

 Grid of images after transformations are performed. (source: Tuhin Sharma, used with permission)
Grid of images after transformations are performed. (source: Tuhin Sharma, used with permission) Digital marketing is the marketing of products, services, and offerings on digital platforms. Advertising technology, commonly known as “ad tech,” is the use of digital technologies by vendors, brands, and their agencies to target potential clients, deliver personalized messages and offerings, and analyze the impact of online spending: sponsored stories on Facebook newsfeeds; Instagram stories; ads that play on YouTube before the video content begins; the recommended links at the end of a CNN article, powered by Outbrain—these all are examples of ad tech at work.
In the past year, there has been a significant use of deep learning for digital marketing and ad tech.
In this article, we will delve into one part of a popular use case: mining the Web for celebrity endorsements. Along the way, we’ll see the relative value of deep learning architectures, run actual experiments, learn the effects of data sizes, and see how to augment the data when we don’t have enough.
Use case overview
In this article, we will see how to build a deep learning classifier that will predict the company, given an image with logo. This section provides an overview of where this model could be used.
Celebrities endorse a number of products. Quite often, they post pictures on social media showing off a brand they endorse. A typical post of that type contains an image, with the celebrity and some text they have written. The brand, in turn, is eager to learn about the appearance of such postings, and to show them to potential customers who might be influenced by them.
The ad tech application, therefore, works as follows: large numbers of postings are fed to a processor that figures out the celebrity, the brand, and the message. Then, for each potential customer, the machine learning model generates a very specific advertisement based on the time, location, message, brand, customers’ preferred brands, and other things. Another model identifies the target customer base. And the targeted ad is now sent.
Figure 1 shows the workflow:
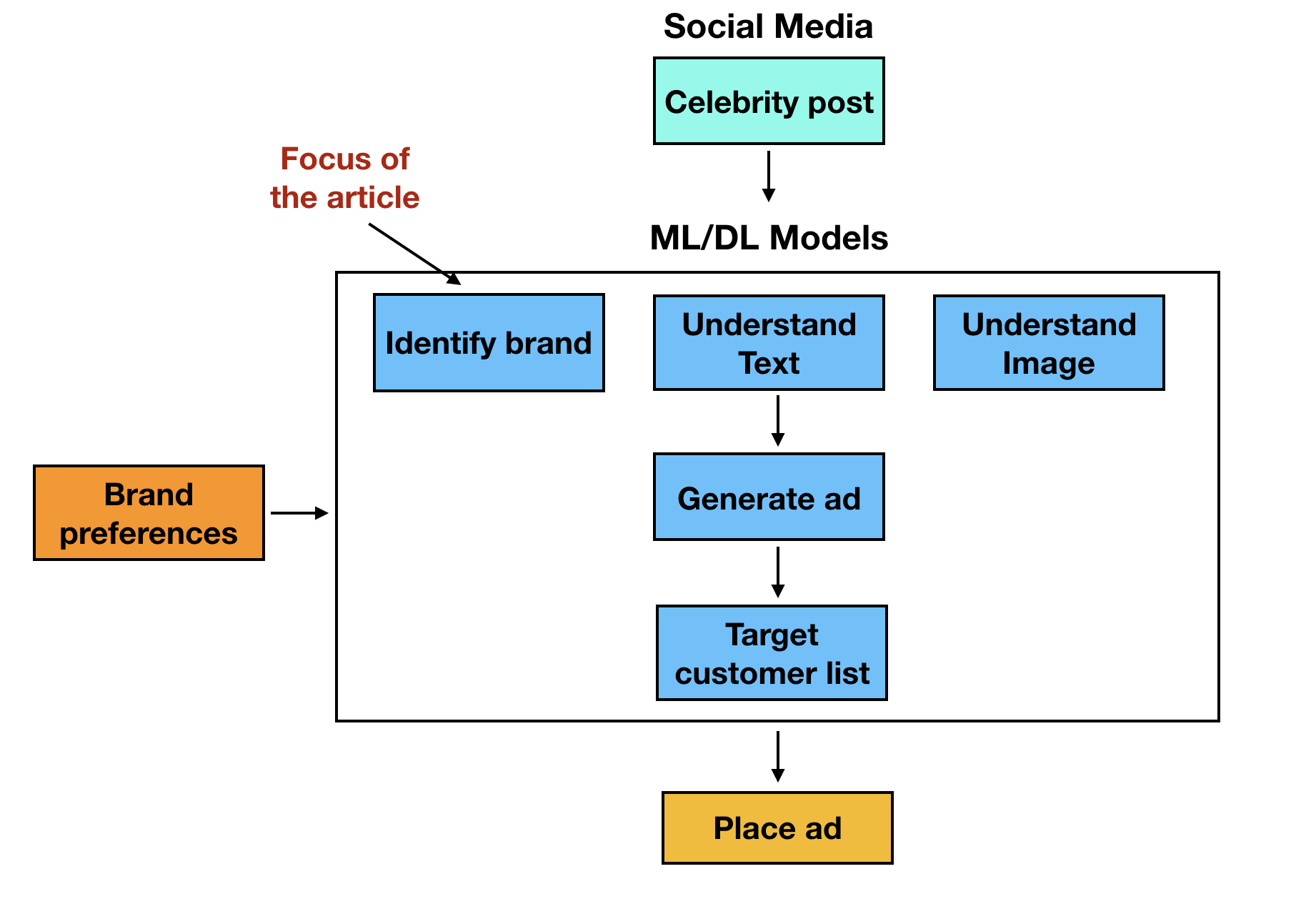
As you can see, the system is composed of a number of machine learning models.
Consider the image. The picture could have been taken in any setting. The first goal is to identify the objects and the celebrity in the picture. This is done by object detection models. Then, the next step is to identify the brand, if one appears. The easiest way to identify the brand is by its logo.
In this article, we will look into building a deep learning model to identify a brand by its logo in an image. Subsequent articles will talk about building some of the other pieces of the bot (object detection, text generation, etc.).
Problem definition
The problem addressed in this article is: given an image, predict the company (brand) in the image by identifying the logo.
Data
To build machine learning models, access to high-quality data sets are imperative. In real-life, the data scientists will work with brand managers and agencies to get all possible logos.
For the purpose of this article, we will leverage the FlickrLogo data set. This data set has real-world images from Flickr, a popular photo sharing website. The FlickrLogo page has instructions on how to download the data. Please download the data if you want to use the code in this article to build your own models.
Models
Identifying the brand from its logo is a classic computer vision problem. In the past few years, deep learning has become the state-of-the-art for computer vision problems. We will be building deep learning models for this use case
Software
In our previous article, we talked about the strengths of Apache MXNet. We also talked about Gluon, the simpler interface on top of MXNet. Both are extremely powerful and allow deep learning engineers to experiment rapidly with various model architectures.
Let’s now get to the code.
Libraries
Let’s first import the libraries we need for building the models:
importmxnetasmximportcv2frompathlibimportPathimportosfromtimeimporttimeimportshutilimportmatplotlib.pyplotasplt%matplotlibinline
Load the data
From the FlickrLogos data sets, let’s use the FlickrLogos-32 data set. <flickrlogos-url> is the URL to this data set.
%%capture!wget-nc<flickrlogos-url># Replace with the URL to the dataset!unzip-n./FlickrLogos-32_dataset_v2.zip
Data preparation
The next step is to create the following data sets:
- Train
- Validation
- Test
The FlickrLogos already has train, validation and test data sets, dividing the images as follows:
- The train data set has 32 classes, each containing 10 images.
- The validation data set has 3,960 images, of which 3,000 images have no logos.
- The test data set has 3,960 images.
While the train images all have logos, the validation and test images have no logos. We want to build a model that generalizes well. We want a model that predicts correctly on images that weren’t used for training (validation and test images).
To make our learning faster, with better accuracy, for the purpose of this article, we will move 50% of the no-logo class from the validation data set to the training set. So, we will make the training data set of size 1,820 (after adding 1,500 no-logo images from validation set) and reduce the validation data set size to 2,460 (after moving out 1,500 no-logo images). In a real-life setting, we will experiment with different model architectures to choose the one that performs well on the actual validation and test data sets.
Next, define the directory where the data is stored.
data_directory="./FlickrLogos-v2/"
Now, define the path to the train, test, and validation data sets. For validation, we define two paths: one for the images containing logos and one for the rest of the images without logos.
train_logos_list_filename=data_directory+"trainset.relpaths.txt"val_logos_list_filename=data_directory+"valset-logosonly.relpaths.txt"val_nonlogos_list_filename=data_directory+"valset-nologos.relpaths.txt"test_list_filename=data_directory+"testset.relpaths.txt"
Let’s now read the filenames for train, test, and validation (logo
and non-logo) from the list just defined.
The list is given in the FlickrLogo data set, which has
already categorized the images as train, test, validation with logo,
and validation without logo.
# List of train imageswithopen(train_logos_list_filename)asf:train_logos_filename=f.read().splitlines()
# List of validation images without logoswithopen(val_nonlogos_list_filename)asf:val_nonlogos_filename=f.read().splitlines()
# List of validation images with logoswithopen(val_logos_list_filename)asf:val_logos_filename=f.read().splitlines()
# List of test imageswithopen(test_list_filename)asf:test_filenames=f.read().splitlines()
Now, move some of the validation images without logos to the set of train images. This set will end up with all the train images and 50% of no-logo images from the validation data set. The validation set will end up with all the validation images that have logos and the remaining 50% of no-logo images.
train_filenames=train_logos_filename+val_nonlogos_filename[0:int(len(val_nonlogos_filename)/2)]
val_filenames=val_logos_filename+val_nonlogos_filename[int(len(val_nonlogos_filename)/2):]
To verify what we’ve done, let’s print the number of images in the train, test and validation data sets.
("Number of Training Images : ",len(train_filenames))("Number of Validation Images : ",len(val_filenames))("Number of Testing Images : ",len(test_filenames))
The next step in the data preparation process is to set the folder paths in a way that makes model training easy.
We need the folder structure to be like Figure 2.
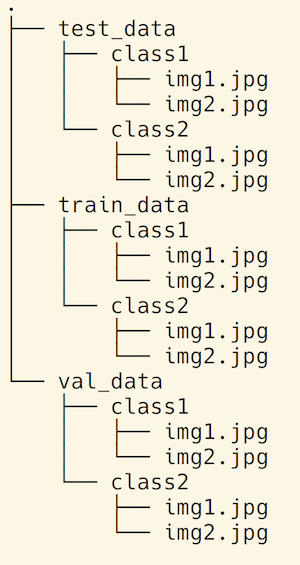
The following function helps us create this structure.
defprepare_datesets(base_directory,filenames,dest_folder_name):forfilenameinfilenames:image_src_path=base_directory+filenameimage_dest_path=image_src_path.replace('classes/jpg',dest_folder_name)dest_directory_path=Path(os.path.dirname(image_dest_path))dest_directory_path.mkdir(parents=True,exist_ok=True)shutil.copy2(image_src_path,image_dest_path)
Call this function to create the train, validation, and test folders with the images placed under them within their respective classes.
prepare_datesets(base_directory=data_directory,filenames=train_filenames,dest_folder_name='train_data')prepare_datesets(base_directory=data_directory,filenames=val_filenames,dest_folder_name='val_data')prepare_datesets(base_directory=data_directory,filenames=test_filenames,dest_folder_name='test_data')
The next step is to define the hyperparameters for the model.
We have 33 classes (32 logos and 1 non-logo). The data size isn’t huge, so we will use only one GPU. We will train for 20 epochs and use 40 as the batch size for training.
batch_size=40num_classes=33num_epochs=20num_gpu=1ctx=[mx.gpu(i)foriinrange(num_gpu)]
Data pre-processing
Once the images are loaded, we need to ensure the images are of the same size. We will resize all the images to be 224 * 224 pixels.
We have 1,820 training images, which is really not much data. Is there a smart way to get more data? An astounding yes. An image, when flipped, still means the same thing, at least for logos. A random crop of the logo is also still the same logo.
So, we do not need to add images for the purposes of our training, but instead can transform some of the existing images by flipping them and cropping them. This helps us get a more robust model.
Let’s flip 50% of the training data set horizontally and crop them to 224 * 224 pixels.
train_augs=[mx.image.HorizontalFlipAug(.5),mx.image.RandomCropAug((224,224))]
For the validation and test data sets, let’s center crop to get each image to 224 224. All the images in the train, test, and validation data sets will now be of 224 224 size.
val_test_augs=[mx.image.CenterCropAug((224,224))]
To perform the transforms we want on images, define the function transform. Given the data and the augmentation type, it performs the transformation on the data and returns the updated data set.
deftransform(data,label,augs):data=data.astype('float32')forauginaugs:data=aug(data)# from (H x W x c) to (c x H x W)data=mx.nd.transpose(data,(2,0,1))returndata,mx.nd.array([label]).asscalar().astype('float32')
Gluon has an utility function to load image files: mx.gluon.data.vision.ImageFolderDataset. It requires the data to be available in the folder structure illustrated in Figure 2.
The function takes in the following parameters:
- Path to the root directory where the images are stored
- A flag to instruct if images have to be converted to greyscale or color (color is the default option)
- A function that takes the data (image) and its label and transforms them
The following code shows how to transform the image when loading:
train_imgs=mx.gluon.data.vision.ImageFolderDataset(data_directory+'train_data',transform=lambdaX,y:transform(X,y,train_augs))
Similarly, the transformations are applied to the validation and test data sets and are loaded.
val_imgs=mx.gluon.data.vision.ImageFolderDataset(data_directory+'val_data',transform=lambdaX,y:transform(X,y,val_test_augs))
test_imgs=mx.gluon.data.vision.ImageFolderDataset(data_directory+'test_data',transform=lambdaX,y:transform(X,y,val_test_augs))
DataLoader is the built-in utility function to load data from the data set, and it returns mini-batches of data. In the above steps, we have the train, validation, and test data sets defined ( train_imgs, val_imgs, test_imgs respectively). The num_workers attribute lets us define the number of multi-processing workers to use for data pre-processing.
train_data=mx.gluon.data.DataLoader(train_imgs,batch_size,num_workers=1,shuffle=True)val_data=mx.gluon.data.DataLoader(val_imgs,batch_size,num_workers=1)test_data=mx.gluon.data.DataLoader(test_imgs,batch_size,num_workers=1)
Now that the images are loaded, let’s take a look at them. Let’s write a utility function called show_images that displays the images as a grid:
defshow_images(imgs,nrows,ncols,figsize=None):"""plot a grid of images"""figsize=(ncols,nrows)_,figs=plt.subplots(nrows,ncols,figsize=figsize)foriinrange(nrows):forjinrange(ncols):figs[i][j].imshow(imgs[i*ncols+j].asnumpy())figs[i][j].axes.get_xaxis().set_visible(False)figs[i][j].axes.get_yaxis().set_visible(False)plt.show()
Now, display the first 32 images in a 8 * 4 grid:
forX,_intrain_data:# from (B x c x H x W) to (Bx H x W x c)X=X.transpose((0,2,3,1)).clip(0,255)/255show_images(X,4,8)break

Results are shown in Figure 3. Some of the images seem to contain logos, often truncated.
Utility functions for training
In this section, we will define utility functions to do the following:
- Get the data for the batch being currently processed
- Evaluate the accuracy of the model
- Train the model
- Get the image, given a URL
- Predict the image’s label, given the image
The first function, _get_batch, returns the data and label, given the batch.
def_get_batch(batch,ctx):"""return data and label on ctx"""data,label=batchreturn(mx.gluon.utils.split_and_load(data,ctx),mx.gluon.utils.split_and_load(label,ctx),data.shape[0])
The function evaluate_accuracy returns the classification accuracy of the model. We have chosen a simple accuracy metric for the purpose of this article. In practice, the accuracy metric is chosen based on the application need.
defevaluate_accuracy(data_iterator,net,ctx):acc=mx.nd.array([0])n=0.forbatchindata_iterator:data,label,batch_size=_get_batch(batch,ctx)forX,yinzip(data,label):acc+=mx.nd.sum(net(X).argmax(axis=1)==y).copyto(mx.cpu())n+=y.sizeacc.wait_to_read()returnacc.asscalar()/n
The next function we will define is the train function. This is by far the biggest function we will create in this article.
Given an existing model, the train, test, and validation data sets, the model is trained for the number of epochs specified. Our previous article contained a more detailed overview of how this function works.
Whenever the best accuracy on the validation data set is found, the model is checkpointed. For each epoch, the train, validation, and test accuracies are printed.
deftrain(net,ctx,train_data,val_data,test_data,batch_size,num_epochs,model_prefix,hybridize=False,learning_rate=0.01,wd=0.001):net.collect_params().reset_ctx(ctx)ifhybridize==True:net.hybridize()loss=mx.gluon.loss.SoftmaxCrossEntropyLoss()trainer=mx.gluon.Trainer(net.collect_params(),'sgd',{'learning_rate':learning_rate,'wd':wd})best_epoch=-1best_acc=0.0ifisinstance(ctx,mx.Context):ctx=[ctx]forepochinrange(num_epochs):train_loss,train_acc,n=0.0,0.0,0.0start=time()fori,batchinenumerate(train_data):data,label,batch_size=_get_batch(batch,ctx)losses=[]withmx.autograd.record():outputs=[net(X)forXindata]losses=[loss(yhat,y)foryhat,yinzip(outputs,label)]forlinlosses:l.backward()train_loss+=sum([l.sum().asscalar()forlinlosses])trainer.step(batch_size)n+=batch_sizetrain_acc=evaluate_accuracy(train_data,net,ctx)val_acc=evaluate_accuracy(val_data,net,ctx)test_acc=evaluate_accuracy(test_data,net,ctx)("Epoch%d. Loss:%.3f, Train acc%.2f, Val acc%.2f, Test acc%.2f, Time%.1fsec"%(epoch,train_loss/n,train_acc,val_acc,test_acc,time()-start))ifval_acc>best_acc:best_acc=val_accifbest_epoch!=-1:('Deleting previous checkpoint...')os.remove(model_prefix+'-%d.params'%(best_epoch))best_epoch=epoch('Best validation accuracy found. Checkpointing...')net.collect_params().save(model_prefix+'-%d.params'%(epoch))
The function get_image returns the image from a given URL. This is used for testing the model’s accuracy
defget_image(url,show=False):# download and show the imagefname=mx.test_utils.download(url)img=cv2.cvtColor(cv2.imread(fname),cv2.COLOR_BGR2RGB)img=cv2.resize(img,(224,224))plt.imshow(img)returnfname
The final utility function we will define is classify_logo. Given the image and the model, the function returns the class of the image (in this case, the brand name) and its associated probability.
defclassify_logo(net,url):fname=get_image(url)withopen(fname,'rb')asf:img=mx.image.imdecode(f.read())data,_=transform(img,-1,val_test_augs)data=data.expand_dims(axis=0)out=net(data.as_in_context(ctx[0]))out=mx.nd.SoftmaxActivation(out)pred=int(mx.nd.argmax(out,axis=1).asscalar())prob=out[0][pred].asscalar()label=train_imgs.synsetsreturn'With prob=%f,%s'%(prob,label[pred])
Model
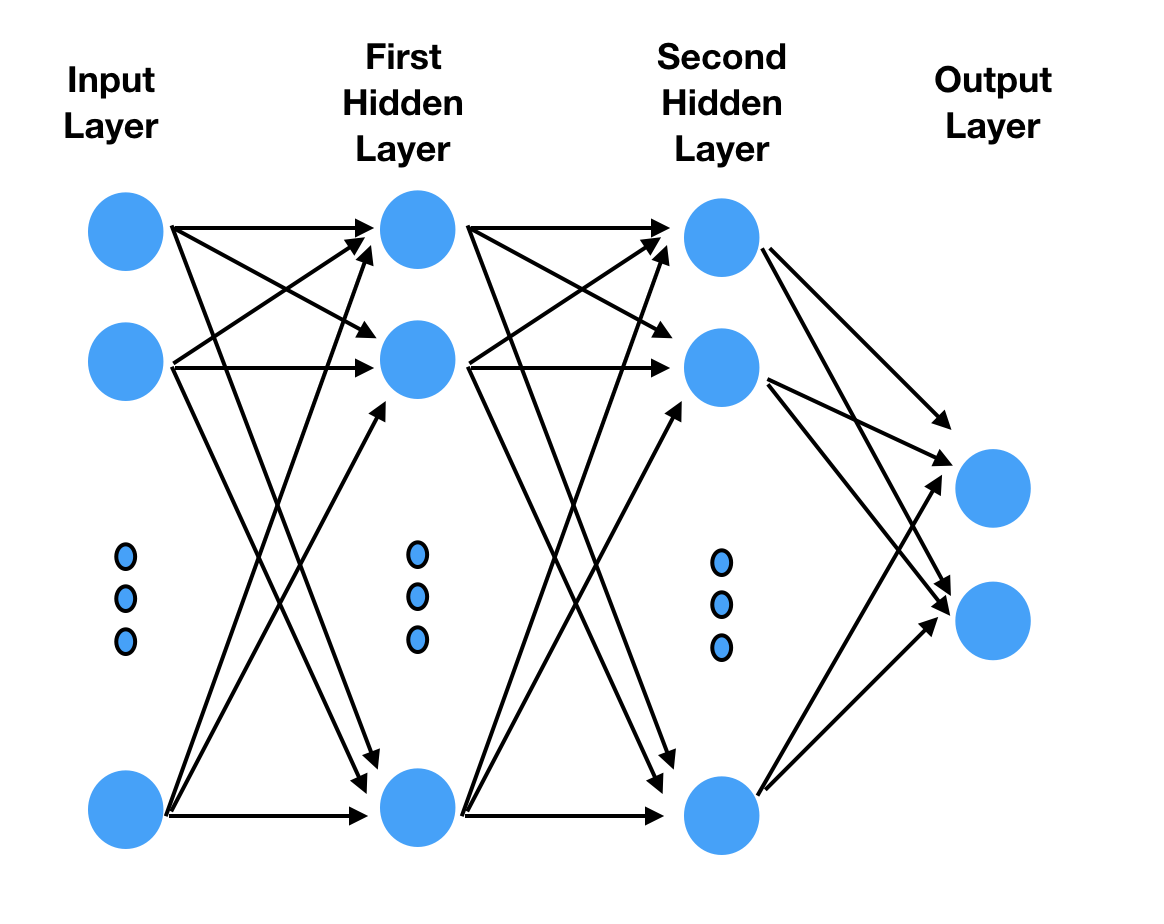
Understanding the model architecture is quite important. In our previous article, we built a multi-layer perceptron (MLP). The architecture is shown in Figure 4.
How would the input layer for an MLP model be? Our data is 224 * 224 pixels in size.
The most common way to create the input layer from that is to flatten it and create an input layer with 50,176 (224 * 224) neurons, ending up with a simple bit stream as shown in Figure 5.
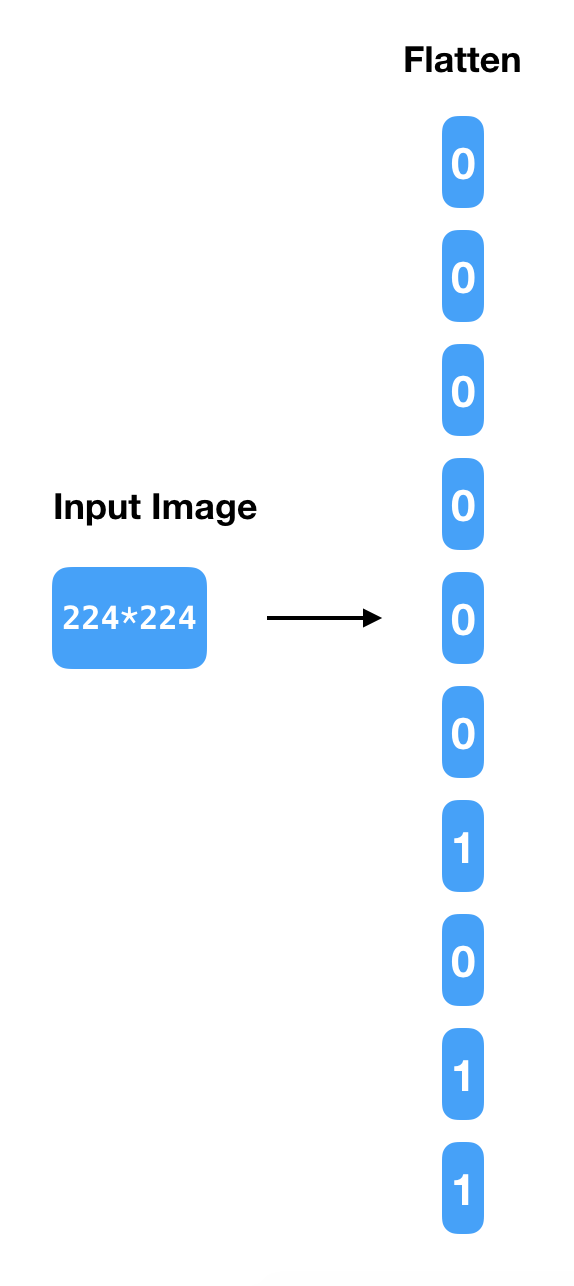
But image data has a lot of spatial information that is lost when such flattening is done. And the other challenge is the number of weights. If the first hidden layer has 30 hidden neurons, the number of parameters in the model will be 50,176 * 30 + 30 bias units. So, this doesn’t seem to be the right modeling approach for images.
Let’s now discuss the more appropriate architecture: a convolutional neural network (CNN) for image classification.
Convolutional neural network (CNN)
CNNs are similar to MLPs, in the sense that they are also made up of neurons whose weights we learn. The key difference is that the inputs are images, and the archicture allows us to exploit the properties of the images into the architecture.
CNNs have convolutional layers. The term “convolution” is taken from image processing, and it is described by Figure 6. This works on a small window, called a “receptive field,” instead of all the inputs from the previous layer. This allows the model to learn localized features.
Each layer moves a small matrix, called a kernel, over the part of the image fed to that layer. It adjusts each pixel to reflect the pixels around it, an operation that helps identify edges. Figure 6 shows an image on the left, a 3×3 kernel in the middle, and the results of applying the kernel to the top-left pixel on the right. We can also define multiple kernels, representing different feature maps.
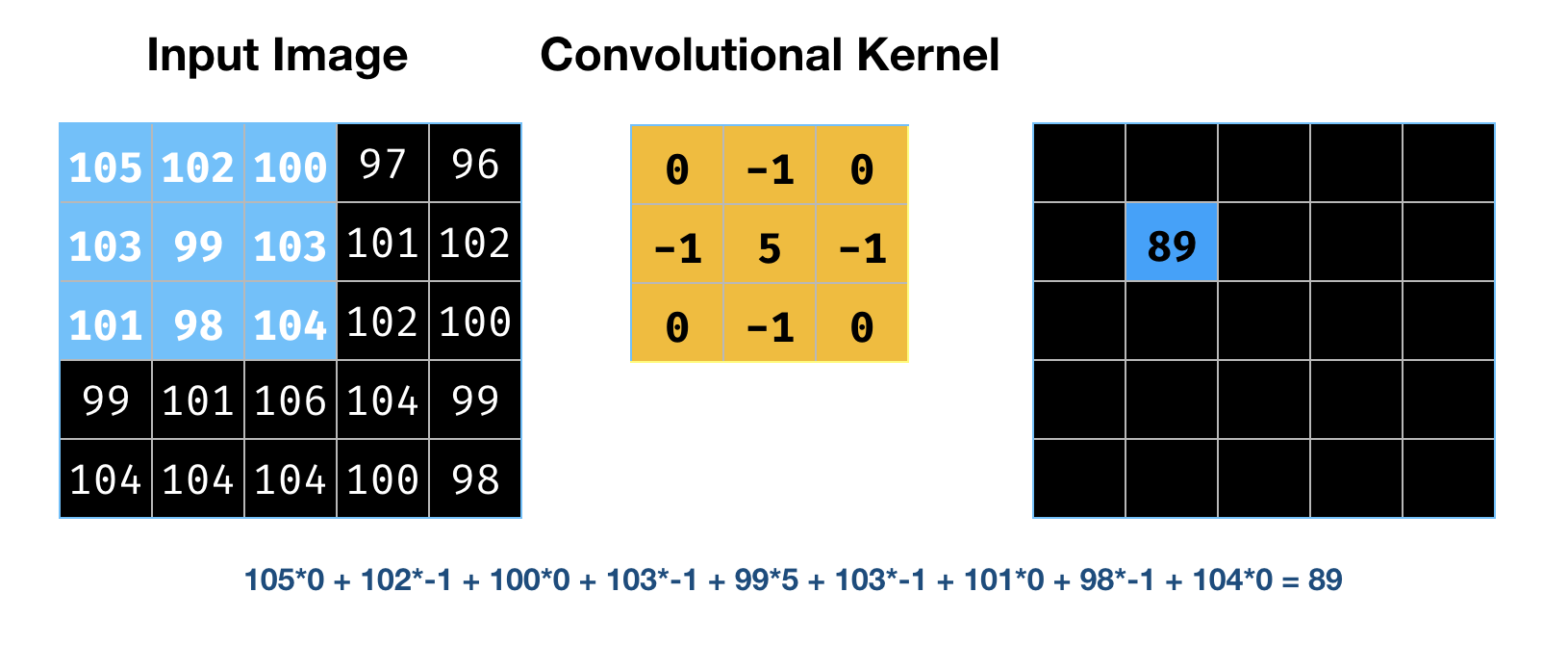
In the example in Figure 6, the input image was 5×5 and the kernel was 3×3. The computation was an element-wise multplication between the two matrices. The output was 5×5.
To understand this, we need to understand two parameters at the convolution layer: stride and padding.
Stride controls how the kernel (filter) moves along the image.
Figure 7 illustrates the movement of the kernel from the first pixel to the second.
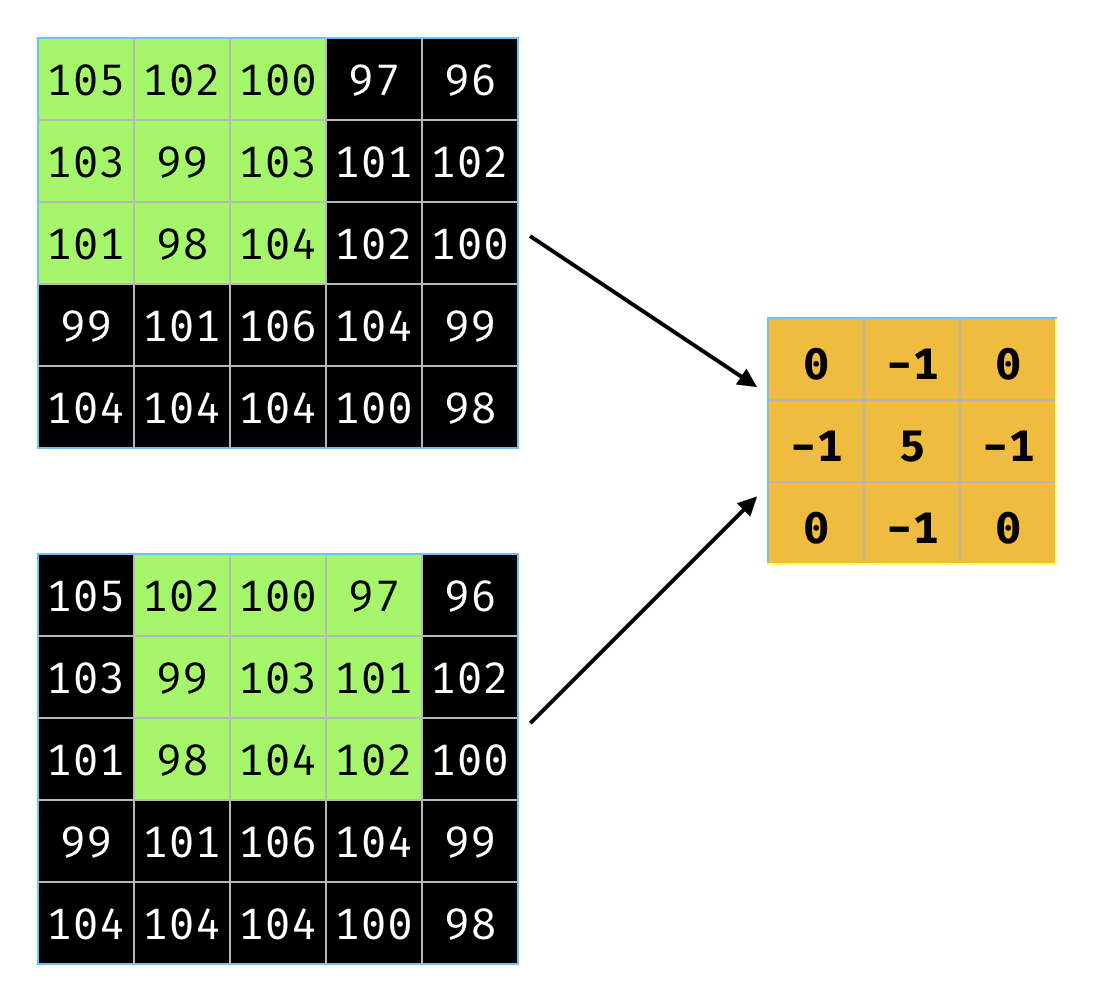
In the Figure 7, the stride is 1.
When a 5×5 image is convolved with a 3×3 kernel, we will be getting a 3×3 image. Consider the case where we add a zero padding around the image. The 5×5 image is now surrounded with 0. This is illustrated in Figure 8.
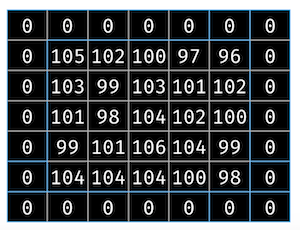
This, when multipled by a 3×3 kernel, will result in a 5×5 output.
So, for the computation shown in Figure 6, it had a stride of 1 and padding of size 1.
CNN works with drastically fewer weights than the corresponding MLP. Say we use 30 kernels, each with 3×3 elements. Each kernel has 3×3 = 9 + 1 (for bias) parameters. This leads to 10 weights per kernel, 300 for 30 kernels. Contraste this against the 150,000 weights for the MLP in the previous section.
The next layer is typically a sub-sampling layer. Once we have identified the features, this sub-sampling layer simplifies the information. A common method is max pooling, which outputs the greatest value from each localized region of the output from the convolutional layer (see Figure 9). It reduces the output size, while preserving the maximum activation in every localized region.
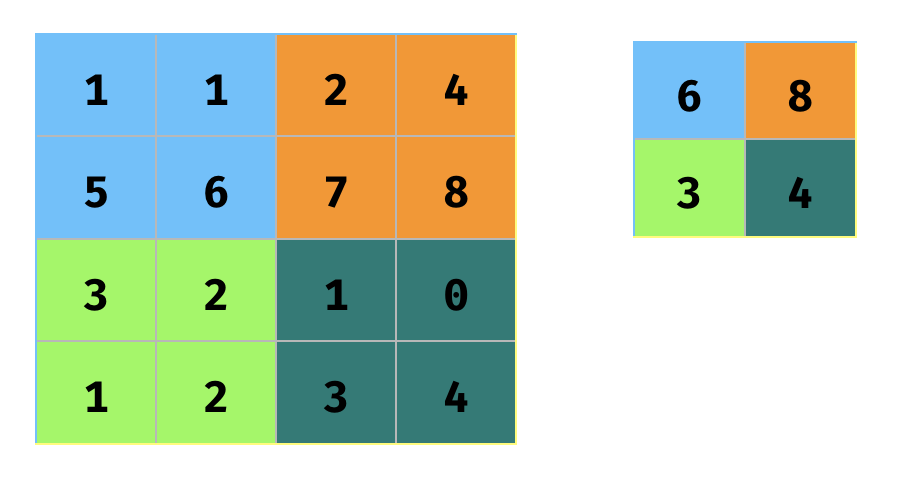
You can see that it reduces the output size, while preserving the maximum activation in every localized region.
A good resource for more information on CNNs is the online book, Neural Networks and Deep Learning. Another good resource is Stanford University’s CNN course
Now that we have learned the basics of what CNN is, let’s go and implement it for our problem using gluon.
The first step is to define the architecture:
cnn_net=mx.gluon.nn.Sequential()withcnn_net.name_scope():# First convolutional layercnn_net.add(mx.gluon.nn.Conv2D(channels=96,kernel_size=11,strides=(4,4),activation='relu'))cnn_net.add(mx.gluon.nn.MaxPool2D(pool_size=3,strides=2))# Second convolutional layercnn_net.add(mx.gluon.nn.Conv2D(channels=192,kernel_size=5,activation='relu'))cnn_net.add(mx.gluon.nn.MaxPool2D(pool_size=3,strides=(2,2)))# Flatten and apply fullly connected layerscnn_net.add(mx.gluon.nn.Flatten())cnn_net.add(mx.gluon.nn.Dense(4096,activation="relu"))cnn_net.add(mx.gluon.nn.Dense(num_classes))
Now that the model architecture is defined, let’s initialize the weights of the network. We will use the Xavier initalizer.
cnn_net.collect_params().initialize(mx.init.Xavier(magnitude=2.24),ctx=ctx)
Once the weights are initialized, we can train the model. We will call the same train function defined earlier and pass the required parameters for the function.
train(cnn_net,ctx,train_data,val_data,test_data,batch_size,num_epochs,model_prefix='cnn')
Epoch 0. Loss: 53.771, Train acc 0.77, Val acc 0.58, Test acc 0.72, Time 224.9 sec
Best validation accuracy found. Checkpointing...
Epoch 1. Loss: 3.417, Train acc 0.80, Val acc 0.60, Test acc 0.73, Time 222.7 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 2. Loss: 3.333, Train acc 0.81, Val acc 0.60, Test acc 0.74, Time 222.5 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 3. Loss: 3.227, Train acc 0.82, Val acc 0.61, Test acc 0.75, Time 222.4 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 4. Loss: 3.079, Train acc 0.82, Val acc 0.61, Test acc 0.75, Time 222.0 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 5. Loss: 2.850, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 222.7 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 6. Loss: 2.488, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 222.1 sec
Epoch 7. Loss: 1.943, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 8. Loss: 1.395, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 223.6 sec
Epoch 9. Loss: 1.146, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 222.5 sec
Epoch 10. Loss: 1.089, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.5 sec
Epoch 11. Loss: 1.078, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 220.7 sec
Epoch 12. Loss: 1.078, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.1 sec
Epoch 13. Loss: 1.075, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 14. Loss: 1.076, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 15. Loss: 1.076, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 220.4 sec
Epoch 16. Loss: 1.075, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.3 sec
Epoch 17. Loss: 1.074, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.8 sec
Epoch 18. Loss: 1.074, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 221.8 sec
Epoch 19. Loss: 1.073, Train acc 0.82, Val acc 0.61, Test acc 0.76, Time 220.9 sec
We asked the model to run for 20 epochs. Typically, we train for many epochs and pick the model at the epoch where the validation accuracy is the highest. Here, after 20 epochs, we can see from the log just shown that the model’s best validation accuracy was in epoch 5. After that, the model doesn’t seem to have learned much. Probably, the network was saturated and learning took place very slowly. We’ll try out a better approach in the next section, but first we’ll see how our current model performs.
Collect the parameters of the epoch that had the best validation accuracy and assign it as our model parameters:
cnn_net.collect_params().load('cnn-%d.params'%(5),ctx)
Let’s now check how the model performs on new data. We’ll get an easy-to-recognize images from the Web (Figure 10) and see the model’s accuracy.
img_url="http://sophieswift.com/wp-content/uploads/2017/09/pleasing-ideas-bmw-cake-and-satisfying-some-bmw-themed-cakes-crustncakes-delicious-cakes-128x128.jpg"classify_logo(cnn_net,img_url)
'With prob=0.081522, no-logo'

The model’s prediction has been terrible. It predicts the image to have no logo with probability of 8%. The prediction is wrong and the probability is quite weak.
Let’s try one more test image (see Figure 11) to see whether accuracy is any better.
img_url="https://dtgxwmigmg3gc.cloudfront.net/files/59cdcd6f52ba0b36b5024500-icon-256x256.png"classify_logo(cnn_net,img_url)
'With prob=0.075301, no-logo'

Yet again, the model’s prediction is wrong and the probability is quite weak.
We don’t have much data, and the model training has saturated, as just seen. We can experiment with more model architectures, but we won’t overcome the problems of small data sets and trainable parameters much greater than the number of training images. So, how do we get around this problem? Can’t deep learning be used if there isn’t much data?
The answer to that is transfer learning, discussed next.
Transfer learning
Consider this analogy: you want to pick up a new foreign language. How does the learning happen?
You would take a conversation, say, for example:
Instructor: How are you doing?
You: I am good. How about you?
And you will try to learn the equivalent of this in the new language.
Because of your proficiency in English, you don’t start learning a new language from scratch (even if it seems that you do). You already have the mental map of a language, and you try to find the corresponding words in the new language. Therefore, in the new language, while your vocabulary might still be limited, you will still be able to converse because of your knowledge of the structure of conversations in English.
Transfer learning works the same way. Highly accurate models are built on data sets where a lot of data is available. A common data set that you will come across is the ImageNet data. It has more than a million images. Researchers from around the world have built many different state-of-art models using this data. The resulting model, comprised of model architecture and weights, is freely available on the internet.
And starting from that pre-trained model, we will train the model for our problem. In fact, this is quite the norm. Almost invariably, the first model one would build for a computer vision problem would employ a pre-trained model.
In many cases, like our example, this might be all one can do—if restricted for data.
The typical practice is to keep many of the early layers fixed, and train only the last layers. If data is quite limited, only the classifier layer is re-trained. If data is moderately abundant, the last few layers are re-trained.
This works because a convolutional neural network learns higher level representation at each successive layer; the learning it has done at many of the early layers is held in common by all image classification problems.
Let’s now use a pre-trained model for logo detection.
MXNet has a model zoo with a number of pre-trained models.
We will use a popular pre-trained model called resnet. The paper provides a lot of details on the model structure. A simpler explanation can be found in this article.
Let’s first download the pre-trained model:
frommxnet.gluon.model_zooimportvisionasmodelspretrained_net=models.resnet18_v2(pretrained=True)
Since our data set is small, we will re-train only the output layer. We randomly initialize the weights for the output layer:
finetune_net=models.resnet18_v2(classes=num_classes)finetune_net.features=pretrained_net.featuresfinetune_net.output.initialize(mx.init.Xavier(magnitude=2.24))
We now call the same train function as before:
train(finetune_net,ctx,train_data,val_data,test_data,batch_size,num_epochs,model_prefix='ft',hybridize=True)
Epoch 0. Loss: 1.107, Train acc 0.83, Val acc 0.62, Test acc 0.76, Time 246.1 sec
Best validation accuracy found. Checkpointing...
Epoch 1. Loss: 0.811, Train acc 0.85, Val acc 0.62, Test acc 0.77, Time 243.7 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 2. Loss: 0.722, Train acc 0.86, Val acc 0.64, Test acc 0.78, Time 245.3 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 3. Loss: 0.660, Train acc 0.87, Val acc 0.66, Test acc 0.79, Time 243.4 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 4. Loss: 0.541, Train acc 0.88, Val acc 0.67, Test acc 0.80, Time 244.5 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 5. Loss: 0.528, Train acc 0.89, Val acc 0.68, Test acc 0.80, Time 243.4 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 6. Loss: 0.490, Train acc 0.90, Val acc 0.68, Test acc 0.81, Time 243.2 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 7. Loss: 0.453, Train acc 0.91, Val acc 0.71, Test acc 0.82, Time 243.6 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 8. Loss: 0.435, Train acc 0.92, Val acc 0.70, Test acc 0.82, Time 245.6 sec
Epoch 9. Loss: 0.413, Train acc 0.92, Val acc 0.72, Test acc 0.82, Time 247.7 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 10. Loss: 0.392, Train acc 0.92, Val acc 0.72, Test acc 0.83, Time 245.3 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 11. Loss: 0.377, Train acc 0.92, Val acc 0.72, Test acc 0.83, Time 244.5 sec
Epoch 12. Loss: 0.335, Train acc 0.93, Val acc 0.72, Test acc 0.84, Time 244.2 sec
Epoch 13. Loss: 0.321, Train acc 0.94, Val acc 0.73, Test acc 0.84, Time 245.0 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 14. Loss: 0.305, Train acc 0.93, Val acc 0.73, Test acc 0.84, Time 243.4 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 15. Loss: 0.298, Train acc 0.93, Val acc 0.73, Test acc 0.84, Time 243.9 sec
Epoch 16. Loss: 0.296, Train acc 0.94, Val acc 0.75, Test acc 0.84, Time 247.0 sec
Deleting previous checkpoint...
Best validation accuracy found. Checkpointing...
Epoch 17. Loss: 0.274, Train acc 0.94, Val acc 0.74, Test acc 0.84, Time 245.1 sec
Epoch 18. Loss: 0.292, Train acc 0.94, Val acc 0.74, Test acc 0.84, Time 243.9 sec
Epoch 19. Loss: 0.306, Train acc 0.95, Val acc 0.73, Test acc 0.84, Time 244.8 sec
The model starts right away with a higher accuracy. Typically, when data is less, we train only for a few epochs and pick the model at the epoch where the validation accuracy is the highest.
Here, epoch 16 has the best validation accuracy. Since the training data is limited, and the model kept on training, it has started to overfit. We can see that after epoch 16, while training accuracy is increasing, validation accuracy has begun to decrease.
Let’s collect the parameters from the corresponding checkpoint of the 16th epoch and use it as the final model.
# The model's parameters are now set to the values at the 16th epochfinetune_net.collect_params().load('ft-%d.params'%(16),ctx)
Evaluating the predictions
For the same images that we used earlier to evaluate the predictions, let’s see the prediction of the new model.
img_url="http://sophieswift.com/wp-content/uploads/2017/09/pleasing-ideas-bmw-cake-and-satisfying-some-bmw-themed-cakes-crustncakes-delicious-cakes-128x128.jpg"classify_logo(finetune_net,img_url)
'With prob=0.983476, bmw'

We can see that the model is able to predict BMW with 98% probability.
Let’s now try the other image we tested earlier.
img_url="https://dtgxwmigmg3gc.cloudfront.net/files/59cdcd6f52ba0b36b5024500-icon-256x256.png"classify_logo(finetune_net,img_url)
'With prob=0.498218, fosters'
While the prediction probability isn’t good, a tad lower than 50%, Foster’s still gets the highest probability amongst all the logos.
Improving the model
To improve the model, we need to fix the way we constructed the training data set. Each individual logo had 10 training points. But as part of distributing the no-logo images from validation to training, we moved 1,500 images to training as no logo. This introduces a significant data set bias. This is not a good practice. The following are some options to fix this:
- Weight the cross-entroy loss.
- Don’t include the no-logo images in the training data set. Build a model that predicts low class probabilities to all logos if it doesn’t exist in test/validation images.
But remember, that even with transfer learning and data augmentation, we only have 320 images, and this is quite low to build highly accurate deep learning models.
Conclusion
In this article, we learned how to build image recognition models using MXNet. Gluon is ideal for rapid prototyping. Moving from prototyping to production is also quite easy with hybridization and symbol export. With a host of pre-trained models available on MXNet, we were able to get very good models for logo detection in pretty quick time. A very good resource for learning more about the underying theory is the Stanford’s CS231n course.