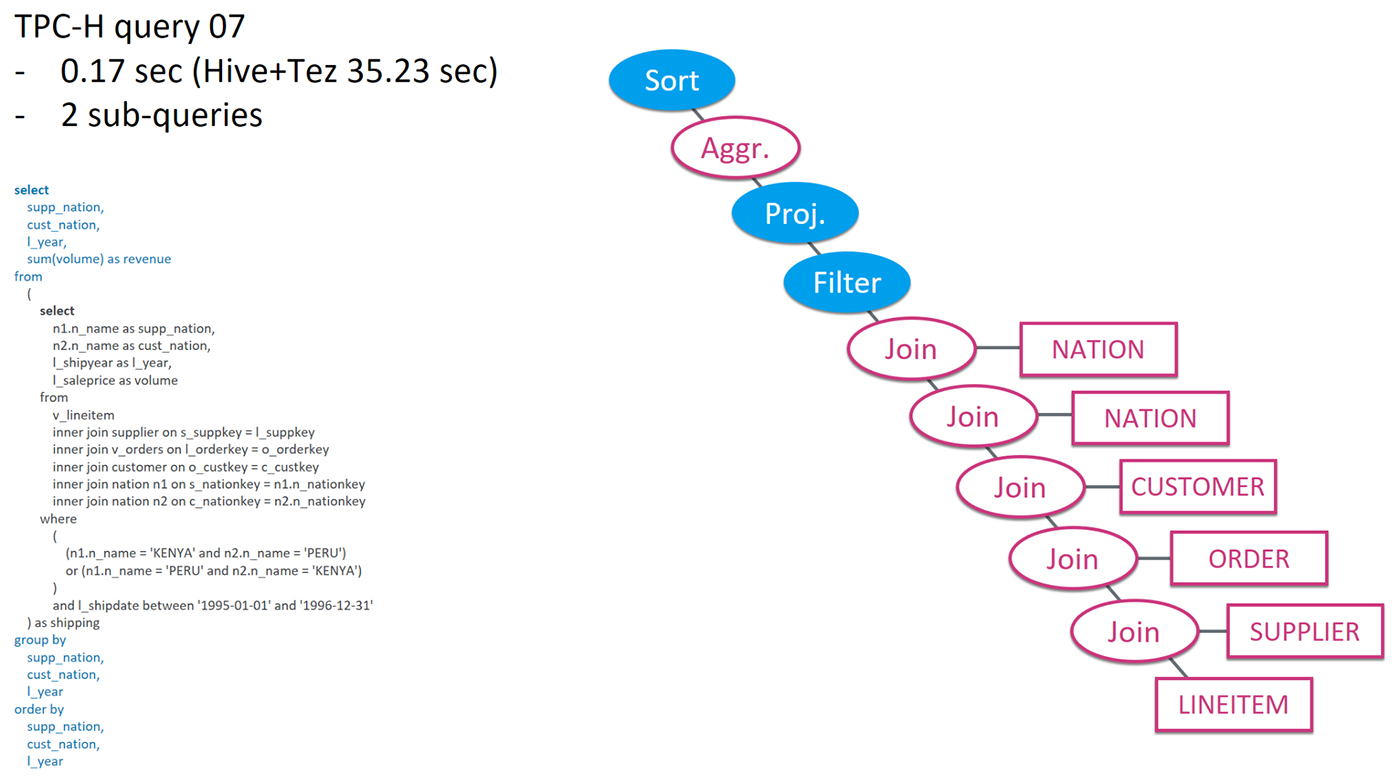
Let’s quickly look at a few interesting TPC-H queries, based on the same retail scenario. Figure 6 is TPC-H query 07. The SQL is too small to read but it gives a feeling of the complexity of the query. The diagram is the execution plan, highlighting the portion of pre-calculation (white) versus online calculation (blue). It’s easy to see that most of the relational operators are pre-calculated. The remaining Sort / Proj / Filter work on very few records, thus the query can be super fast. It takes Kylin 0.17 second to run, and on the same hardware and the same data set, Hive+Tez runs 35.23 seconds for this query. That shows the difference pre-calculation makes.
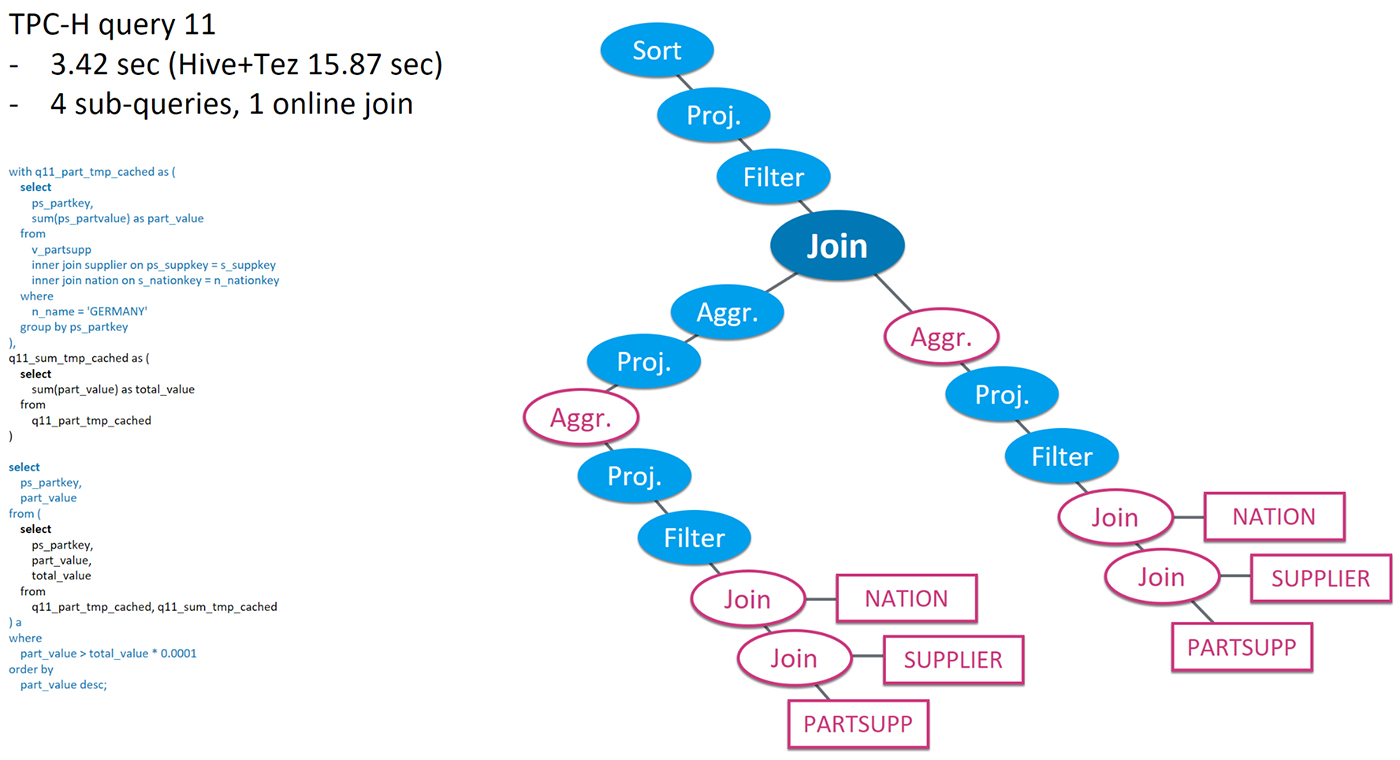
TPC-H query 11 in Figure 7 is another example. This query has four sub-queries and is more complex than the previous one. Its execution plan includes two branches, each load from a pre-calculated cuboid. And the branch results are joined again, which is a heavy online computation. As the portion of online calculation increases and the portion of pre-calculation decreases, the query takes longer for Kylin to run: 3.42 seconds. However, Hive+Tez, which does the full online calculation, is still much slower, taking 15.87 second to run.
(More details about Kylin and TPC-H can be found here. This link contains steps to repeat the benchmark in your environment and the performance results of all TPC-H queries we have tested in two different Hadoop clusters.)
Streaming cubing for near real-time analytics
Pre-calculation adds additional time to ETL process, and that becomes an issue in real-time scenarios. To address this problem, Kylin supports incremental build to load newly added data without touching the history. RestAPI is available to automatically trigger the incremental build. Daily build is most common, but more frequent data loading is also feasible.
Starting with version 1.6, Kylin can do streaming cubing that consumes data from Kafka directly and do near real-time data analysis. Using an in-memory cubing algorithm, micro-incremental builds can complete in a few minutes. The result is many small cube segments, and they can be queried to give real-time results.
To show how this works, a demo site has been put up to analyze Twitter messages in real-time. It runs on an eight-node AWS cluster, with three Kafka brokers. The input is a Twitter sample feed with more than 10K messages per second. The cube is averagely complex: nine dimensions and three measures. The incremental build is triggered every two minutes and finishes in three minutes. To sum it up, the system has a five-minute delay in terms of real-time-ness.
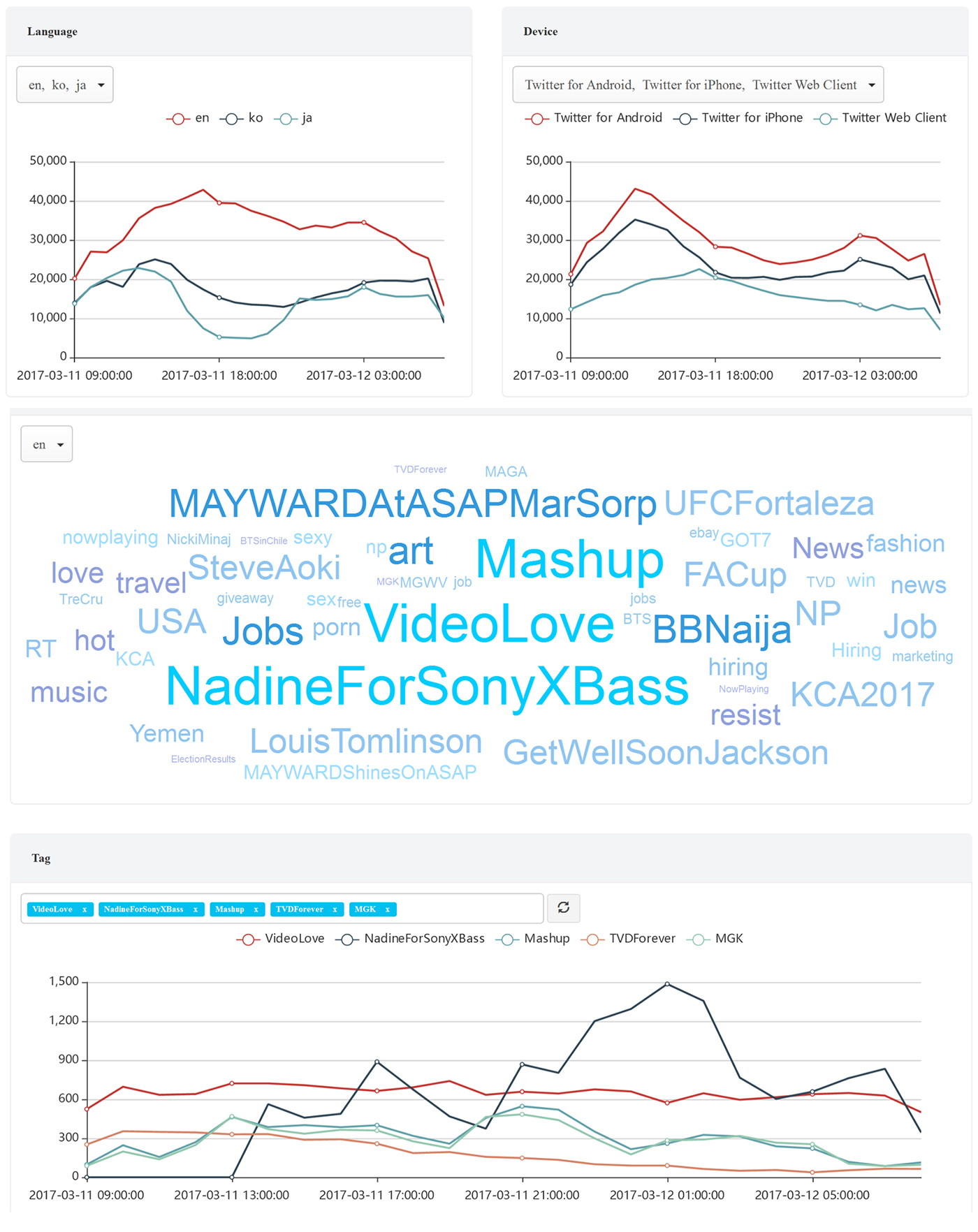
The demo shows Twitter message trends by language and by devices. We can see in Figure 8 that English message volume goes up in the U.S. daytime, while Asia message volume goes down in the nighttime. There’s also the tag cloud, showing the most recent hot topics. Below that is the trend of the hottest tags. All the charts are real-time to the latest five minutes.
Summary
Apache Kylin is a popular OLAP engine on Hadoop. Using pre-calculation technique, it makes SQL on big data orders faster and enables interactive BI and other online applications to run on big data directly.
Kylin 2.0 is latest version and is ready for download. Features include: sub-second SQL latency on Hadoop; snowflake schema support and mature SQL capability; streaming cubing for near real-time analytics; built-in Time / Window / Percentile functions; and Spark cubing that halves the build time.
Resources: