Deep learning for Apache Spark
The O’Reilly Data Show Podcast: Jason Dai on BigDL, a library for deep learning on existing data frameworks.
 Tape library, CERN, Geneva 2. (source: Cory Doctorow on Flickr)
Tape library, CERN, Geneva 2. (source: Cory Doctorow on Flickr)
In this episode of the Data Show, I spoke with Jason Dai, CTO of big data technologies at Intel, and co-chair of Strata + Hadoop World Beijing. Dai and his team are prolific and longstanding contributors to the Apache Spark project. Their early contributions to Spark tended to be on the systems side and included Netty-based shuffle, a fair-scheduler, and the “yarn-client” mode. Recently, they have been contributing tools for advanced analytics. In partnership with major cloud providers in China, they’ve written implementations of algorithmic building blocks and machine learning models that let Apache Spark users scale to extremely high-dimensional models and large data sets. They achieve scalability by taking advantage of things like data sparsity and Intel’s MKL software. Along the way, they’ve gained valuable experience and insight into how companies deploy machine learning models in real-world applications.
When I predicted that 2017 would be the year when the big data and data science communities start exploring techniques like deep learning in earnest, I was relying on conversations with many members of those communities. I also knew that Dai and his team were at work on a distributed deep learning library for Apache Spark. This evolution from basic infrastructure, to machine learning applications, and now applications backed by deep learning models is to be expected.

Learn faster. Dig deeper. See farther.
Once you have a platform and a team that can deploy machine learning models, it’s natural to begin exploring deep learning. As I’ve highlighted in recent episodes of this podcast (here and here), companies are beginning to apply deep learning to time-series data, event data, text, and images. Many of these same companies have already invested in big data technologies (many of which are open source) and employ data scientists and data engineers who are comfortable with these tools.
While there are many libraries, cloud services, and packaged solutions available for deep learning, deploying it usually involves big (labeled) data, big models, and big compute, so a typical project involves data acquisition, preprocessing and preparation on a Spark cluster, and model training on a server with multiple GPUs.
A new project called BigDL, offers another option: it brings deep learning directly into the big data ecosystem. BigDL is an open source, distributed deep learning library for Apache Spark that has feature parity with existing popular deep learning frameworks like Torch and Caffe (BigDL is modeled after Torch). For the many companies that already have data in Hadoop/Spark clusters, BigDL lets them use those same clusters for deep learning.
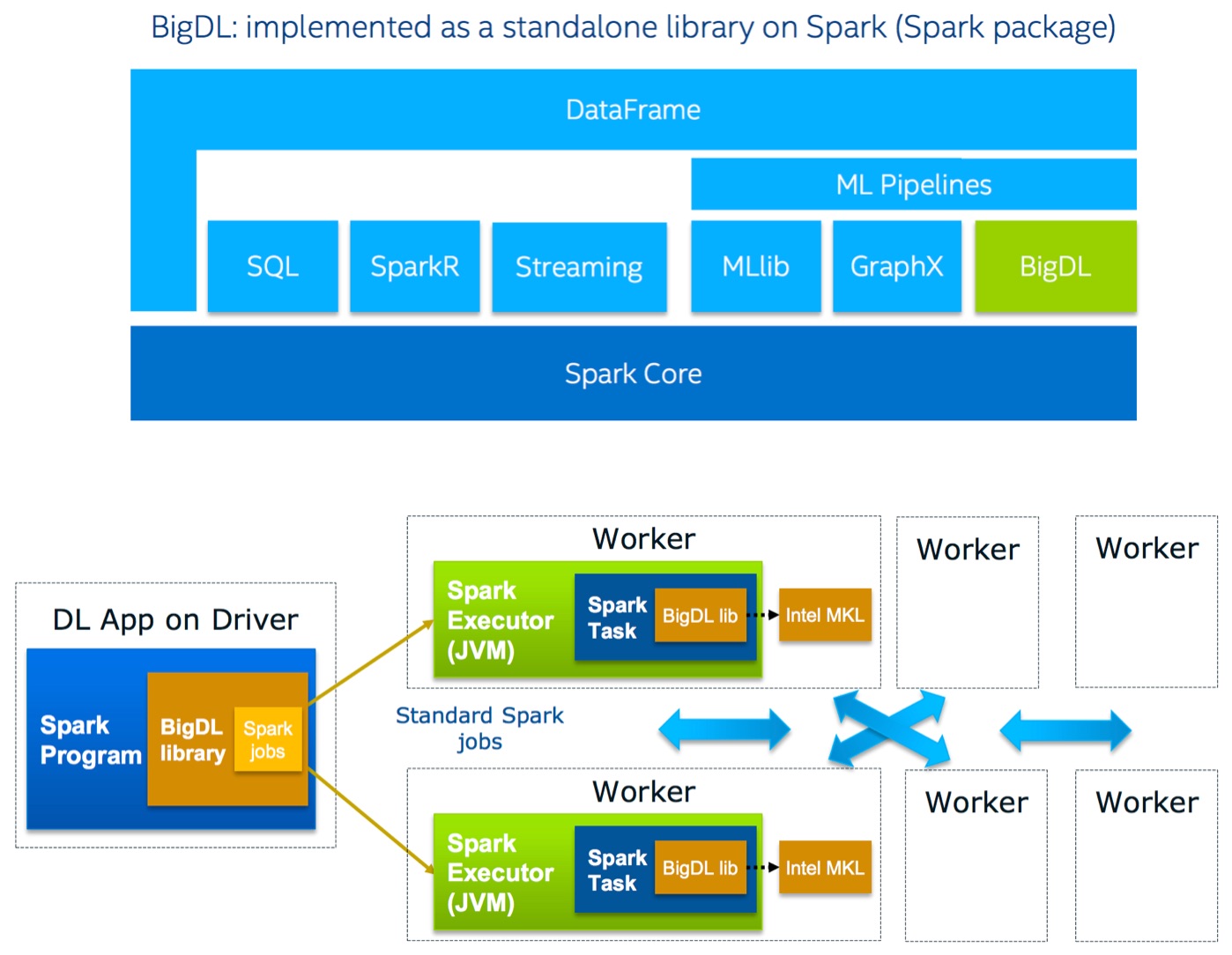
The typical deep learning pipeline that involves data preprocessing and preparation on a Spark cluster and model training on a server with multiple GPUs, now involves a simple Spark library that runs on the same cluster used for data preparation and storage. BigDL takes advantage of MKL software and also lets you efficiently train larger models across a cluster (using distributed synchronous, mini-batch SGD), and an AMI is available to those who want to run it on Amazon Web Services.
While GPUs still provide much faster training times for deep learning, and thus remain the option for bleeding-edge researchers, BigDL should appeal to companies that have invested in big data clusters and software (convenience versus performance). This is true even for companies using cloud computing resources, or even public cloud providers that have invested in more CPU than GPU compute resources.
Many data products involve complex data pipelines, and machine learning models comprise a small component of such systems. I imagine some companies will be drawn to BigDL because it opens up the possibility of having a unified platform for data processing, storage, feature engineering, analytics, machine learning, and now deep learning. This means not having to transfer data between clusters or frameworks (BigDL is just a Spark library), lower total time for end-to-end learning, and simpler resource and workflow management. This is, in fact, the origin of BigDL: the team decided to work on it after several companies in China expressed interest in using their existing hardware and compute resources for deep learning projects and workloads.
BigDL was publicly released as open source at the end of 2016. In the months leading up to its public release, Dai and his team helped companies use it in production on Spark clusters comprised of several tens of Xeon servers. Some early use cases include fraud detection systems at a large payment company and a large commercial bank, and image classification and object detection applications at large manufacturing companies.
We’re still in the very early stages of companies adding deep learning to their list of machine learning models. I expect that we will continue to experiment with a variety of managed services, and proprietary and open source tools for deep learning. BigDL brings another option for companies that want to leverage their existing big data infrastructure and ease the adoption of deep learning by teams who are familiar with existing frameworks. There’s an economic benefit as well: besides the convenience that comes from using existing tools, reducing complexity and increasing utilization can often mean much lower TCO.
The Call For Proposals for Strata + Hadoop World Beijing closes on Feb 24, 2017.
Related resources:
- Web-scale machine learning on Apache Spark: Jason Dai’s talk at Strata Singapore 2016
- Code for BigDL (deep learning), SparseML (machine learning on sparse data), and topic modeling
- 2017 will be the year the data science and big data community engage with AI technologies
- The key to building deep learning solutions for large enterprises
- Use deep learning on data you already have
- How big compute is powering the deep learning rocket ship