 Facade (source: Pixabay)
Facade (source: Pixabay) Data governance has become increasingly critical as more organizations rely on data to make better decisions, optimize operations, create new products and services, and improve profitability.
Upcoming data security regulations like the new EU GPDR law will require organizations to have a forward-looking approach in order to comply with these requirements. Additionally, regulated industries, such as health care and finance, spend a tremendous amount of money on compliance with regulations that are constantly changing.
Developing a successful data governance strategy requires careful planning, the right people, and the appropriate tools and technologies. It is necessary to implement the required policies and procedures across all of an organization’s data in order to guarantee that everyone acts in accordance with the regulatory framework.
Implementing a modern data governance framework requires the use of new technologies. Traditional technologies, known as Relational Database Management Systems (RDBMS), are based on the relational model, in which data are presented and stored in a tabular form. RDBMS are not flexible enough to easily update this relational schema when data need to change frequently. Basically, RDBMS are not good in the data governance context, because you need to define your model in advance. However, NoSQL technologies, such as document-oriented databases, provide a way to store and retrieve data that can be modeled in a non-tabular form, and they do not require having a model in advance.
A flexible data governance framework prevents situations in which complex engineering systems have several disconnected pieces of data along with expensive hardware. A flexible data governance framework is able to ingest data without needing a long extract-transform-load (ETL) process, and it should support schema-free databases storing data from multiple disparate data sources. An important characteristic of flexible data governance frameworks is the ability to support semantic relationships using Graphs, RDF triples or Ontologies, as shown in the following figure.
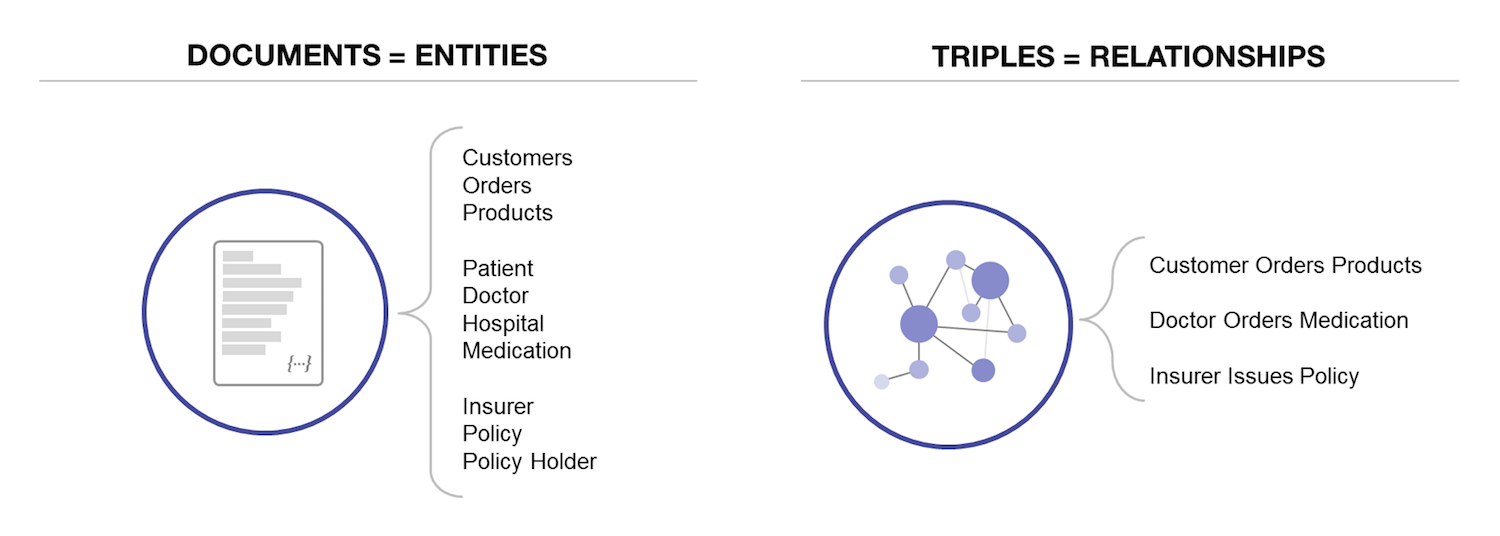
The multi-model database is a general NoSQL approach that can store, index, and query data in one or more of the previous models. Due to this flexibility, the multi-model database is the best approach for addressing data governance. (For more information about multi-model databases see the O’Reilly ebook: Building on Multi-Model Databases.
With a multi-model database, all relevant data is stored as a document, and all information about source, date created, priveleges, etc., are stored as metadata in an envelope around the document. This original data is preserved—and the metadata is included. Semantics enrich this capability by enabling inferences and provide a great way to model “policies” because they are terrific for expressing complex metadata in a flexible way, and you can infer which policies take precedence. For example: if CarlosSánchez = Sánchez, Carlos = Csánchez, and this person is a citizen of Spain, and Spain is an EU member, then any EU policy applies to Carlos—however the name is represented. Since the metadata is indexed as well as the data, then policy can be enforced across data queries and updates. Lastly, a database with built-in search enables instant relevant use of ingested data. And since the meta data is indexed as well as data, policy can be enforced across data queries and updates. If policies are integrated at the database level instead of at the application level, policies stay with the data, and execution of the specific policy will be easier because it requires less code to implement.
This post is a collaboration between O’Reilly and MarkLogic. See our statement of editorial independence.